 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStick-Breaking Embedded Topic Model with Continuous Optimal Transport for Online Analysis of Document Streams
Oct 21, 2025Online topic models are unsupervised algorithms to identify latent topics in data streams that continuously evolve over time. Although these methods naturally align with real-world scenarios, they have received considerably less attention from the community compared to their offline counterparts, due to specific additional challenges. To tackle these issues, we present SB-SETM, an innovative model extending the Embedded Topic Model (ETM) to process data streams by merging models formed on successive partial document batches. To this end, SB-SETM (i) leverages a truncated stick-breaking construction for the topic-per-document distribution, enabling the model to automatically infer from the data the appropriate number of active topics at each timestep; and (ii) introduces a merging strategy for topic embeddings based on a continuous formulation of optimal transport adapted to the high dimensionality of the latent topic space. Numerical experiments show SB-SETM outperforming baselines on simulated scenarios. We extensively test it on a real-world corpus of news articles covering the Russian-Ukrainian war throughout 2022-2023.
IKrNet: A Neural Network for Detecting Specific Drug-Induced Patterns in Electrocardiograms Amidst Physiological Variability
May 12, 2025Monitoring and analyzing electrocardiogram (ECG) signals, even under varying physiological conditions, including those influenced by physical activity, drugs and stress, is crucial to accurately assess cardiac health. However, current AI-based methods often fail to account for how these factors interact and alter ECG patterns, ultimately limiting their applicability in real-world settings. This study introduces IKrNet, a novel neural network model, which identifies drug-specific patterns in ECGs amidst certain physiological conditions. IKrNet's architecture incorporates spatial and temporal dynamics by using a convolutional backbone with varying receptive field size to capture spatial features. A bi-directional Long Short-Term Memory module is also employed to model temporal dependencies. By treating heart rate variability as a surrogate for physiological fluctuations, we evaluated IKrNet's performance across diverse scenarios, including conditions with physical stress, drug intake alone, and a baseline without drug presence. Our assessment follows a clinical protocol in which 990 healthy volunteers were administered 80mg of Sotalol, a drug which is known to be a precursor to Torsades-de-Pointes, a life-threatening arrhythmia. We show that IKrNet outperforms state-of-the-art models' accuracy and stability in varying physiological conditions, underscoring its clinical viability.
Merging Embedded Topics with Optimal Transport for Online Topic Modeling on Data Streams
Apr 10, 2025



Topic modeling is a key component in unsupervised learning, employed to identify topics within a corpus of textual data. The rapid growth of social media generates an ever-growing volume of textual data daily, making online topic modeling methods essential for managing these data streams that continuously arrive over time. This paper introduces a novel approach to online topic modeling named StreamETM. This approach builds on the Embedded Topic Model (ETM) to handle data streams by merging models learned on consecutive partial document batches using unbalanced optimal transport. Additionally, an online change point detection algorithm is employed to identify shifts in topics over time, enabling the identification of significant changes in the dynamics of text streams. Numerical experiments on simulated and real-world data show StreamETM outperforming competitors.
