 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Distributed Learning under Resource Constraints: Decentralized Quantile Estimation via (Asynchronous) ADMM
Jan 28, 2026Specifications for decentralized learning on resource-constrained edge devices require algorithms that are communication-efficient, robust to data corruption, and lightweight in memory usage. While state-of-the-art gossip-based methods satisfy the first requirement, achieving robustness remains challenging. Asynchronous decentralized ADMM-based methods have been explored for estimating the median, a statistical centrality measure that is notoriously more robust than the mean. However, existing approaches require memory that scales with node degree, making them impractical when memory is limited. In this paper, we propose AsylADMM, a novel gossip algorithm for decentralized median and quantile estimation, primarily designed for asynchronous updates and requiring only two variables per node. We analyze a synchronous variant of AsylADMM to establish theoretical guarantees and empirically demonstrate fast convergence for the asynchronous algorithm. We then show that our algorithm enables quantile-based trimming, geometric median estimation, and depth-based trimming, with quantile-based trimming empirically outperforming existing rank-based methods. Finally, we provide a novel theoretical analysis of rank-based trimming via Markov chain theory.
TimeSAE: Sparse Decoding for Faithful Explanations of Black-Box Time Series Models
Jan 14, 2026As black box models and pretrained models gain traction in time series applications, understanding and explaining their predictions becomes increasingly vital, especially in high-stakes domains where interpretability and trust are essential. However, most of the existing methods involve only in-distribution explanation, and do not generalize outside the training support, which requires the learning capability of generalization. In this work, we aim to provide a framework to explain black-box models for time series data through the dual lenses of Sparse Autoencoders (SAEs) and causality. We show that many current explanation methods are sensitive to distributional shifts, limiting their effectiveness in real-world scenarios. Building on the concept of Sparse Autoencoder, we introduce TimeSAE, a framework for black-box model explanation. We conduct extensive evaluations of TimeSAE on both synthetic and real-world time series datasets, comparing it to leading baselines. The results, supported by both quantitative metrics and qualitative insights, show that TimeSAE provides more faithful and robust explanations. Our code is available in an easy-to-use library TimeSAE-Lib: https://anonymous.4open.science/w/TimeSAE-571D/.
Asynchronous Gossip Algorithms for Rank-Based Statistical Methods
Sep 09, 2025

As decentralized AI and edge intelligence become increasingly prevalent, ensuring robustness and trustworthiness in such distributed settings has become a critical issue-especially in the presence of corrupted or adversarial data. Traditional decentralized algorithms are vulnerable to data contamination as they typically rely on simple statistics (e.g., means or sum), motivating the need for more robust statistics. In line with recent work on decentralized estimation of trimmed means and ranks, we develop gossip algorithms for computing a broad class of rank-based statistics, including L-statistics and rank statistics-both known for their robustness to outliers. We apply our method to perform robust distributed two-sample hypothesis testing, introducing the first gossip algorithm for Wilcoxon rank-sum tests. We provide rigorous convergence guarantees, including the first convergence rate bound for asynchronous gossip-based rank estimation. We empirically validate our theoretical results through experiments on diverse network topologies.
Robust Distributed Estimation: Extending Gossip Algorithms to Ranking and Trimmed Means
May 23, 2025



This paper addresses the problem of robust estimation in gossip algorithms over arbitrary communication graphs. Gossip algorithms are fully decentralized, relying only on local neighbor-to-neighbor communication, making them well-suited for situations where communication is constrained. A fundamental challenge in existing mean-based gossip algorithms is their vulnerability to malicious or corrupted nodes. In this paper, we show that an outlier-robust mean can be computed by globally estimating a robust statistic. More specifically, we propose a novel gossip algorithm for rank estimation, referred to as \textsc{GoRank}, and leverage it to design a gossip procedure dedicated to trimmed mean estimation, coined \textsc{GoTrim}. In addition to a detailed description of the proposed methods, a key contribution of our work is a precise convergence analysis: we establish an $\mathcal{O}(1/t)$ rate for rank estimation and an $\mathcal{O}(\log(t)/t)$ rate for trimmed mean estimation, where by $t$ is meant the number of iterations. Moreover, we provide a breakdown point analysis of \textsc{GoTrim}. We empirically validate our theoretical results through experiments on diverse network topologies, data distributions and contamination schemes.
