 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVisual Recognition with Deep Learning from Biased Image Datasets
Paper and Code
Sep 06, 2021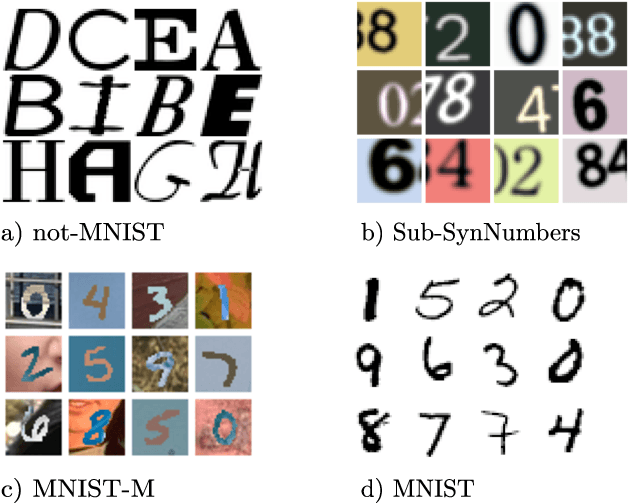
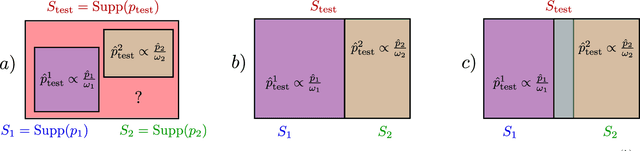
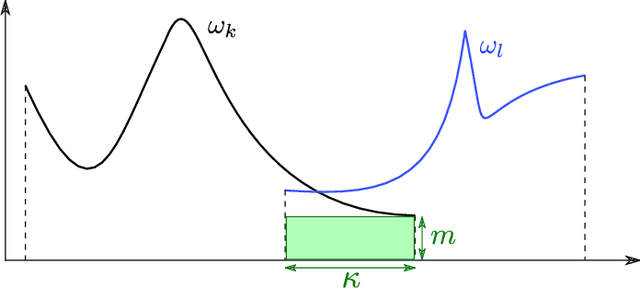
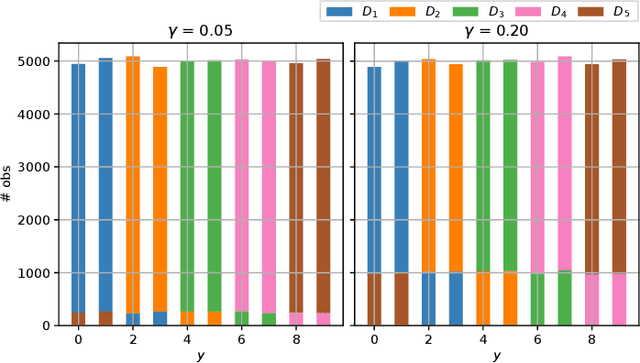
In practice, and more especially when training deep neural networks, visual recognition rules are often learned based on various sources of information. On the other hand, the recent deployment of facial recognition systems with uneven predictive performances on different population segments highlights the representativeness issues possibly induced by a naive aggregation of image datasets. Indeed, sampling bias does not vanish simply by considering larger datasets, and ignoring its impact may completely jeopardize the generalization capacity of the learned prediction rules. In this paper, we show how biasing models, originally introduced for nonparametric estimation in (Gill et al., 1988), and recently revisited from the perspective of statistical learning theory in (Laforgue and Cl\'emen\c{c}on, 2019), can be applied to remedy these problems in the context of visual recognition. Based on the (approximate) knowledge of the biasing mechanisms at work, our approach consists in reweighting the observations, so as to form a nearly debiased estimator of the target distribution. One key condition for our method to be theoretically valid is that the supports of the distributions generating the biased datasets at disposal must overlap, and cover the support of the target distribution. In order to meet this requirement in practice, we propose to use a low dimensional image representation, shared across the image databases. Finally, we provide numerical experiments highlighting the relevance of our approach whenever the biasing functions are appropriately chosen.