Optimal Zero-Shot Detector for Multi-Armed Attacks
Feb 27, 2024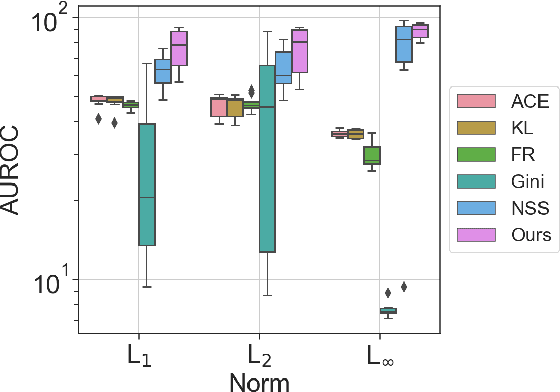
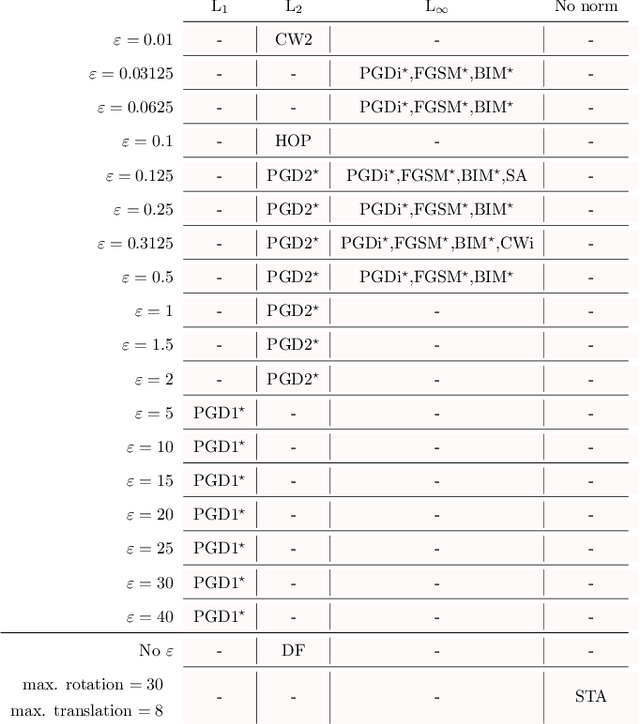
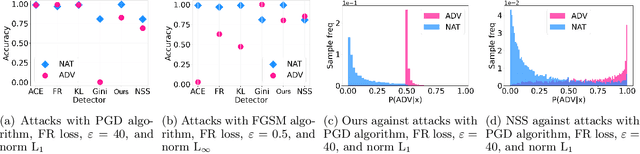
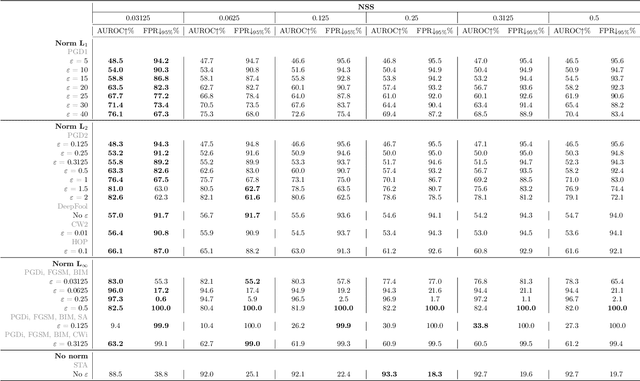
This paper explores a scenario in which a malicious actor employs a multi-armed attack strategy to manipulate data samples, offering them various avenues to introduce noise into the dataset. Our central objective is to protect the data by detecting any alterations to the input. We approach this defensive strategy with utmost caution, operating in an environment where the defender possesses significantly less information compared to the attacker. Specifically, the defender is unable to utilize any data samples for training a defense model or verifying the integrity of the channel. Instead, the defender relies exclusively on a set of pre-existing detectors readily available "off the shelf". To tackle this challenge, we derive an innovative information-theoretic defense approach that optimally aggregates the decisions made by these detectors, eliminating the need for any training data. We further explore a practical use-case scenario for empirical evaluation, where the attacker possesses a pre-trained classifier and launches well-known adversarial attacks against it. Our experiments highlight the effectiveness of our proposed solution, even in scenarios that deviate from the optimal setup.
A Minimax Approach Against Multi-Armed Adversarial Attacks Detection
Feb 04, 2023Multi-armed adversarial attacks, in which multiple algorithms and objective loss functions are simultaneously used at evaluation time, have been shown to be highly successful in fooling state-of-the-art adversarial examples detectors while requiring no specific side information about the detection mechanism. By formalizing the problem at hand, we can propose a solution that aggregates the soft-probability outputs of multiple pre-trained detectors according to a minimax approach. The proposed framework is mathematically sound, easy to implement, and modular, allowing for integrating existing or future detectors. Through extensive evaluation on popular datasets (e.g., CIFAR10 and SVHN), we show that our aggregation consistently outperforms individual state-of-the-art detectors against multi-armed adversarial attacks, making it an effective solution to improve the resilience of available methods.
