 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIMILIA: interpretable multiple instance learning for inflammation prediction in IBD from H&E whole slide images
Dec 15, 2025As the therapeutic target for Inflammatory Bowel Disease (IBD) shifts toward histologic remission, the accurate assessment of microscopic inflammation has become increasingly central for evaluating disease activity and response to treatment. In this work, we introduce IMILIA (Interpretable Multiple Instance Learning for Inflammation Analysis), an end-to-end framework designed for the prediction of inflammation presence in IBD digitized slides stained with hematoxylin and eosin (H&E), followed by the automated computation of markers characterizing tissue regions driving the predictions. IMILIA is composed of an inflammation prediction module, consisting of a Multiple Instance Learning (MIL) model, and an interpretability module, divided in two blocks: HistoPLUS, for cell instance detection, segmentation and classification; and EpiSeg, for epithelium segmentation. IMILIA achieves a cross-validation ROC-AUC of 0.83 on the discovery cohort, and a ROC-AUC of 0.99 and 0.84 on two external validation cohorts. The interpretability module yields biologically consistent insights: tiles with higher predicted scores show increased densities of immune cells (lymphocytes, plasmocytes, neutrophils and eosinophils), whereas lower-scored tiles predominantly contain normal epithelial cells. Notably, these patterns were consistent across all datasets. Code and models to partially replicate the results on the public IBDColEpi dataset can be found at https://github.com/owkin/imilia.
Subgroup analysis methods for time-to-event outcomes in heterogeneous randomized controlled trials
Jan 23, 2024Non-significant randomized control trials can hide subgroups of good responders to experimental drugs, thus hindering subsequent development. Identifying such heterogeneous treatment effects is key for precision medicine and many post-hoc analysis methods have been developed for that purpose. While several benchmarks have been carried out to identify the strengths and weaknesses of these methods, notably for binary and continuous endpoints, similar systematic empirical evaluation of subgroup analysis for time-to-event endpoints are lacking. This work aims to fill this gap by evaluating several subgroup analysis algorithms in the context of time-to-event outcomes, by means of three different research questions: Is there heterogeneity? What are the biomarkers responsible for such heterogeneity? Who are the good responders to treatment? In this context, we propose a new synthetic and semi-synthetic data generation process that allows one to explore a wide range of heterogeneity scenarios with precise control on the level of heterogeneity. We provide an open source Python package, available on Github, containing our generation process and our comprehensive benchmark framework. We hope this package will be useful to the research community for future investigations of heterogeneity of treatment effects and subgroup analysis methods benchmarking.
Toward Stronger Textual Attack Detectors
Oct 21, 2023



The landscape of available textual adversarial attacks keeps growing, posing severe threats and raising concerns regarding the deep NLP system's integrity. However, the crucial problem of defending against malicious attacks has only drawn the attention of the NLP community. The latter is nonetheless instrumental in developing robust and trustworthy systems. This paper makes two important contributions in this line of search: (i) we introduce LAROUSSE, a new framework to detect textual adversarial attacks and (ii) we introduce STAKEOUT, a new benchmark composed of nine popular attack methods, three datasets, and two pre-trained models. LAROUSSE is ready-to-use in production as it is unsupervised, hyperparameter-free, and non-differentiable, protecting it against gradient-based methods. Our new benchmark STAKEOUT allows for a robust evaluation framework: we conduct extensive numerical experiments which demonstrate that LAROUSSE outperforms previous methods, and which allows to identify interesting factors of detection rate variations.
A Novel Information-Theoretic Objective to Disentangle Representations for Fair Classification
Oct 21, 2023



One of the pursued objectives of deep learning is to provide tools that learn abstract representations of reality from the observation of multiple contextual situations. More precisely, one wishes to extract disentangled representations which are (i) low dimensional and (ii) whose components are independent and correspond to concepts capturing the essence of the objects under consideration (Locatello et al., 2019b). One step towards this ambitious project consists in learning disentangled representations with respect to a predefined (sensitive) attribute, e.g., the gender or age of the writer. Perhaps one of the main application for such disentangled representations is fair classification. Existing methods extract the last layer of a neural network trained with a loss that is composed of a cross-entropy objective and a disentanglement regularizer. In this work, we adopt an information-theoretic view of this problem which motivates a novel family of regularizers that minimizes the mutual information between the latent representation and the sensitive attribute conditional to the target. The resulting set of losses, called CLINIC, is parameter free and thus, it is easier and faster to train. CLINIC losses are studied through extensive numerical experiments by training over 2k neural networks. We demonstrate that our methods offer a better disentanglement/accuracy trade-off than previous techniques, and generalize better than training with cross-entropy loss solely provided that the disentanglement task is not too constraining.
