 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Tree-based Methods for Similarity Learning
Paper and Code
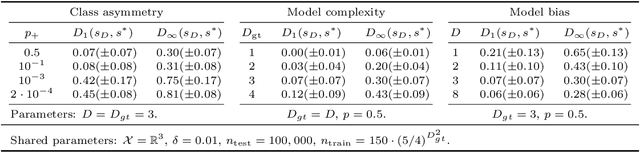
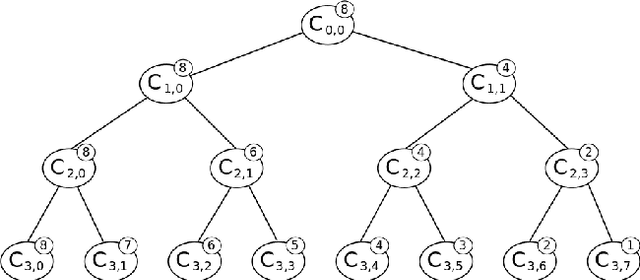

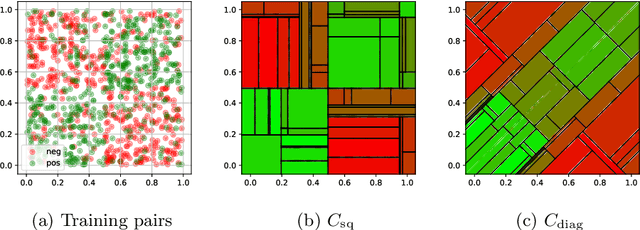
In many situations, the choice of an adequate similarity measure or metric on the feature space dramatically determines the performance of machine learning methods. Building automatically such measures is the specific purpose of metric/similarity learning. In Vogel et al. (2018), similarity learning is formulated as a pairwise bipartite ranking problem: ideally, the larger the probability that two observations in the feature space belong to the same class (or share the same label), the higher the similarity measure between them. From this perspective, the ROC curve is an appropriate performance criterion and it is the goal of this article to extend recursive tree-based ROC optimization techniques in order to propose efficient similarity learning algorithms. The validity of such iterative partitioning procedures in the pairwise setting is established by means of results pertaining to the theory of U-processes and from a practical angle, it is discussed at length how to implement them by means of splitting rules specifically tailored to the similarity learning task. Beyond these theoretical/methodological contributions, numerical experiments are displayed and provide strong empirical evidence of the performance of the algorithmic approaches we propose.