Polar Coordinate-Based 2D Pose Prior with Neural Distance Field
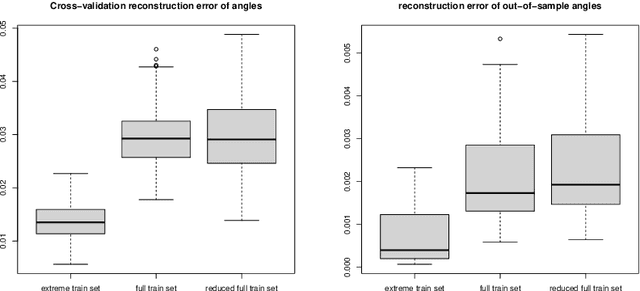
May 06, 2025Human pose capture is essential for sports analysis, enabling precise evaluation of athletes' movements. While deep learning-based human pose estimation (HPE) models from RGB videos have achieved impressive performance on public datasets, their effectiveness in real-world sports scenarios is often hindered by motion blur, occlusions, and domain shifts across different pose representations. Fine-tuning these models can partially alleviate such challenges but typically requires large-scale annotated data and still struggles to generalize across diverse sports environments. To address these limitations, we propose a 2D pose prior-guided refinement approach based on Neural Distance Fields (NDF). Unlike existing approaches that rely solely on angular representations of human poses, we introduce a polar coordinate-based representation that explicitly incorporates joint connection lengths, enabling a more accurate correction of erroneous pose estimations. Additionally, we define a novel non-geodesic distance metric that separates angular and radial discrepancies, which we demonstrate is better suited for polar representations than traditional geodesic distances. To mitigate data scarcity, we develop a gradient-based batch-projection augmentation strategy, which synthesizes realistic pose samples through iterative refinement. Our method is evaluated on a long jump dataset, demonstrating its ability to improve 2D pose estimation across multiple pose representations, making it robust across different domains. Experimental results show that our approach enhances pose plausibility while requiring only limited training data. Code is available at: https://github.com/QGAN2019/polar-NDF.
Flexible Parametric Inference for Space-Time Hawkes Processes
Jun 10, 2024

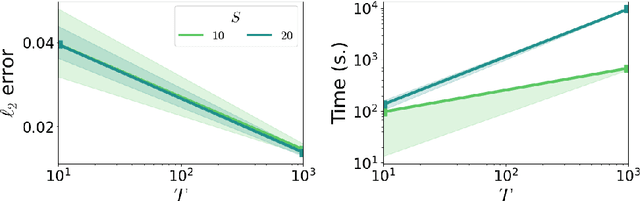

Many modern spatio-temporal data sets, in sociology, epidemiology or seismology, for example, exhibit self-exciting characteristics, triggering and clustering behaviors both at the same time, that a suitable Hawkes space-time process can accurately capture. This paper aims to develop a fast and flexible parametric inference technique to recover the parameters of the kernel functions involved in the intensity function of a space-time Hawkes process based on such data. Our statistical approach combines three key ingredients: 1) kernels with finite support are considered, 2) the space-time domain is appropriately discretized, and 3) (approximate) precomputations are used. The inference technique we propose then consists of a $\ell_2$ gradient-based solver that is fast and statistically accurate. In addition to describing the algorithmic aspects, numerical experiments have been carried out on synthetic and real spatio-temporal data, providing solid empirical evidence of the relevance of the proposed methodology.