A Functional Data Perspective and Baseline On Multi-Layer Out-of-Distribution Detection
Jun 06, 2023A key feature of out-of-distribution (OOD) detection is to exploit a trained neural network by extracting statistical patterns and relationships through the multi-layer classifier to detect shifts in the expected input data distribution. Despite achieving solid results, several state-of-the-art methods rely on the penultimate or last layer outputs only, leaving behind valuable information for OOD detection. Methods that explore the multiple layers either require a special architecture or a supervised objective to do so. This work adopts an original approach based on a functional view of the network that exploits the sample's trajectories through the various layers and their statistical dependencies. It goes beyond multivariate features aggregation and introduces a baseline rooted in functional anomaly detection. In this new framework, OOD detection translates into detecting samples whose trajectories differ from the typical behavior characterized by the training set. We validate our method and empirically demonstrate its effectiveness in OOD detection compared to strong state-of-the-art baselines on computer vision benchmarks.
Towards More Robust NLP System Evaluation: Handling Missing Scores in Benchmarks
May 17, 2023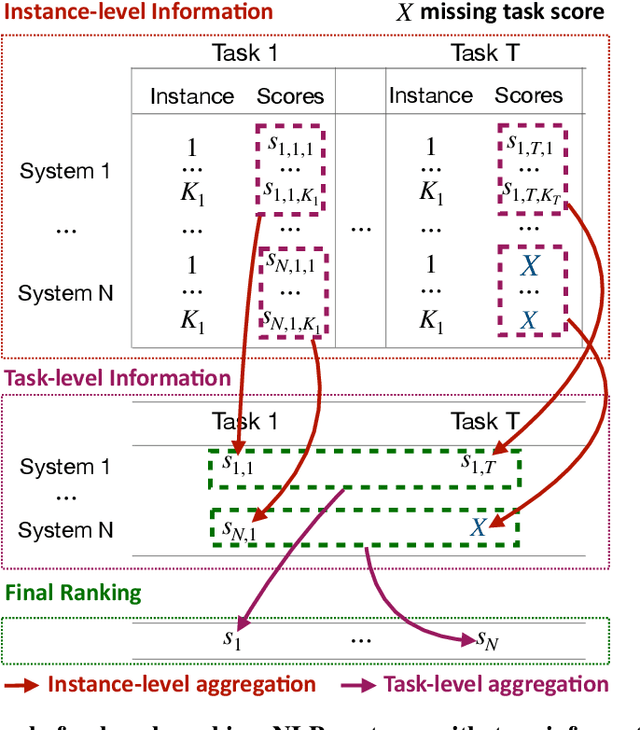
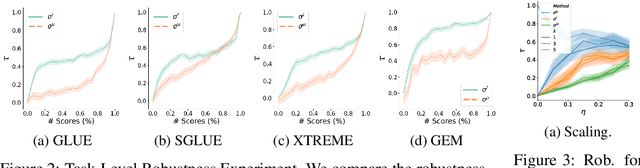

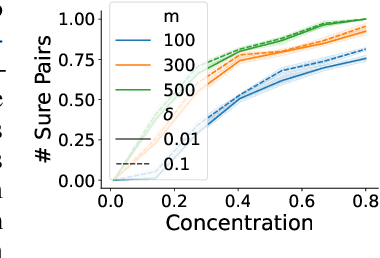
The evaluation of natural language processing (NLP) systems is crucial for advancing the field, but current benchmarking approaches often assume that all systems have scores available for all tasks, which is not always practical. In reality, several factors such as the cost of running baseline, private systems, computational limitations, or incomplete data may prevent some systems from being evaluated on entire tasks. This paper formalize an existing problem in NLP research: benchmarking when some systems scores are missing on the task, and proposes a novel approach to address it. Our method utilizes a compatible partial ranking approach to impute missing data, which is then aggregated using the Borda count method. It includes two refinements designed specifically for scenarios where either task-level or instance-level scores are available. We also introduce an extended benchmark, which contains over 131 million scores, an order of magnitude larger than existing benchmarks. We validate our methods and demonstrate their effectiveness in addressing the challenge of missing system evaluation on an entire task. This work highlights the need for more comprehensive benchmarking approaches that can handle real-world scenarios where not all systems are evaluated on the entire task.
