 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Recognition with Deep Learning from Biased Image Datasets
Sep 06, 2021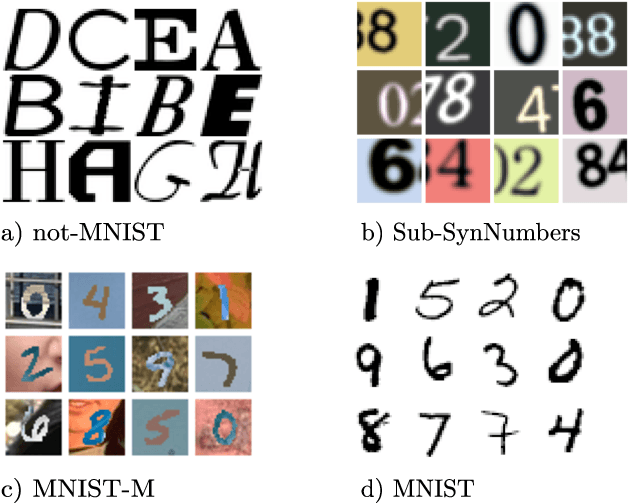
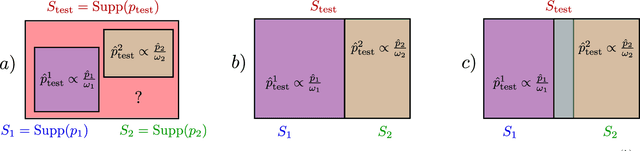
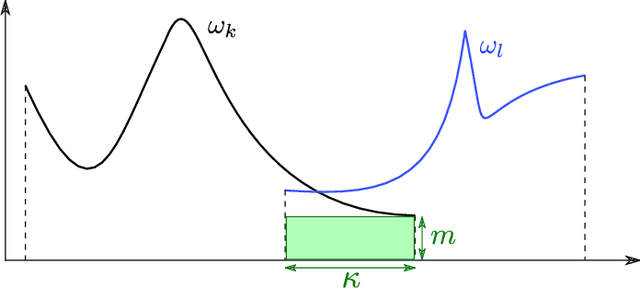
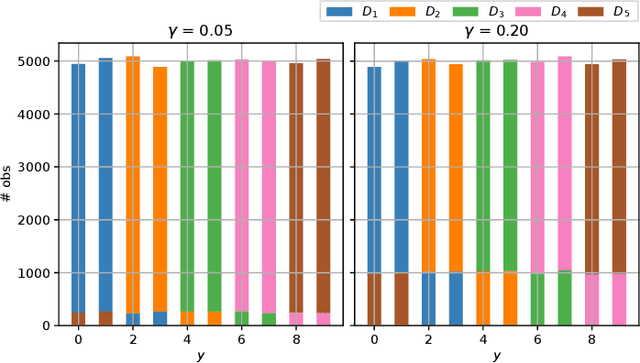
In practice, and more especially when training deep neural networks, visual recognition rules are often learned based on various sources of information. On the other hand, the recent deployment of facial recognition systems with uneven predictive performances on different population segments highlights the representativeness issues possibly induced by a naive aggregation of image datasets. Indeed, sampling bias does not vanish simply by considering larger datasets, and ignoring its impact may completely jeopardize the generalization capacity of the learned prediction rules. In this paper, we show how biasing models, originally introduced for nonparametric estimation in (Gill et al., 1988), and recently revisited from the perspective of statistical learning theory in (Laforgue and Cl\'emen\c{c}on, 2019), can be applied to remedy these problems in the context of visual recognition. Based on the (approximate) knowledge of the biasing mechanisms at work, our approach consists in reweighting the observations, so as to form a nearly debiased estimator of the target distribution. One key condition for our method to be theoretically valid is that the supports of the distributions generating the biased datasets at disposal must overlap, and cover the support of the target distribution. In order to meet this requirement in practice, we propose to use a low dimensional image representation, shared across the image databases. Finally, we provide numerical experiments highlighting the relevance of our approach whenever the biasing functions are appropriately chosen.
