 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeeMotion-GAN: A Motion-based GAN for Photorealistic and Facial Expression Preserving Frontal View Synthesis
Apr 15, 2024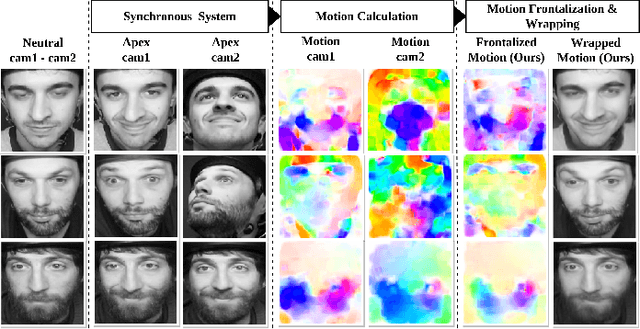

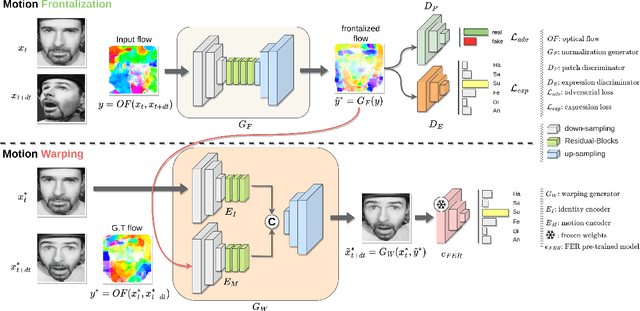
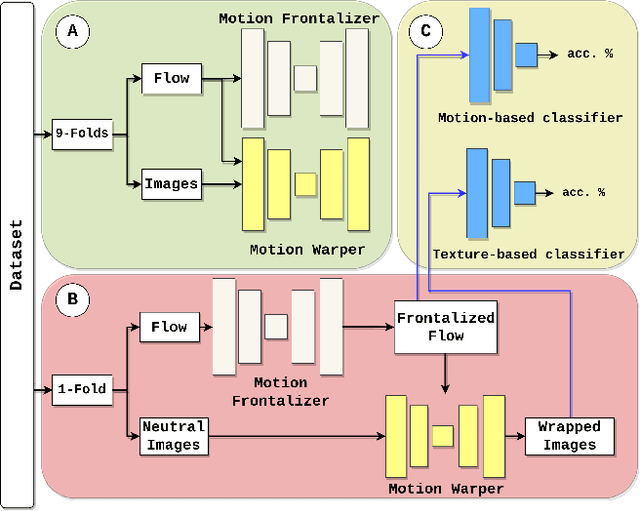
Many existing facial expression recognition (FER) systems encounter substantial performance degradation when faced with variations in head pose. Numerous frontalization methods have been proposed to enhance these systems' performance under such conditions. However, they often introduce undesirable deformations, rendering them less suitable for precise facial expression analysis. In this paper, we present eMotion-GAN, a novel deep learning approach designed for frontal view synthesis while preserving facial expressions within the motion domain. Considering the motion induced by head variation as noise and the motion induced by facial expression as the relevant information, our model is trained to filter out the noisy motion in order to retain only the motion related to facial expression. The filtered motion is then mapped onto a neutral frontal face to generate the corresponding expressive frontal face. We conducted extensive evaluations using several widely recognized dynamic FER datasets, which encompass sequences exhibiting various degrees of head pose variations in both intensity and orientation. Our results demonstrate the effectiveness of our approach in significantly reducing the FER performance gap between frontal and non-frontal faces. Specifically, we achieved a FER improvement of up to +5\% for small pose variations and up to +20\% improvement for larger pose variations. Code available at \url{https://github.com/o-ikne/eMotion-GAN.git}.