Beyond Mahalanobis-Based Scores for Textual OOD Detection
Nov 24, 2022Deep learning methods have boosted the adoption of NLP systems in real-life applications. However, they turn out to be vulnerable to distribution shifts over time which may cause severe dysfunctions in production systems, urging practitioners to develop tools to detect out-of-distribution (OOD) samples through the lens of the neural network. In this paper, we introduce TRUSTED, a new OOD detector for classifiers based on Transformer architectures that meets operational requirements: it is unsupervised and fast to compute. The efficiency of TRUSTED relies on the fruitful idea that all hidden layers carry relevant information to detect OOD examples. Based on this, for a given input, TRUSTED consists in (i) aggregating this information and (ii) computing a similarity score by exploiting the training distribution, leveraging the powerful concept of data depth. Our extensive numerical experiments involve 51k model configurations, including various checkpoints, seeds, and datasets, and demonstrate that TRUSTED achieves state-of-the-art performances. In particular, it improves previous AUROC over 3 points.
Mitigating Gender Bias in Face Recognition Using the von Mises-Fisher Mixture Model
Oct 24, 2022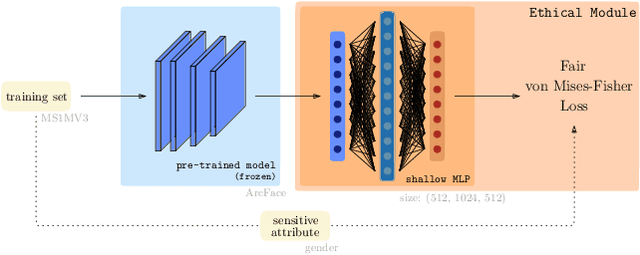

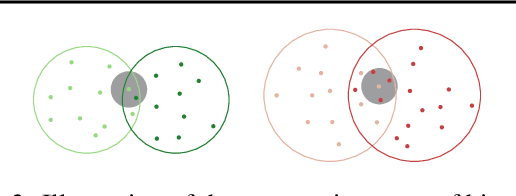
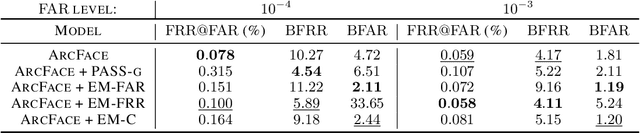
In spite of the high performance and reliability of deep learning algorithms in a wide range of everyday applications, many investigations tend to show that a lot of models exhibit biases, discriminating against specific subgroups of the population (e.g. gender, ethnicity). This urges the practitioner to develop fair systems with a uniform/comparable performance across sensitive groups. In this work, we investigate the gender bias of deep Face Recognition networks. In order to measure this bias, we introduce two new metrics, $\mathrm{BFAR}$ and $\mathrm{BFRR}$, that better reflect the inherent deployment needs of Face Recognition systems. Motivated by geometric considerations, we mitigate gender bias through a new post-processing methodology which transforms the deep embeddings of a pre-trained model to give more representation power to discriminated subgroups. It consists in training a shallow neural network by minimizing a Fair von Mises-Fisher loss whose hyperparameters account for the intra-class variance of each gender. Interestingly, we empirically observe that these hyperparameters are correlated with our fairness metrics. In fact, extensive numerical experiments on a variety of datasets show that a careful selection significantly reduces gender bias.
