 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Hallucination Detection in Neural Machine Translation through Simple Detector Aggregation
Feb 20, 2024Hallucinated translations pose significant threats and safety concerns when it comes to the practical deployment of machine translation systems. Previous research works have identified that detectors exhibit complementary performance different detectors excel at detecting different types of hallucinations. In this paper, we propose to address the limitations of individual detectors by combining them and introducing a straightforward method for aggregating multiple detectors. Our results demonstrate the efficacy of our aggregated detector, providing a promising step towards evermore reliable machine translation systems.
Toward Stronger Textual Attack Detectors
Oct 21, 2023



The landscape of available textual adversarial attacks keeps growing, posing severe threats and raising concerns regarding the deep NLP system's integrity. However, the crucial problem of defending against malicious attacks has only drawn the attention of the NLP community. The latter is nonetheless instrumental in developing robust and trustworthy systems. This paper makes two important contributions in this line of search: (i) we introduce LAROUSSE, a new framework to detect textual adversarial attacks and (ii) we introduce STAKEOUT, a new benchmark composed of nine popular attack methods, three datasets, and two pre-trained models. LAROUSSE is ready-to-use in production as it is unsupervised, hyperparameter-free, and non-differentiable, protecting it against gradient-based methods. Our new benchmark STAKEOUT allows for a robust evaluation framework: we conduct extensive numerical experiments which demonstrate that LAROUSSE outperforms previous methods, and which allows to identify interesting factors of detection rate variations.
MEAD: A Multi-Armed Approach for Evaluation of Adversarial Examples Detectors
Jun 30, 2022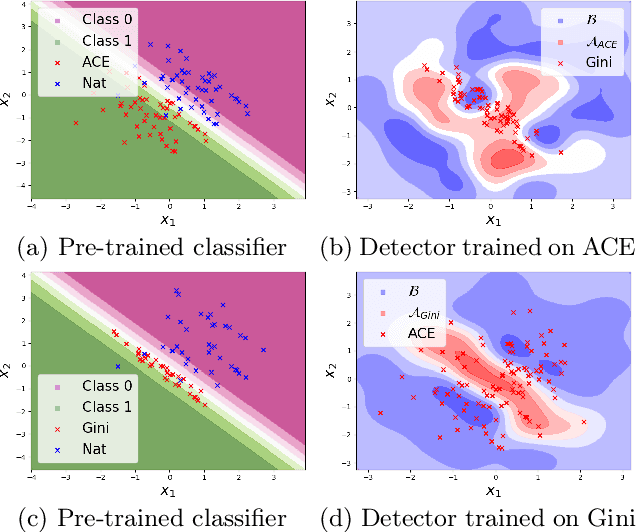
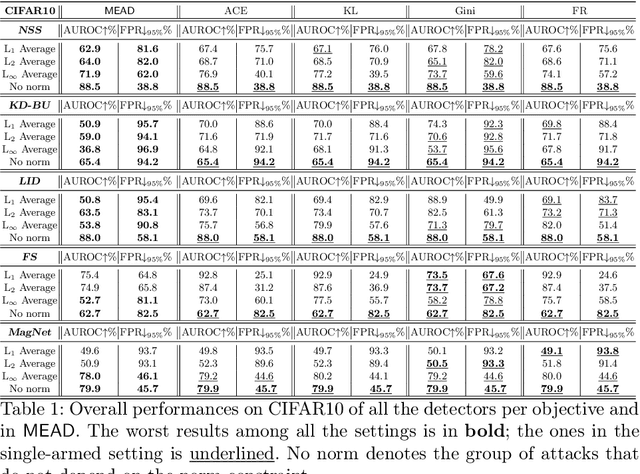
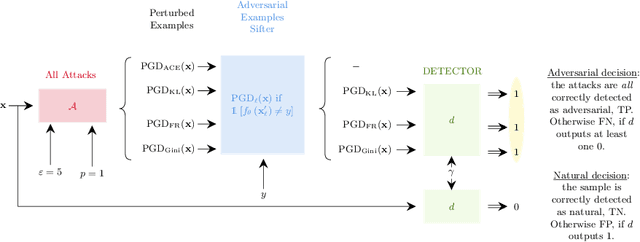
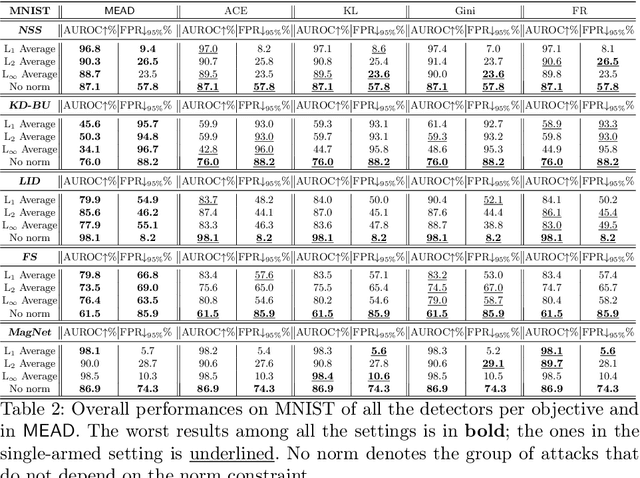
Detection of adversarial examples has been a hot topic in the last years due to its importance for safely deploying machine learning algorithms in critical applications. However, the detection methods are generally validated by assuming a single implicitly known attack strategy, which does not necessarily account for real-life threats. Indeed, this can lead to an overoptimistic assessment of the detectors' performance and may induce some bias in the comparison between competing detection schemes. We propose a novel multi-armed framework, called MEAD, for evaluating detectors based on several attack strategies to overcome this limitation. Among them, we make use of three new objectives to generate attacks. The proposed performance metric is based on the worst-case scenario: detection is successful if and only if all different attacks are correctly recognized. Empirically, we show the effectiveness of our approach. Moreover, the poor performance obtained for state-of-the-art detectors opens a new exciting line of research.