Windowed-FourierMixer: Enhancing Clutter-Free Room Modeling with Fourier Transform
Feb 28, 2024With the growing demand for immersive digital applications, the need to understand and reconstruct 3D scenes has significantly increased. In this context, inpainting indoor environments from a single image plays a crucial role in modeling the internal structure of interior spaces as it enables the creation of textured and clutter-free reconstructions. While recent methods have shown significant progress in room modeling, they rely on constraining layout estimators to guide the reconstruction process. These methods are highly dependent on the performance of the structure estimator and its generative ability in heavily occluded environments. In response to these issues, we propose an innovative approach based on a U-Former architecture and a new Windowed-FourierMixer block, resulting in a unified, single-phase network capable of effectively handle human-made periodic structures such as indoor spaces. This new architecture proves advantageous for tasks involving indoor scenes where symmetry is prevalent, allowing the model to effectively capture features such as horizon/ceiling height lines and cuboid-shaped rooms. Experiments show the proposed approach outperforms current state-of-the-art methods on the Structured3D dataset demonstrating superior performance in both quantitative metrics and qualitative results. Code and models will be made publicly available.
Spiking-Fer: Spiking Neural Network for Facial Expression Recognition With Event Cameras
Apr 20, 2023Facial Expression Recognition (FER) is an active research domain that has shown great progress recently, notably thanks to the use of large deep learning models. However, such approaches are particularly energy intensive, which makes their deployment difficult for edge devices. To address this issue, Spiking Neural Networks (SNNs) coupled with event cameras are a promising alternative, capable of processing sparse and asynchronous events with lower energy consumption. In this paper, we establish the first use of event cameras for FER, named "Event-based FER", and propose the first related benchmarks by converting popular video FER datasets to event streams. To deal with this new task, we propose "Spiking-FER", a deep convolutional SNN model, and compare it against a similar Artificial Neural Network (ANN). Experiments show that the proposed approach achieves comparable performance to the ANN architecture, while consuming less energy by orders of magnitude (up to 65.39x). In addition, an experimental study of various event-based data augmentation techniques is performed to provide insights into the efficient transformations specific to event-based FER.
