 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-optimality bounds for certainty equivalent policies in partially observed systems
Feb 02, 2026In this paper, we present a generalization of the certainty equivalence principle of stochastic control. One interpretation of the classical certainty equivalence principle for linear systems with output feedback and quadratic costs is as follows: the optimal action at each time is obtained by evaluating the optimal state-feedback policy of the stochastic linear system at the minimum mean square error (MMSE) estimate of the state. Motivated by this interpretation, we consider certainty equivalent policies for general (non-linear) partially observed stochastic systems that allow for any state estimate rather than restricting to MMSE estimates. In such settings, the certainty equivalent policy is not optimal. For models where the cost and the dynamics are smooth in an appropriate sense, we derive upper bounds on the sub-optimality of certainty equivalent policies. We present several examples to illustrate the results.
MTLoc: A Confidence-Based Source-Free Domain Adaptation Approach For Indoor Localization
Mar 18, 2025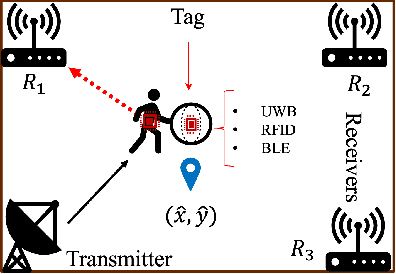
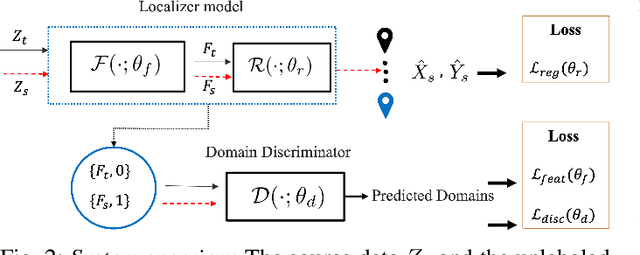
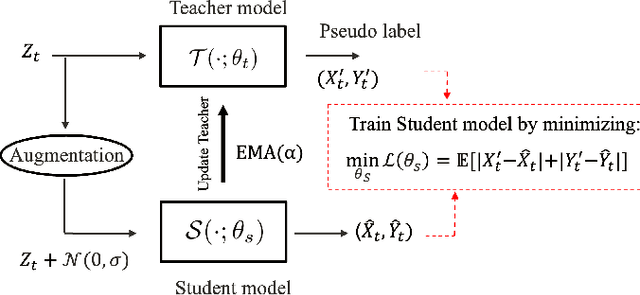
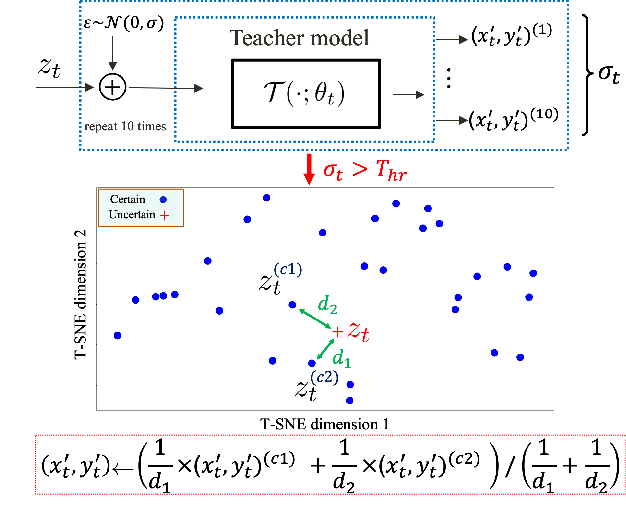
Various deep learning models have been developed for indoor localization based on radio-frequency identification (RFID) tags. However, they often require adaptation to ensure accurate tracking in new target operational domains. To address this challenge, unsupervised domain adaptation (UDA) methods have been proposed to align pre-trained models with data from target environments. However, they rely on large annotated datasets from the initial domain (source). Source data access is limited by privacy, storage, computational, and transfer constraints. Although many source-free domain adaptation (SFDA) methods address these constraints in classification, applying them to regression models for localization remains challenging. Indeed, target datasets for indoor localization are typically small, with few features and samples, and are noisy. Adapting regression models requires high-confidence target pseudo-annotation to avoid over-training. In this paper, a specialized mean-teacher method called MTLoc is proposed for SFDA. MTLoc updates the student network using noisy data and teacher-generated pseudo-labels. The teacher network maintains stability through exponential moving averages. To further ensure robustness, the teacher's pseudo-labels are refined using k-nearest neighbor correction. MTLoc allows for self-supervised learning on target data, facilitating effective adaptation to dynamic and noisy indoor environments. Validated using real-world data from our experimental setup with INLAN Inc., our results show that MTLoc achieves high localization accuracy under challenging conditions, significantly reducing localization error compared to baselines, including the state-of-the-art adversarial UDA approach with access to source data.
Model approximation in MDPs with unbounded per-step cost
Feb 13, 2024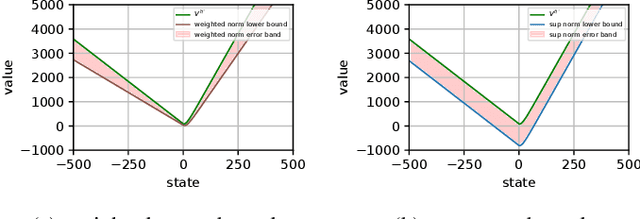
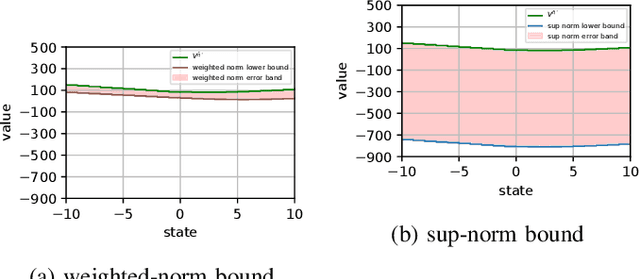

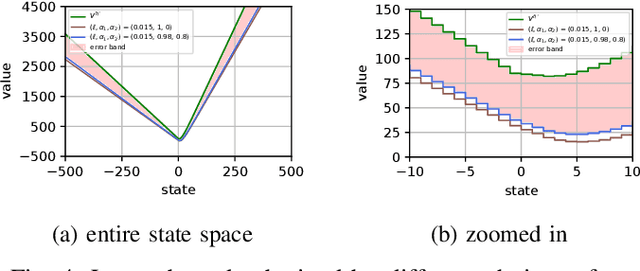
We consider the problem of designing a control policy for an infinite-horizon discounted cost Markov decision process $\mathcal{M}$ when we only have access to an approximate model $\hat{\mathcal{M}}$. How well does an optimal policy $\hat{\pi}^{\star}$ of the approximate model perform when used in the original model $\mathcal{M}$? We answer this question by bounding a weighted norm of the difference between the value function of $\hat{\pi}^\star $ when used in $\mathcal{M}$ and the optimal value function of $\mathcal{M}$. We then extend our results and obtain potentially tighter upper bounds by considering affine transformations of the per-step cost. We further provide upper bounds that explicitly depend on the weighted distance between cost functions and weighted distance between transition kernels of the original and approximate models. We present examples to illustrate our results.