A Multiclass Classification Approach to Label Ranking
Feb 21, 2020

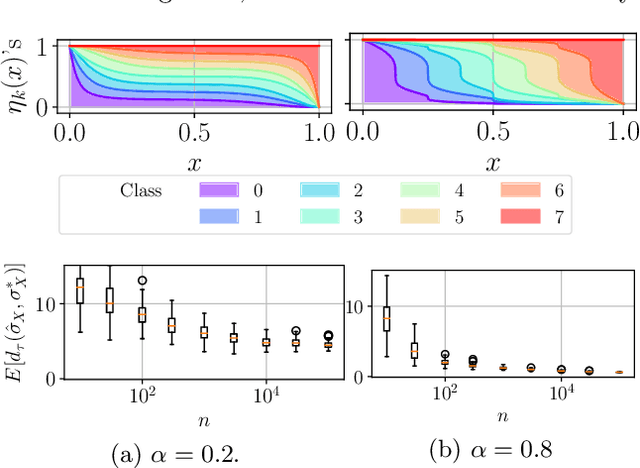

In multiclass classification, the goal is to learn how to predict a random label $Y$, valued in $\mathcal{Y}=\{1,\; \ldots,\; K \}$ with $K\geq 3$, based upon observing a r.v. $X$, taking its values in $\mathbb{R}^q$ with $q\geq 1$ say, by means of a classification rule $g:\mathbb{R}^q\to \mathcal{Y}$ with minimum probability of error $\mathbb{P}\{Y\neq g(X) \}$. However, in a wide variety of situations, the task targeted may be more ambitious, consisting in sorting all the possible label values $y$ that may be assigned to $X$ by decreasing order of the posterior probability $\eta_y(X)=\mathbb{P}\{Y=y \mid X \}$. This article is devoted to the analysis of this statistical learning problem, halfway between multiclass classification and posterior probability estimation (regression) and referred to as label ranking here. We highlight the fact that it can be viewed as a specific variant of ranking median regression (RMR), where, rather than observing a random permutation $\Sigma$ assigned to the input vector $X$ and drawn from a Bradley-Terry-Luce-Plackett model with conditional preference vector $(\eta_1(X),\; \ldots,\; \eta_K(X))$, the sole information available for training a label ranking rule is the label $Y$ ranked on top, namely $\Sigma^{-1}(1)$. Inspired by recent results in RMR, we prove that under appropriate noise conditions, the One-Versus-One (OVO) approach to multiclassification yields, as a by-product, an optimal ranking of the labels with overwhelming probability. Beyond theoretical guarantees, the relevance of the approach to label ranking promoted in this article is supported by experimental results.
Weighted Empirical Risk Minimization: Sample Selection Bias Correction based on Importance Sampling
Feb 19, 2020


We consider statistical learning problems, when the distribution $P'$ of the training observations $Z'_1,\; \ldots,\; Z'_n$ differs from the distribution $P$ involved in the risk one seeks to minimize (referred to as the test distribution) but is still defined on the same measurable space as $P$ and dominates it. In the unrealistic case where the likelihood ratio $\Phi(z)=dP/dP'(z)$ is known, one may straightforwardly extends the Empirical Risk Minimization (ERM) approach to this specific transfer learning setup using the same idea as that behind Importance Sampling, by minimizing a weighted version of the empirical risk functional computed from the 'biased' training data $Z'_i$ with weights $\Phi(Z'_i)$. Although the importance function $\Phi(z)$ is generally unknown in practice, we show that, in various situations frequently encountered in practice, it takes a simple form and can be directly estimated from the $Z'_i$'s and some auxiliary information on the statistical population $P$. By means of linearization techniques, we then prove that the generalization capacity of the approach aforementioned is preserved when plugging the resulting estimates of the $\Phi(Z'_i)$'s into the weighted empirical risk. Beyond these theoretical guarantees, numerical results provide strong empirical evidence of the relevance of the approach promoted in this article.
