 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrade-offs in Large-Scale Distributed Tuplewise Estimation and Learning
Jun 21, 2019
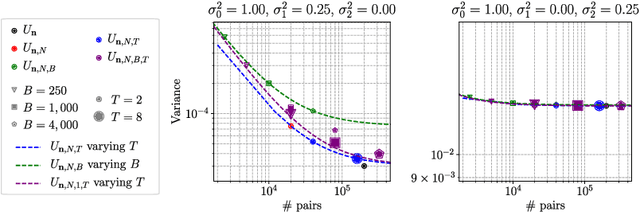
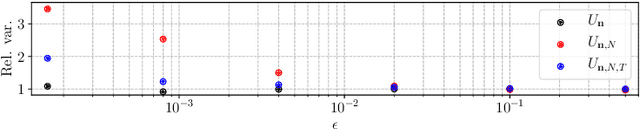
The development of cluster computing frameworks has allowed practitioners to scale out various statistical estimation and machine learning algorithms with minimal programming effort. This is especially true for machine learning problems whose objective function is nicely separable across individual data points, such as classification and regression. In contrast, statistical learning tasks involving pairs (or more generally tuples) of data points - such as metric learning, clustering or ranking do not lend themselves as easily to data-parallelism and in-memory computing. In this paper, we investigate how to balance between statistical performance and computational efficiency in such distributed tuplewise statistical problems. We first propose a simple strategy based on occasionally repartitioning data across workers between parallel computation stages, where the number of repartitioning steps rules the trade-off between accuracy and runtime. We then present some theoretical results highlighting the benefits brought by the proposed method in terms of variance reduction, and extend our results to design distributed stochastic gradient descent algorithms for tuplewise empirical risk minimization. Our results are supported by numerical experiments in pairwise statistical estimation and learning on synthetic and real-world datasets.
Survey schemes for stochastic gradient descent with applications to M-estimation
Jan 09, 2015
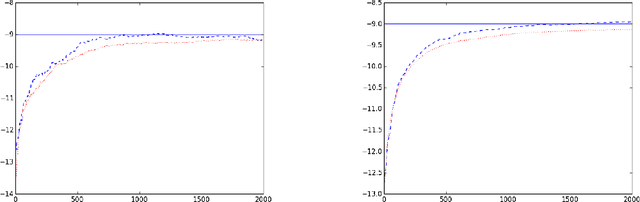
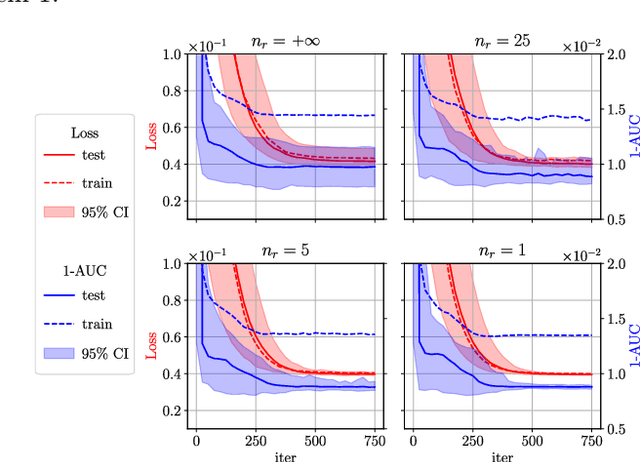
In certain situations that shall be undoubtedly more and more common in the Big Data era, the datasets available are so massive that computing statistics over the full sample is hardly feasible, if not unfeasible. A natural approach in this context consists in using survey schemes and substituting the "full data" statistics with their counterparts based on the resulting random samples, of manageable size. It is the main purpose of this paper to investigate the impact of survey sampling with unequal inclusion probabilities on stochastic gradient descent-based M-estimation methods in large-scale statistical and machine-learning problems. Precisely, we prove that, in presence of some a priori information, one may significantly increase asymptotic accuracy when choosing appropriate first order inclusion probabilities, without affecting complexity. These striking results are described here by limit theorems and are also illustrated by numerical experiments.