Dynamic Facial Expression Recognition under Partial Occlusion with Optical Flow Reconstruction
Dec 24, 2020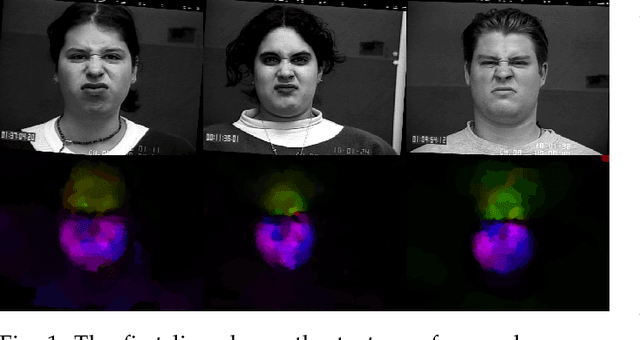
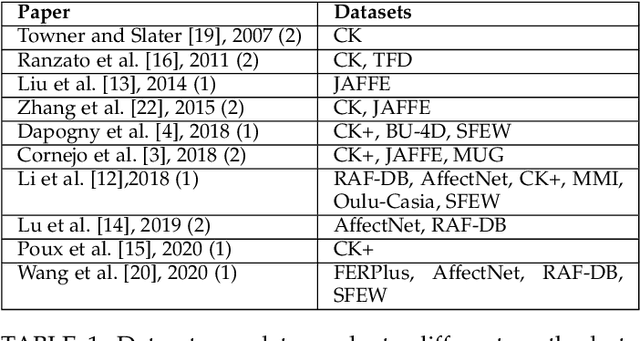
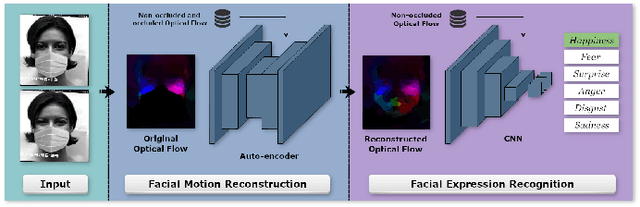
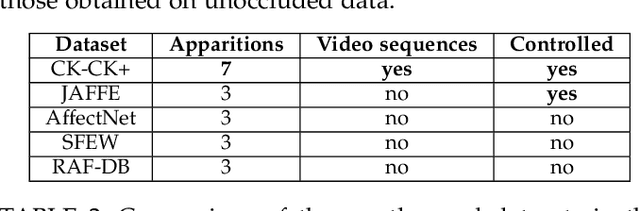
Video facial expression recognition is useful for many applications and received much interest lately. Although some solutions give really good results in a controlled environment (no occlusion), recognition in the presence of partial facial occlusion remains a challenging task. To handle occlusions, solutions based on the reconstruction of the occluded part of the face have been proposed. These solutions are mainly based on the texture or the geometry of the face. However, the similarity of the face movement between different persons doing the same expression seems to be a real asset for the reconstruction. In this paper we exploit this asset and propose a new solution based on an auto-encoder with skip connections to reconstruct the occluded part of the face in the optical flow domain. To the best of our knowledge, this is the first proposition to directly reconstruct the movement for facial expression recognition. We validated our approach in the controlled dataset CK+ on which different occlusions were generated. Our experiments show that the proposed method reduce significantly the gap, in terms of recognition accuracy, between occluded and non-occluded situations. We also compare our approach with existing state-of-the-art solutions. In order to lay the basis of a reproducible and fair comparison in the future, we also propose a new experimental protocol that includes occlusion generation and reconstruction evaluation.
What is the relationship between face alignment and facial expression recognition?
May 26, 2019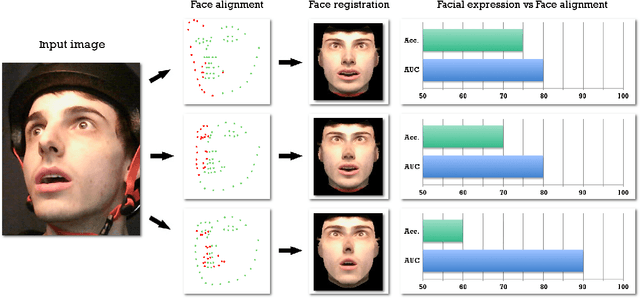
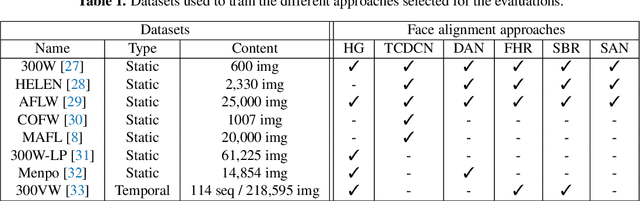

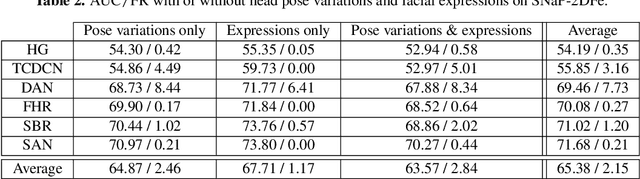
Face expression recognition is still a complex task, particularly due to the presence of head pose variations. Although face alignment approaches are becoming increasingly accurate for characterizing facial regions, it is important to consider the impact of these approaches when they are used for other related tasks such as head pose registration or facial expression recognition. In this paper, we compare the performance of recent face alignment approaches to highlight the most appropriate techniques for preserving facial geometry when correcting the head pose variation. Also, we highlight the most suitable techniques that locate facial landmarks in the presence of head pose variations and facial expressions.