Regular Variation in Hilbert Spaces and Principal Component Analysis for Functional Extremes
Aug 02, 2023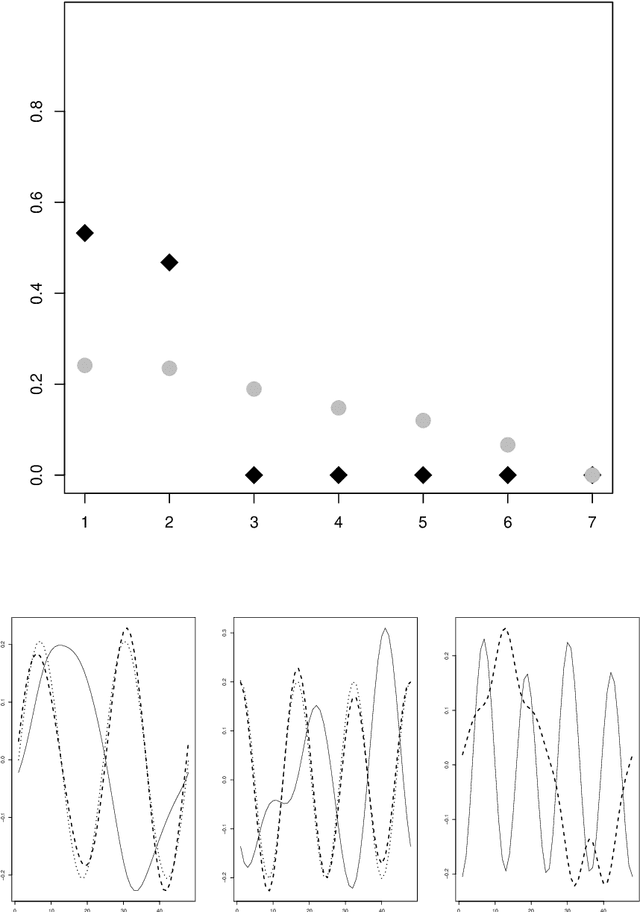
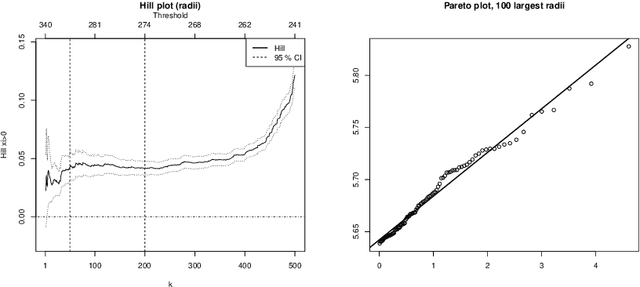
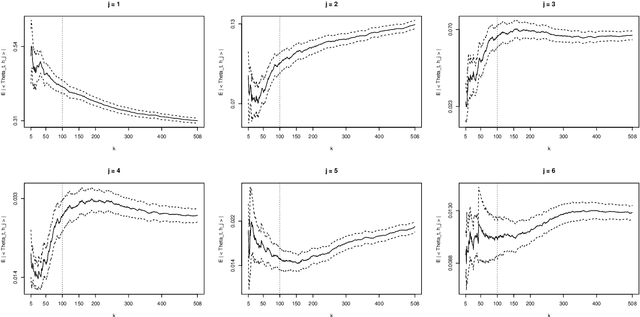
Motivated by the increasing availability of data of functional nature, we develop a general probabilistic and statistical framework for extremes of regularly varying random elements $X$ in $L^2[0,1]$. We place ourselves in a Peaks-Over-Threshold framework where a functional extreme is defined as an observation $X$ whose $L^2$-norm $\|X\|$ is comparatively large. Our goal is to propose a dimension reduction framework resulting into finite dimensional projections for such extreme observations. Our contribution is double. First, we investigate the notion of Regular Variation for random quantities valued in a general separable Hilbert space, for which we propose a novel concrete characterization involving solely stochastic convergence of real-valued random variables. Second, we propose a notion of functional Principal Component Analysis (PCA) accounting for the principal `directions' of functional extremes. We investigate the statistical properties of the empirical covariance operator of the angular component of extreme functions, by upper-bounding the Hilbert-Schmidt norm of the estimation error for finite sample sizes. Numerical experiments with simulated and real data illustrate this work.