MEAD: A Multi-Armed Approach for Evaluation of Adversarial Examples Detectors
Jun 30, 2022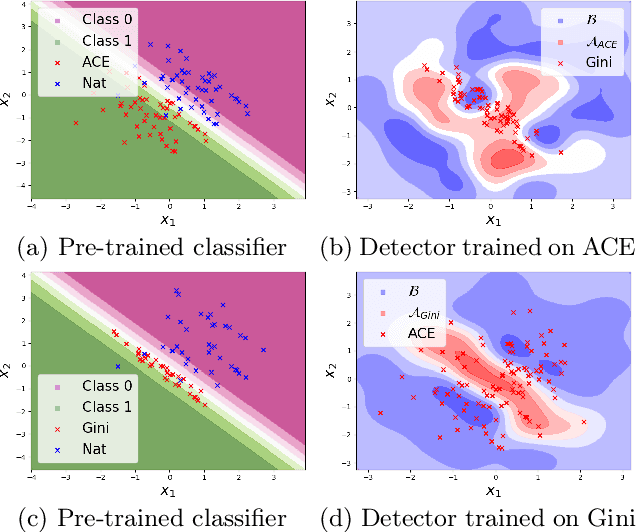
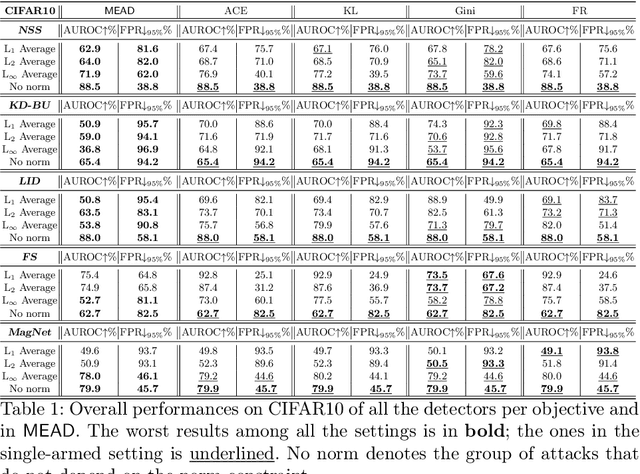
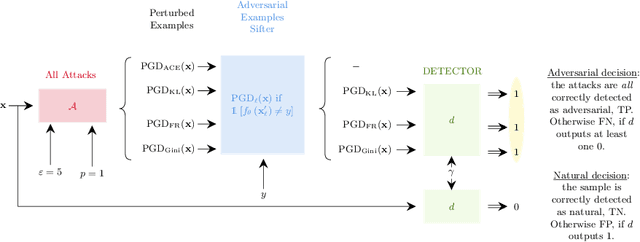
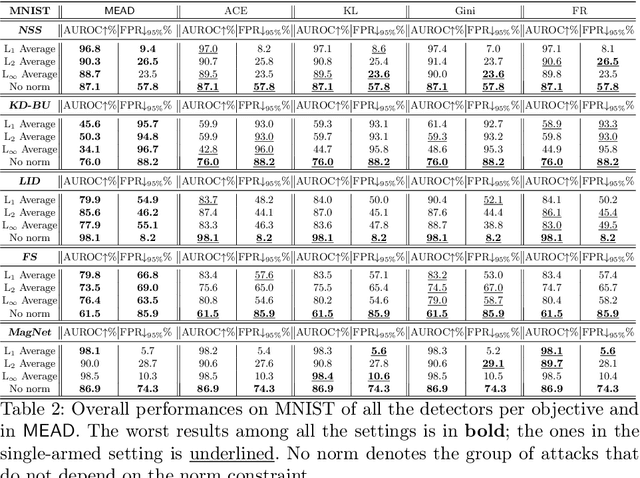
Detection of adversarial examples has been a hot topic in the last years due to its importance for safely deploying machine learning algorithms in critical applications. However, the detection methods are generally validated by assuming a single implicitly known attack strategy, which does not necessarily account for real-life threats. Indeed, this can lead to an overoptimistic assessment of the detectors' performance and may induce some bias in the comparison between competing detection schemes. We propose a novel multi-armed framework, called MEAD, for evaluating detectors based on several attack strategies to overcome this limitation. Among them, we make use of three new objectives to generate attacks. The proposed performance metric is based on the worst-case scenario: detection is successful if and only if all different attacks are correctly recognized. Empirically, we show the effectiveness of our approach. Moreover, the poor performance obtained for state-of-the-art detectors opens a new exciting line of research.