Adversarial Robustness via Fisher-Rao Regularization
Jun 12, 2021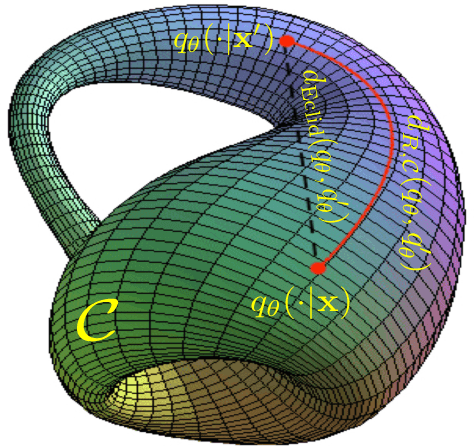
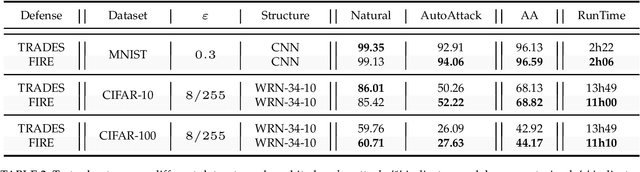
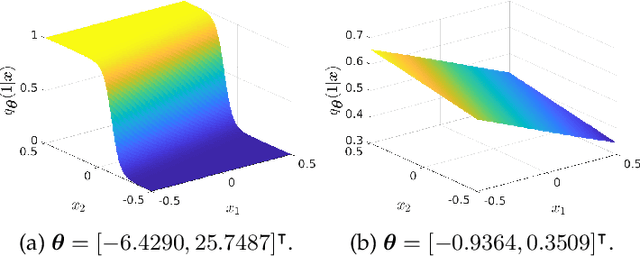
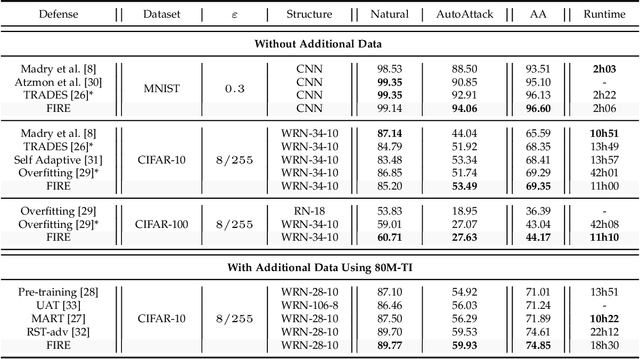
Adversarial robustness has become a topic of growing interest in machine learning since it was observed that neural networks tend to be brittle. We propose an information-geometric formulation of adversarial defense and introduce FIRE, a new Fisher-Rao regularization for the categorical cross-entropy loss, which is based on the geodesic distance between natural and perturbed input features. Based on the information-geometric properties of the class of softmax distributions, we derive an explicit characterization of the Fisher-Rao Distance (FRD) for the binary and multiclass cases, and draw some interesting properties as well as connections with standard regularization metrics. Furthermore, for a simple linear and Gaussian model, we show that all Pareto-optimal points in the accuracy-robustness region can be reached by FIRE while other state-of-the-art methods fail. Empirically, we evaluate the performance of various classifiers trained with the proposed loss on standard datasets, showing up to 2\% of improvements in terms of robustness while reducing the training time by 20\% over the best-performing methods.