The Glass Ceiling of Automatic Evaluation in Natural Language Generation
Aug 31, 2022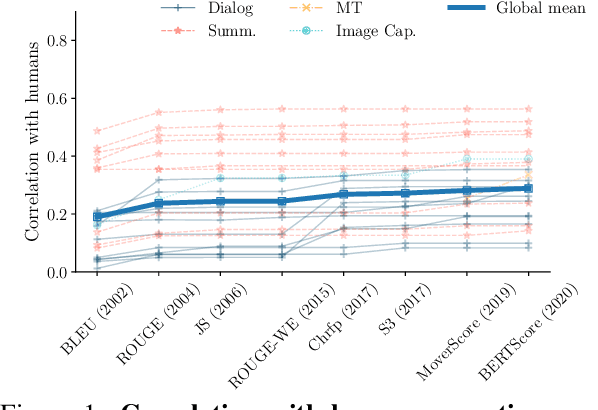
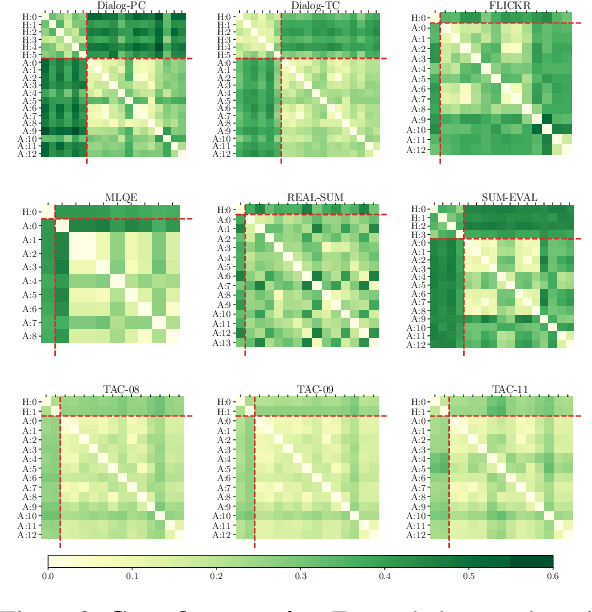
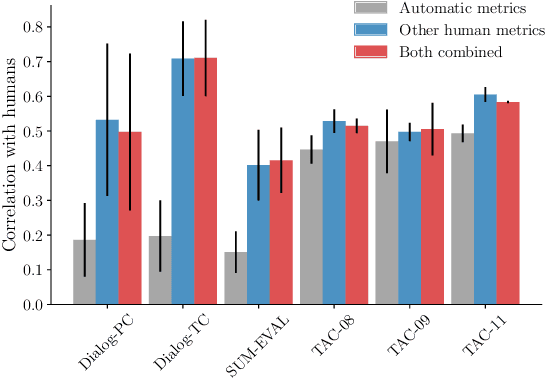
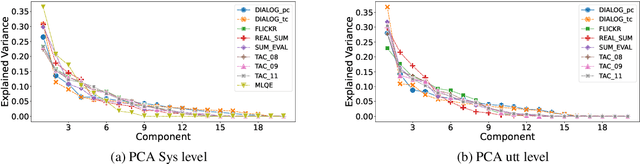
Automatic evaluation metrics capable of replacing human judgments are critical to allowing fast development of new methods. Thus, numerous research efforts have focused on crafting such metrics. In this work, we take a step back and analyze recent progress by comparing the body of existing automatic metrics and human metrics altogether. As metrics are used based on how they rank systems, we compare metrics in the space of system rankings. Our extensive statistical analysis reveals surprising findings: automatic metrics -- old and new -- are much more similar to each other than to humans. Automatic metrics are not complementary and rank systems similarly. Strikingly, human metrics predict each other much better than the combination of all automatic metrics used to predict a human metric. It is surprising because human metrics are often designed to be independent, to capture different aspects of quality, e.g. content fidelity or readability. We provide a discussion of these findings and recommendations for future work in the field of evaluation.