On Regression in Extreme Regions
Mar 06, 2023



In the classic regression problem, the value of a real-valued random variable $Y$ is to be predicted based on the observation of a random vector $X$, taking its values in $\mathbb{R}^d$ with $d\geq 1$ say. The statistical learning problem consists in building a predictive function $\hat{f}:\mathbb{R}^d\to \mathbb{R}$ based on independent copies of the pair $(X,Y)$ so that $Y$ is approximated by $\hat{f}(X)$ with minimum error in the mean-squared sense. Motivated by various applications, ranging from environmental sciences to finance or insurance, special attention is paid here to the case of extreme (i.e. very large) observations $X$. Because of their rarity, they contribute in a negligible manner to the (empirical) error and the predictive performance of empirical quadratic risk minimizers can be consequently very poor in extreme regions. In this paper, we develop a general framework for regression in the extremes. It is assumed that $X$'s conditional distribution given $Y$ belongs to a non parametric class of heavy-tailed probability distributions. It is then shown that an asymptotic notion of risk can be tailored to summarize appropriately predictive performance in extreme regions of the input space. It is also proved that minimization of an empirical and non asymptotic version of this 'extreme risk', based on a fraction of the largest observations solely, yields regression functions with good generalization capacity. In addition, numerical results providing strong empirical evidence of the relevance of the approach proposed are displayed.
On Medians of (Randomized) Pairwise Means
Nov 01, 2022Tournament procedures, recently introduced in Lugosi & Mendelson (2016), offer an appealing alternative, from a theoretical perspective at least, to the principle of Empirical Risk Minimization in machine learning. Statistical learning by Median-of-Means (MoM) basically consists in segmenting the training data into blocks of equal size and comparing the statistical performance of every pair of candidate decision rules on each data block: that with highest performance on the majority of the blocks is declared as the winner. In the context of nonparametric regression, functions having won all their duels have been shown to outperform empirical risk minimizers w.r.t. the mean squared error under minimal assumptions, while exhibiting robustness properties. It is the purpose of this paper to extend this approach in order to address other learning problems, in particular for which the performance criterion takes the form of an expectation over pairs of observations rather than over one single observation, as may be the case in pairwise ranking, clustering or metric learning. Precisely, it is proved here that the bounds achieved by MoM are essentially conserved when the blocks are built by means of independent sampling without replacement schemes instead of a simple segmentation. These results are next extended to situations where the risk is related to a pairwise loss function and its empirical counterpart is of the form of a $U$-statistic. Beyond theoretical results guaranteeing the performance of the learning/estimation methods proposed, some numerical experiments provide empirical evidence of their relevance in practice.
