 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnmixing Noise from Hawkes Process to Model Learned Physiological Events
Jun 17, 2024


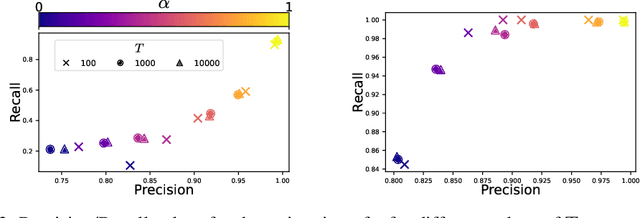
Physiological signal analysis often involves identifying events crucial to understanding biological dynamics. Traditional methods rely on handcrafted procedures or supervised learning, presenting challenges such as expert dependence, lack of robustness, and the need for extensive labeled data. Data-driven methods like Convolutional Dictionary Learning (CDL) offer an alternative but tend to produce spurious detections. This work introduces UNHaP (Unmix Noise from Hawkes Processes), a novel approach addressing the joint learning of temporal structures in events and the removal of spurious detections. Leveraging marked Hawkes processes, UNHaP distinguishes between events of interest and spurious ones. By treating the event detection output as a mixture of structured and unstructured events, UNHaP efficiently unmixes these processes and estimates their parameters. This approach significantly enhances the understanding of event distributions while minimizing false detection rates.
Flexible Parametric Inference for Space-Time Hawkes Processes
Jun 10, 2024

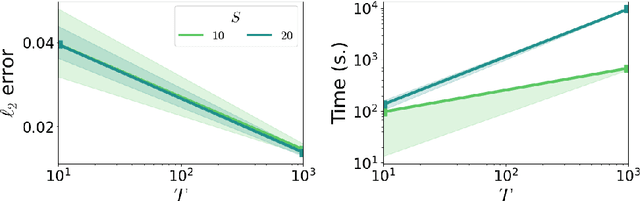

Many modern spatio-temporal data sets, in sociology, epidemiology or seismology, for example, exhibit self-exciting characteristics, triggering and clustering behaviors both at the same time, that a suitable Hawkes space-time process can accurately capture. This paper aims to develop a fast and flexible parametric inference technique to recover the parameters of the kernel functions involved in the intensity function of a space-time Hawkes process based on such data. Our statistical approach combines three key ingredients: 1) kernels with finite support are considered, 2) the space-time domain is appropriately discretized, and 3) (approximate) precomputations are used. The inference technique we propose then consists of a $\ell_2$ gradient-based solver that is fast and statistically accurate. In addition to describing the algorithmic aspects, numerical experiments have been carried out on synthetic and real spatio-temporal data, providing solid empirical evidence of the relevance of the proposed methodology.
Signature Isolation Forest
Mar 07, 2024Functional Isolation Forest (FIF) is a recent state-of-the-art Anomaly Detection (AD) algorithm designed for functional data. It relies on a tree partition procedure where an abnormality score is computed by projecting each curve observation on a drawn dictionary through a linear inner product. Such linear inner product and the dictionary are a priori choices that highly influence the algorithm's performances and might lead to unreliable results, particularly with complex datasets. This work addresses these challenges by introducing \textit{Signature Isolation Forest}, a novel AD algorithm class leveraging the rough path theory's signature transform. Our objective is to remove the constraints imposed by FIF through the proposition of two algorithms which specifically target the linearity of the FIF inner product and the choice of the dictionary. We provide several numerical experiments, including a real-world applications benchmark showing the relevance of our methods.
Enhanced Hallucination Detection in Neural Machine Translation through Simple Detector Aggregation
Feb 20, 2024Hallucinated translations pose significant threats and safety concerns when it comes to the practical deployment of machine translation systems. Previous research works have identified that detectors exhibit complementary performance different detectors excel at detecting different types of hallucinations. In this paper, we propose to address the limitations of individual detectors by combining them and introducing a straightforward method for aggregating multiple detectors. Our results demonstrate the efficacy of our aggregated detector, providing a promising step towards evermore reliable machine translation systems.
A Novel Information-Theoretic Objective to Disentangle Representations for Fair Classification
Oct 21, 2023



One of the pursued objectives of deep learning is to provide tools that learn abstract representations of reality from the observation of multiple contextual situations. More precisely, one wishes to extract disentangled representations which are (i) low dimensional and (ii) whose components are independent and correspond to concepts capturing the essence of the objects under consideration (Locatello et al., 2019b). One step towards this ambitious project consists in learning disentangled representations with respect to a predefined (sensitive) attribute, e.g., the gender or age of the writer. Perhaps one of the main application for such disentangled representations is fair classification. Existing methods extract the last layer of a neural network trained with a loss that is composed of a cross-entropy objective and a disentanglement regularizer. In this work, we adopt an information-theoretic view of this problem which motivates a novel family of regularizers that minimizes the mutual information between the latent representation and the sensitive attribute conditional to the target. The resulting set of losses, called CLINIC, is parameter free and thus, it is easier and faster to train. CLINIC losses are studied through extensive numerical experiments by training over 2k neural networks. We demonstrate that our methods offer a better disentanglement/accuracy trade-off than previous techniques, and generalize better than training with cross-entropy loss solely provided that the disentanglement task is not too constraining.
Toward Stronger Textual Attack Detectors
Oct 21, 2023



