 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multiclass Classification Approach to Label Ranking
Paper and Code
Feb 21, 2020

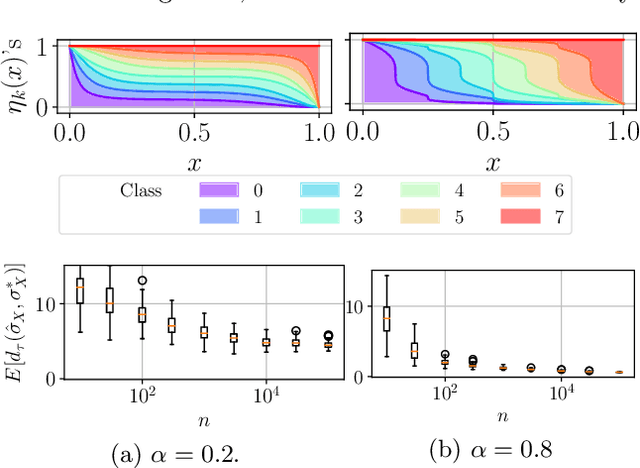

In multiclass classification, the goal is to learn how to predict a random label $Y$, valued in $\mathcal{Y}=\{1,\; \ldots,\; K \}$ with $K\geq 3$, based upon observing a r.v. $X$, taking its values in $\mathbb{R}^q$ with $q\geq 1$ say, by means of a classification rule $g:\mathbb{R}^q\to \mathcal{Y}$ with minimum probability of error $\mathbb{P}\{Y\neq g(X) \}$. However, in a wide variety of situations, the task targeted may be more ambitious, consisting in sorting all the possible label values $y$ that may be assigned to $X$ by decreasing order of the posterior probability $\eta_y(X)=\mathbb{P}\{Y=y \mid X \}$. This article is devoted to the analysis of this statistical learning problem, halfway between multiclass classification and posterior probability estimation (regression) and referred to as label ranking here. We highlight the fact that it can be viewed as a specific variant of ranking median regression (RMR), where, rather than observing a random permutation $\Sigma$ assigned to the input vector $X$ and drawn from a Bradley-Terry-Luce-Plackett model with conditional preference vector $(\eta_1(X),\; \ldots,\; \eta_K(X))$, the sole information available for training a label ranking rule is the label $Y$ ranked on top, namely $\Sigma^{-1}(1)$. Inspired by recent results in RMR, we prove that under appropriate noise conditions, the One-Versus-One (OVO) approach to multiclassification yields, as a by-product, an optimal ranking of the labels with overwhelming probability. Beyond theoretical guarantees, the relevance of the approach to label ranking promoted in this article is supported by experimental results.