Learning Disentangled Textual Representations via Statistical Measures of Similarity
May 07, 2022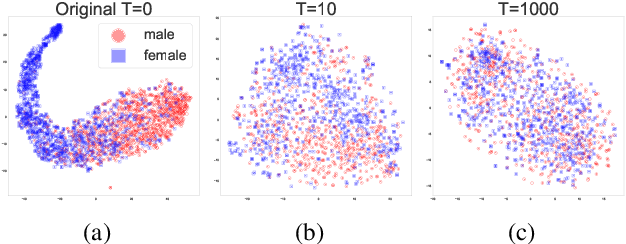
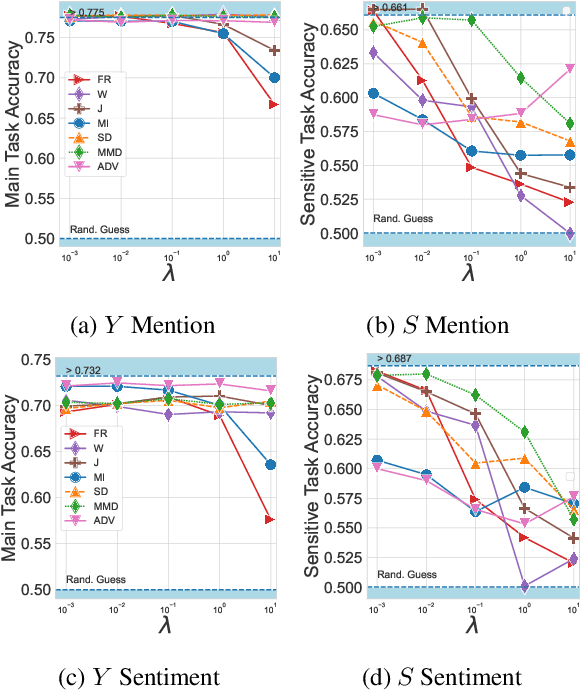
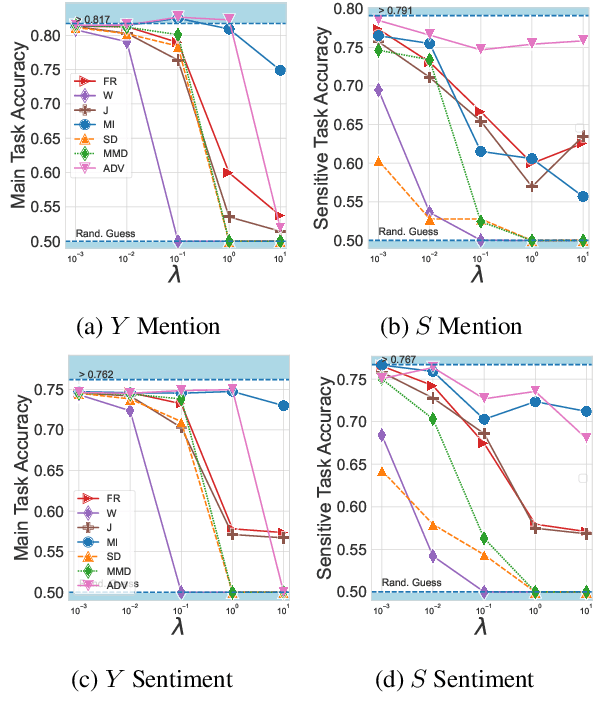
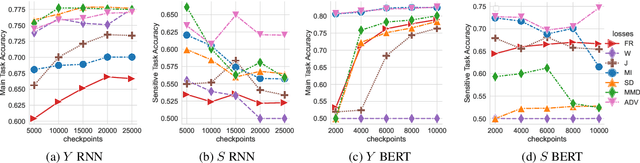
When working with textual data, a natural application of disentangled representations is fair classification where the goal is to make predictions without being biased (or influenced) by sensitive attributes that may be present in the data (e.g., age, gender or race). Dominant approaches to disentangle a sensitive attribute from textual representations rely on learning simultaneously a penalization term that involves either an adversarial loss (e.g., a discriminator) or an information measure (e.g., mutual information). However, these methods require the training of a deep neural network with several parameter updates for each update of the representation model. As a matter of fact, the resulting nested optimization loop is both time consuming, adding complexity to the optimization dynamic, and requires a fine hyperparameter selection (e.g., learning rates, architecture). In this work, we introduce a family of regularizers for learning disentangled representations that do not require training. These regularizers are based on statistical measures of similarity between the conditional probability distributions with respect to the sensitive attributes. Our novel regularizers do not require additional training, are faster and do not involve additional tuning while achieving better results both when combined with pretrained and randomly initialized text encoders.