 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Lightweight Neural Animation : Exploration of Neural Network Pruning in Mixture of Experts-based Animation Models
Paper and Code
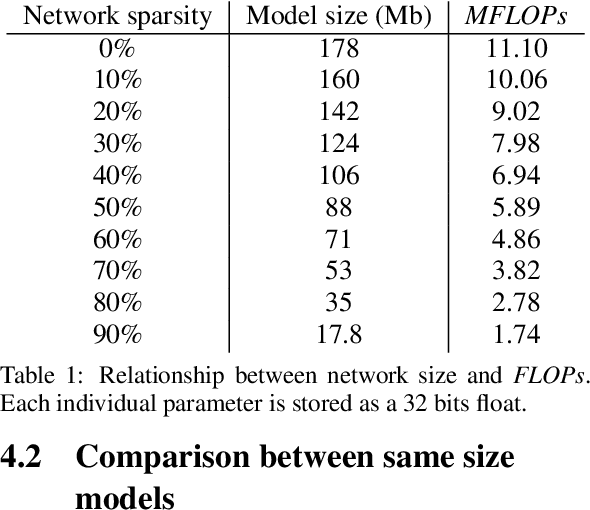
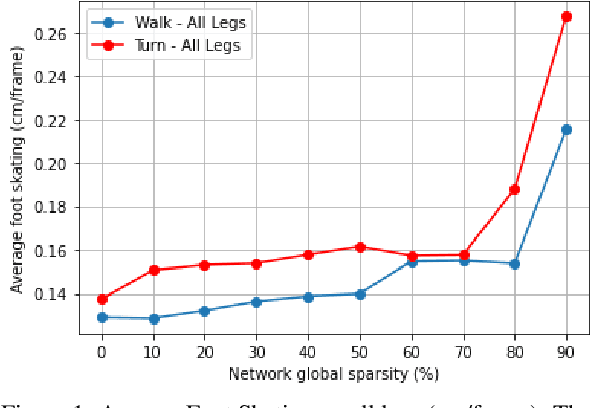


In the past few years, neural character animation has emerged and offered an automatic method for animating virtual characters. Their motion is synthesized by a neural network. Controlling this movement in real time with a user-defined control signal is also an important task in video games for example. Solutions based on fully-connected layers (MLPs) and Mixture-of-Experts (MoE) have given impressive results in generating and controlling various movements with close-range interactions between the environment and the virtual character. However, a major shortcoming of fully-connected layers is their computational and memory cost which may lead to sub-optimized solution. In this work, we apply pruning algorithms to compress an MLP- MoE neural network in the context of interactive character animation, which reduces its number of parameters and accelerates its computation time with a trade-off between this acceleration and the synthesized motion quality. This work demonstrates that, with the same number of experts and parameters, the pruned model produces less motion artifacts than the dense model and the learned high-level motion features are similar for both