Learning Fair Scoring Functions: Fairness Definitions, Algorithms and Generalization Bounds for Bipartite Ranking
Feb 19, 2020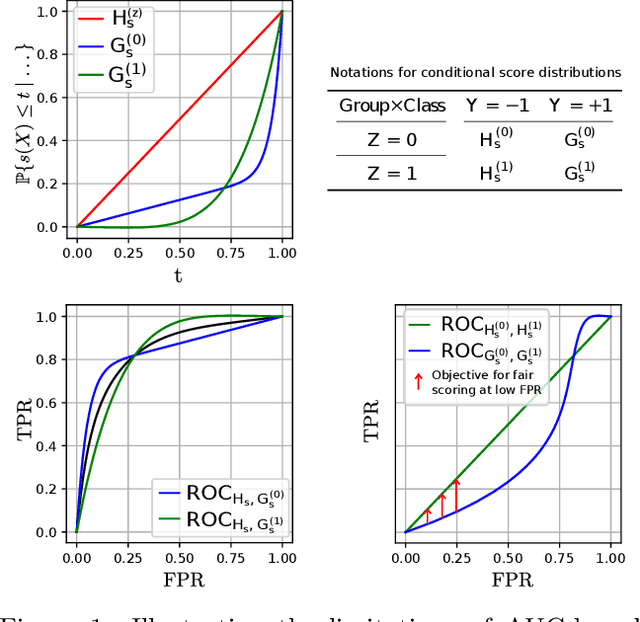

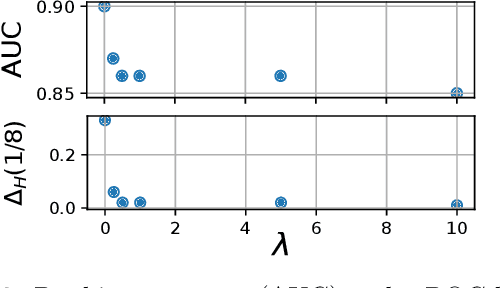
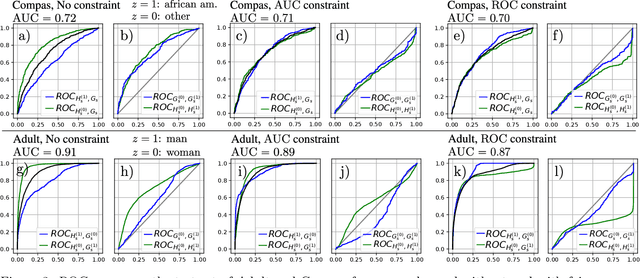
Many applications of artificial intelligence, ranging from credit lending to the design of medical diagnosis support tools through recidivism prediction, involve scoring individuals using a learned function of their attributes. These predictive risk scores are used to rank a set of people, and/or take individual decisions about them based on whether the score exceeds a certain threshold that may depend on the context in which the decision is taken. The level of delegation granted to such systems will heavily depend on how questions of fairness can be answered. While this concern has received a lot of attention in the classification setup, the design of relevant fairness constraints for the problem of learning scoring functions has not been much investigated. In this paper, we propose a flexible approach to group fairness for the scoring problem with binary labeled data, a standard learning task referred to as bipartite ranking. We argue that the functional nature of the ROC curve, the gold standard measuring ranking performance in this context, leads to several possible ways of formulating fairness constraints. We introduce general classes of fairness conditions in bipartite ranking and establish generalization bounds for scoring rules learned under such constraints. Beyond the theoretical formulation and results, we design practical learning algorithms and illustrate our approach with numerical experiments.
On Tree-based Methods for Similarity Learning
Jun 21, 2019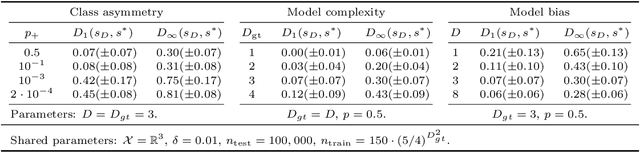
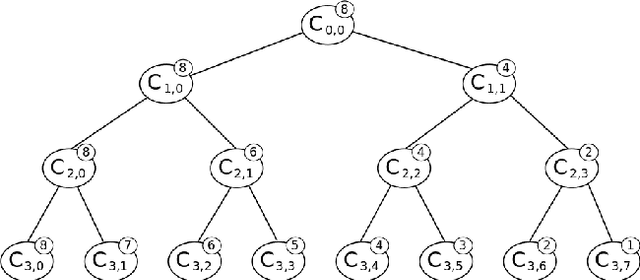

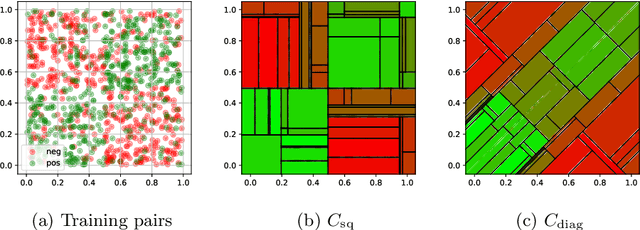
In many situations, the choice of an adequate similarity measure or metric on the feature space dramatically determines the performance of machine learning methods. Building automatically such measures is the specific purpose of metric/similarity learning. In Vogel et al. (2018), similarity learning is formulated as a pairwise bipartite ranking problem: ideally, the larger the probability that two observations in the feature space belong to the same class (or share the same label), the higher the similarity measure between them. From this perspective, the ROC curve is an appropriate performance criterion and it is the goal of this article to extend recursive tree-based ROC optimization techniques in order to propose efficient similarity learning algorithms. The validity of such iterative partitioning procedures in the pairwise setting is established by means of results pertaining to the theory of U-processes and from a practical angle, it is discussed at length how to implement them by means of splitting rules specifically tailored to the similarity learning task. Beyond these theoretical/methodological contributions, numerical experiments are displayed and provide strong empirical evidence of the performance of the algorithmic approaches we propose.