DOCTOR: A Simple Method for Detecting Misclassification Errors
Jun 04, 2021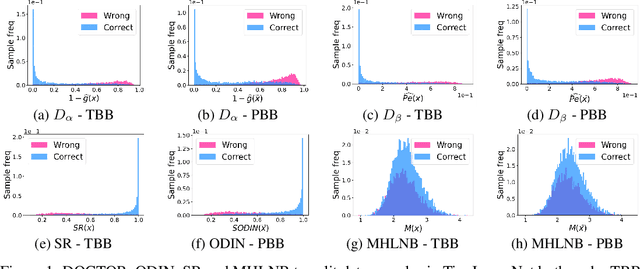
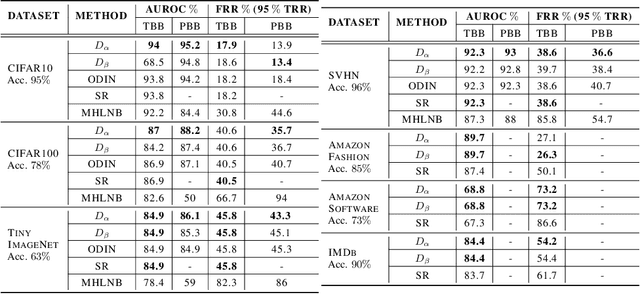
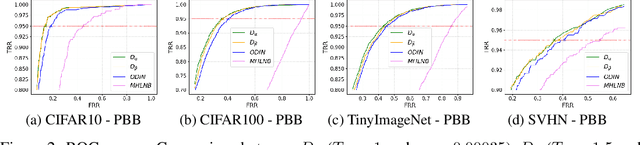
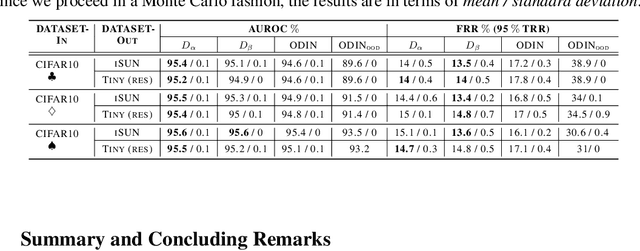
Deep neural networks (DNNs) have shown to perform very well on large scale object recognition problems and lead to widespread use for real-world applications, including situations where DNN are implemented as "black boxes". A promising approach to secure their use is to accept decisions that are likely to be correct while discarding the others. In this work, we propose DOCTOR, a simple method that aims to identify whether the prediction of a DNN classifier should (or should not) be trusted so that, consequently, it would be possible to accept it or to reject it. Two scenarios are investigated: Totally Black Box (TBB) where only the soft-predictions are available and Partially Black Box (PBB) where gradient-propagation to perform input pre-processing is allowed. Empirically, we show that DOCTOR outperforms all state-of-the-art methods on various well-known images and sentiment analysis datasets. In particular, we observe a reduction of up to $4\%$ of the false rejection rate (FRR) in the PBB scenario. DOCTOR can be applied to any pre-trained model, it does not require prior information about the underlying dataset and is as simple as the simplest available methods in the literature.