 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Medians of (Randomized) Pairwise Means
Nov 01, 2022Tournament procedures, recently introduced in Lugosi & Mendelson (2016), offer an appealing alternative, from a theoretical perspective at least, to the principle of Empirical Risk Minimization in machine learning. Statistical learning by Median-of-Means (MoM) basically consists in segmenting the training data into blocks of equal size and comparing the statistical performance of every pair of candidate decision rules on each data block: that with highest performance on the majority of the blocks is declared as the winner. In the context of nonparametric regression, functions having won all their duels have been shown to outperform empirical risk minimizers w.r.t. the mean squared error under minimal assumptions, while exhibiting robustness properties. It is the purpose of this paper to extend this approach in order to address other learning problems, in particular for which the performance criterion takes the form of an expectation over pairs of observations rather than over one single observation, as may be the case in pairwise ranking, clustering or metric learning. Precisely, it is proved here that the bounds achieved by MoM are essentially conserved when the blocks are built by means of independent sampling without replacement schemes instead of a simple segmentation. These results are next extended to situations where the risk is related to a pairwise loss function and its empirical counterpart is of the form of a $U$-statistic. Beyond theoretical results guaranteeing the performance of the learning/estimation methods proposed, some numerical experiments provide empirical evidence of their relevance in practice.
Survey schemes for stochastic gradient descent with applications to M-estimation
Jan 09, 2015
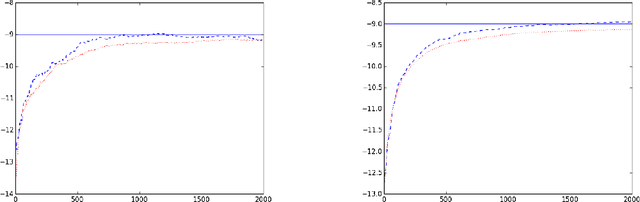
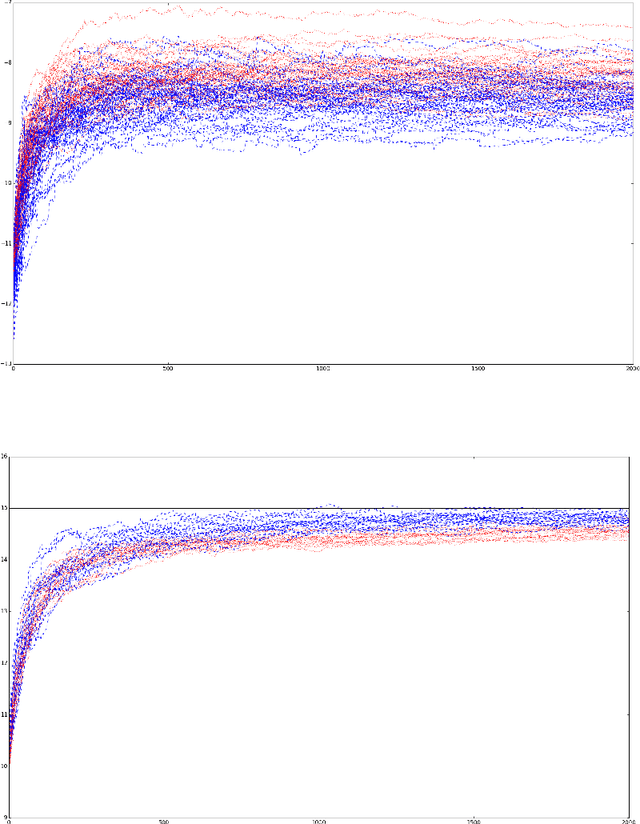
In certain situations that shall be undoubtedly more and more common in the Big Data era, the datasets available are so massive that computing statistics over the full sample is hardly feasible, if not unfeasible. A natural approach in this context consists in using survey schemes and substituting the "full data" statistics with their counterparts based on the resulting random samples, of manageable size. It is the main purpose of this paper to investigate the impact of survey sampling with unequal inclusion probabilities on stochastic gradient descent-based M-estimation methods in large-scale statistical and machine-learning problems. Precisely, we prove that, in presence of some a priori information, one may significantly increase asymptotic accuracy when choosing appropriate first order inclusion probabilities, without affecting complexity. These striking results are described here by limit theorems and are also illustrated by numerical experiments.