The landscape of available textual adversarial attacks keeps growing, posing severe threats and raising concerns regarding the deep NLP system's integrity. However, the crucial problem of defending against malicious attacks has only drawn the attention of the NLP community. The latter is nonetheless instrumental in developing robust and trustworthy systems. This paper makes two important contributions in this line of search: (i) we introduce LAROUSSE, a new framework to detect textual adversarial attacks and (ii) we introduce STAKEOUT, a new benchmark composed of nine popular attack methods, three datasets, and two pre-trained models. LAROUSSE is ready-to-use in production as it is unsupervised, hyperparameter-free, and non-differentiable, protecting it against gradient-based methods. Our new benchmark STAKEOUT allows for a robust evaluation framework: we conduct extensive numerical experiments which demonstrate that LAROUSSE outperforms previous methods, and which allows to identify interesting factors of detection rate variations.
A Functional Data Perspective and Baseline On Multi-Layer Out-of-Distribution Detection
Jun 06, 2023A key feature of out-of-distribution (OOD) detection is to exploit a trained neural network by extracting statistical patterns and relationships through the multi-layer classifier to detect shifts in the expected input data distribution. Despite achieving solid results, several state-of-the-art methods rely on the penultimate or last layer outputs only, leaving behind valuable information for OOD detection. Methods that explore the multiple layers either require a special architecture or a supervised objective to do so. This work adopts an original approach based on a functional view of the network that exploits the sample's trajectories through the various layers and their statistical dependencies. It goes beyond multivariate features aggregation and introduces a baseline rooted in functional anomaly detection. In this new framework, OOD detection translates into detecting samples whose trajectories differ from the typical behavior characterized by the training set. We validate our method and empirically demonstrate its effectiveness in OOD detection compared to strong state-of-the-art baselines on computer vision benchmarks.
Hypothesis Transfer Learning with Surrogate Classification Losses
May 31, 2023Hypothesis transfer learning (HTL) contrasts domain adaptation by allowing for a previous task leverage, named the source, into a new one, the target, without requiring access to the source data. Indeed, HTL relies only on a hypothesis learnt from such source data, relieving the hurdle of expansive data storage and providing great practical benefits. Hence, HTL is highly beneficial for real-world applications relying on big data. The analysis of such a method from a theoretical perspective faces multiple challenges, particularly in classification tasks. This paper deals with this problem by studying the learning theory of HTL through algorithmic stability, an attractive theoretical framework for machine learning algorithms analysis. In particular, we are interested in the statistical behaviour of the regularized empirical risk minimizers in the case of binary classification. Our stability analysis provides learning guarantees under mild assumptions. Consequently, we derive several complexity-free generalization bounds for essential statistical quantities like the training error, the excess risk and cross-validation estimates. These refined bounds allow understanding the benefits of transfer learning and comparing the behaviour of standard losses in different scenarios, leading to valuable insights for practitioners.
Unsupervised Layer-wise Score Aggregation for Textual OOD Detection
Feb 20, 2023



Out-of-distribution (OOD) detection is a rapidly growing field due to new robustness and security requirements driven by an increased number of AI-based systems. Existing OOD textual detectors often rely on an anomaly score (e.g., Mahalanobis distance) computed on the embedding output of the last layer of the encoder. In this work, we observe that OOD detection performance varies greatly depending on the task and layer output. More importantly, we show that the usual choice (the last layer) is rarely the best one for OOD detection and that far better results could be achieved if the best layer were picked. To leverage this observation, we propose a data-driven, unsupervised method to combine layer-wise anomaly scores. In addition, we extend classical textual OOD benchmarks by including classification tasks with a greater number of classes (up to 77), which reflects more realistic settings. On this augmented benchmark, we show that the proposed post-aggregation methods achieve robust and consistent results while removing manual feature selection altogether. Their performance achieves near oracle's best layer performance.
Beyond Mahalanobis-Based Scores for Textual OOD Detection
Nov 24, 2022Deep learning methods have boosted the adoption of NLP systems in real-life applications. However, they turn out to be vulnerable to distribution shifts over time which may cause severe dysfunctions in production systems, urging practitioners to develop tools to detect out-of-distribution (OOD) samples through the lens of the neural network. In this paper, we introduce TRUSTED, a new OOD detector for classifiers based on Transformer architectures that meets operational requirements: it is unsupervised and fast to compute. The efficiency of TRUSTED relies on the fruitful idea that all hidden layers carry relevant information to detect OOD examples. Based on this, for a given input, TRUSTED consists in (i) aggregating this information and (ii) computing a similarity score by exploiting the training distribution, leveraging the powerful concept of data depth. Our extensive numerical experiments involve 51k model configurations, including various checkpoints, seeds, and datasets, and demonstrate that TRUSTED achieves state-of-the-art performances. In particular, it improves previous AUROC over 3 points.