 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Glass Ceiling of Automatic Evaluation in Natural Language Generation
Paper and Code
Aug 31, 2022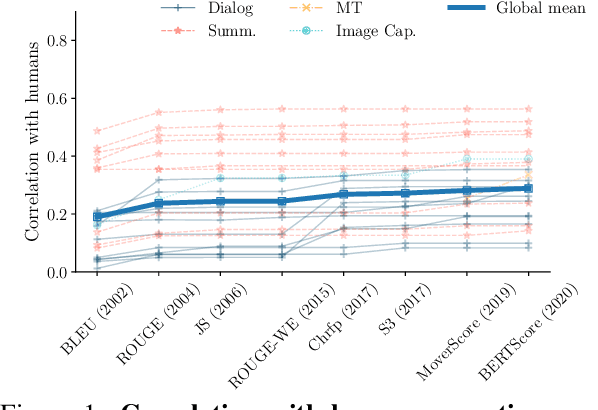
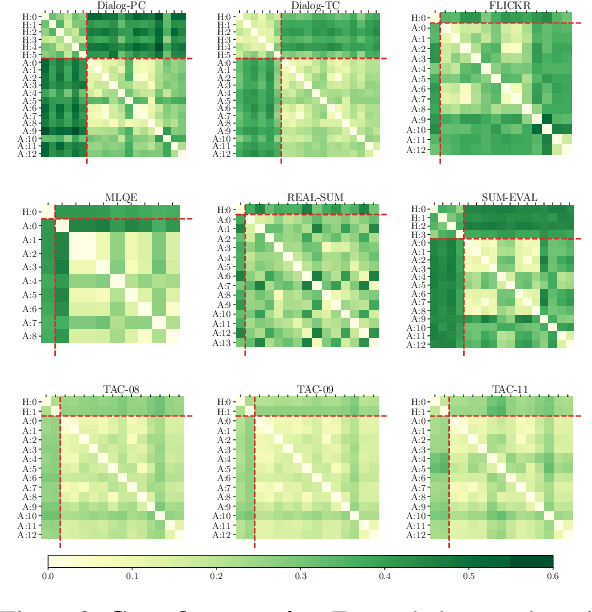
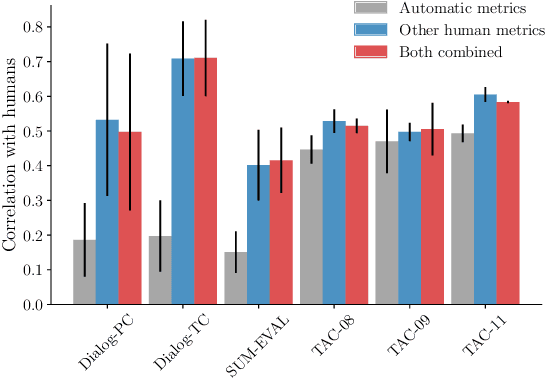
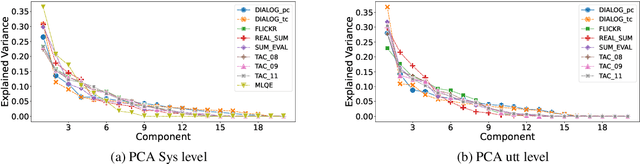
Automatic evaluation metrics capable of replacing human judgments are critical to allowing fast development of new methods. Thus, numerous research efforts have focused on crafting such metrics. In this work, we take a step back and analyze recent progress by comparing the body of existing automatic metrics and human metrics altogether. As metrics are used based on how they rank systems, we compare metrics in the space of system rankings. Our extensive statistical analysis reveals surprising findings: automatic metrics -- old and new -- are much more similar to each other than to humans. Automatic metrics are not complementary and rank systems similarly. Strikingly, human metrics predict each other much better than the combination of all automatic metrics used to predict a human metric. It is surprising because human metrics are often designed to be independent, to capture different aspects of quality, e.g. content fidelity or readability. We provide a discussion of these findings and recommendations for future work in the field of evaluation.