Facial Expressions Analysis Under Occlusions Based on Specificities of Facial Motion Propagation
Apr 30, 2019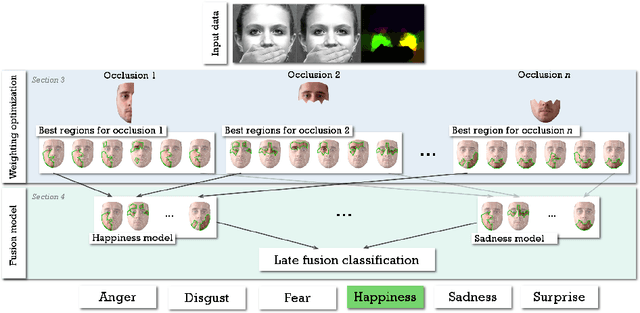

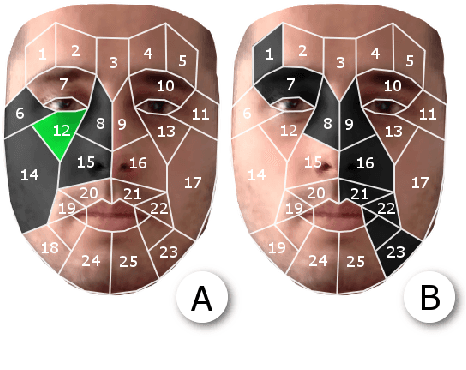
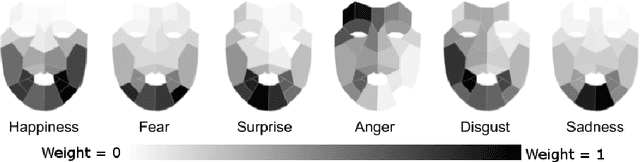
Although much progress has been made in the facial expression analysis field, facial occlusions are still challenging. The main innovation brought by this contribution consists in exploiting the specificities of facial movement propagation for recognizing expressions in presence of important occlusions. The movement induced by an expression extends beyond the movement epicenter. Thus, the movement occurring in an occluded region propagates towards neighboring visible regions. In presence of occlusions, per expression, we compute the importance of each unoccluded facial region and we construct adapted facial frameworks that boost the performance of per expression binary classifier. The output of each expression-dependant binary classifier is then aggregated and fed into a fusion process that aims constructing, per occlusion, a unique model that recognizes all the facial expressions considered. The evaluations highlight the robustness of this approach in presence of significant facial occlusions.
Optical Flow Techniques for Facial Expression Analysis: Performance Evaluation and Improvements
Apr 25, 2019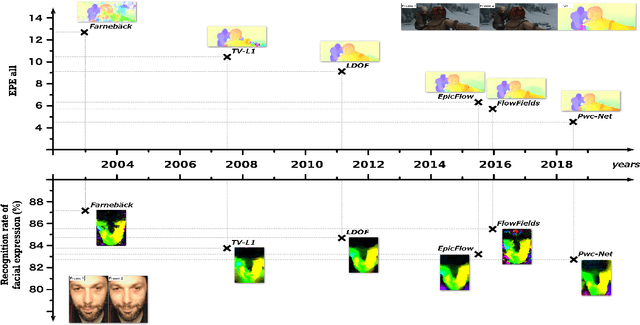


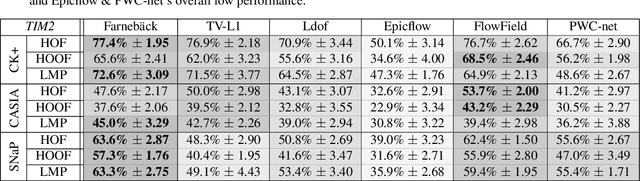
Optical flow techniques are becoming increasingly performant and robust when estimating motion in a scene, but their performance has yet to be proven in the area of facial expression recognition. In this work, a variety of optical flow approaches are evaluated across multiple facial expression datasets, so as to provide a consistent performance evaluation. Additionally, the strengths of multiple optical flow approaches are combined in a novel data augmentation scheme. Under this scheme, increases in average accuracy of up to 6% (depending on the choice of optical flow approaches and dataset) have been achieved.