A Statistical Learning View of Simple Kriging
Feb 18, 2022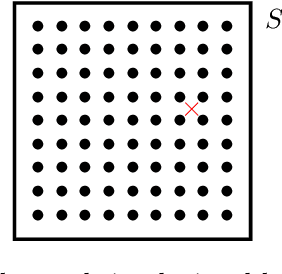
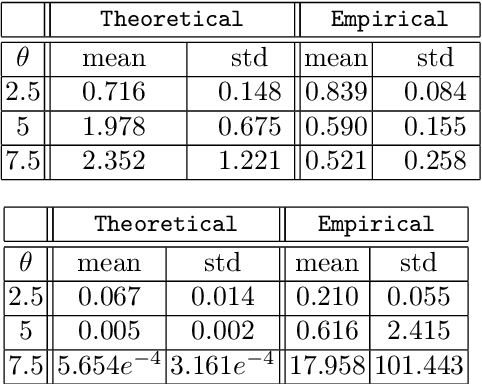
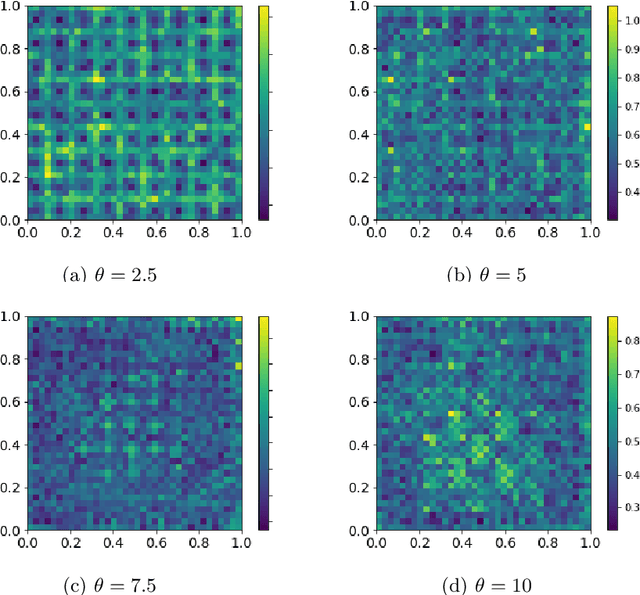
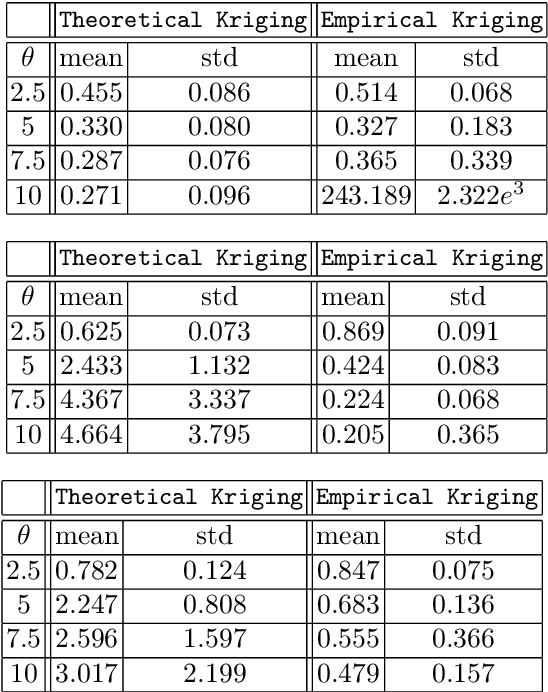
In the Big Data era, with the ubiquity of geolocation sensors in particular, massive datasets exhibiting a possibly complex spatial dependence structure are becoming increasingly available. In this context, the standard probabilistic theory of statistical learning does not apply directly and guarantees of the generalization capacity of predictive rules learned from such data are left to establish. We analyze here the simple Kriging task, the flagship problem in Geostatistics: the values of a square integrable random field $X=\{X_s\}_{s\in S}$, $S\subset \mathbb{R}^2$, with unknown covariance structure are to be predicted with minimum quadratic risk, based upon observing a single realization of the spatial process at a finite number of locations $s_1,\; \ldots,\; s_n$ in $S$. Despite the connection of this minimization problem with kernel ridge regression, establishing the generalization capacity of empirical risk minimizers is far from straightforward, due to the non i.i.d. nature of the spatial data $X_{s_1},\; \ldots,\; X_{s_n}$ involved. In this article, nonasymptotic bounds of order $O_{\mathbb{P}}(1/n)$ are proved for the excess risk of a plug-in predictive rule mimicking the true minimizer in the case of isotropic stationary Gaussian processes observed at locations forming a regular grid. These theoretical results, as well as the role played by the technical conditions required to establish them, are illustrated by various numerical experiments and hopefully pave the way for further developments in statistical learning based on spatial data.