Trade-offs in Large-Scale Distributed Tuplewise Estimation and Learning
Jun 21, 2019
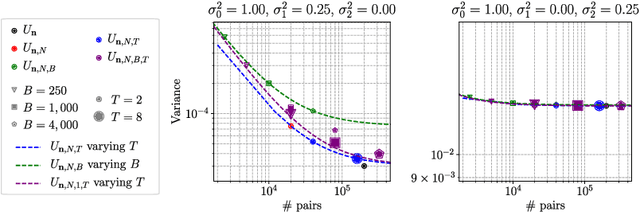
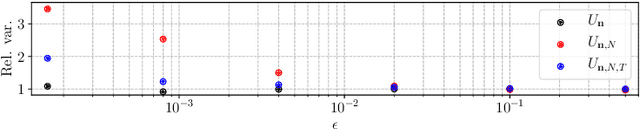
The development of cluster computing frameworks has allowed practitioners to scale out various statistical estimation and machine learning algorithms with minimal programming effort. This is especially true for machine learning problems whose objective function is nicely separable across individual data points, such as classification and regression. In contrast, statistical learning tasks involving pairs (or more generally tuples) of data points - such as metric learning, clustering or ranking do not lend themselves as easily to data-parallelism and in-memory computing. In this paper, we investigate how to balance between statistical performance and computational efficiency in such distributed tuplewise statistical problems. We first propose a simple strategy based on occasionally repartitioning data across workers between parallel computation stages, where the number of repartitioning steps rules the trade-off between accuracy and runtime. We then present some theoretical results highlighting the benefits brought by the proposed method in terms of variance reduction, and extend our results to design distributed stochastic gradient descent algorithms for tuplewise empirical risk minimization. Our results are supported by numerical experiments in pairwise statistical estimation and learning on synthetic and real-world datasets.
A Probabilistic Theory of Supervised Similarity Learning for Pointwise ROC Curve Optimization
Jul 18, 2018
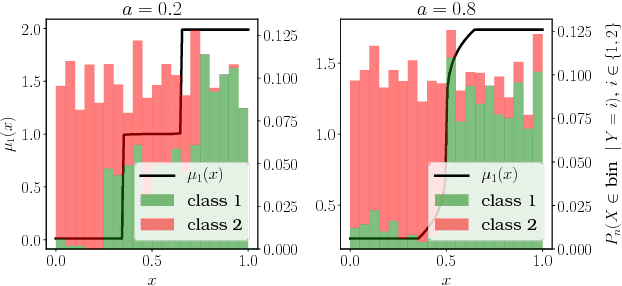

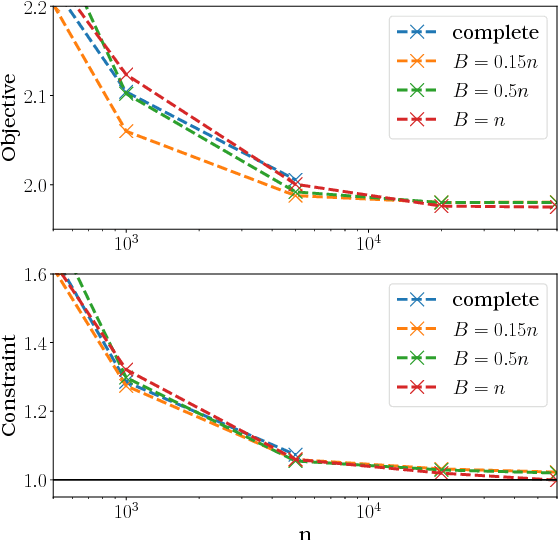
The performance of many machine learning techniques depends on the choice of an appropriate similarity or distance measure on the input space. Similarity learning (or metric learning) aims at building such a measure from training data so that observations with the same (resp. different) label are as close (resp. far) as possible. In this paper, similarity learning is investigated from the perspective of pairwise bipartite ranking, where the goal is to rank the elements of a database by decreasing order of the probability that they share the same label with some query data point, based on the similarity scores. A natural performance criterion in this setting is pointwise ROC optimization: maximize the true positive rate under a fixed false positive rate. We study this novel perspective on similarity learning through a rigorous probabilistic framework. The empirical version of the problem gives rise to a constrained optimization formulation involving U-statistics, for which we derive universal learning rates as well as faster rates under a noise assumption on the data distribution. We also address the large-scale setting by analyzing the effect of sampling-based approximations. Our theoretical results are supported by illustrative numerical experiments.
* 8 pages main paper, 22 pages with appendices, proceedings of ICML 2018