 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Facial Expression Recognition under Partial Occlusion with Optical Flow Reconstruction
Dec 24, 2020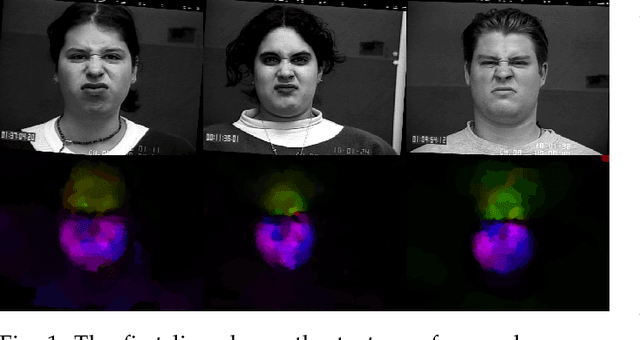
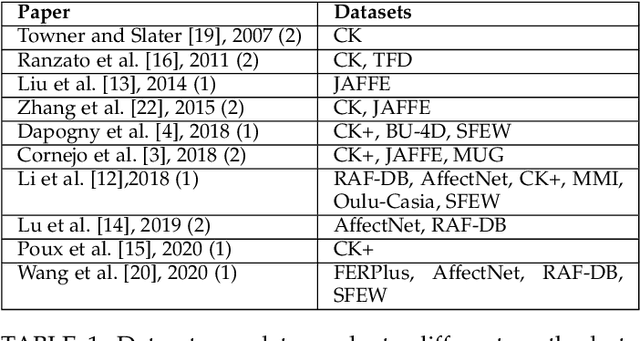
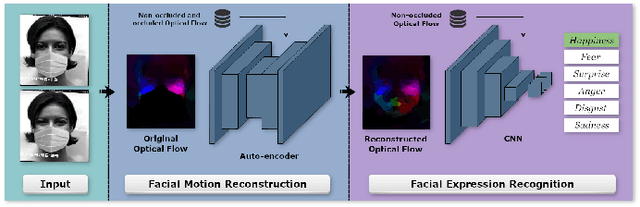
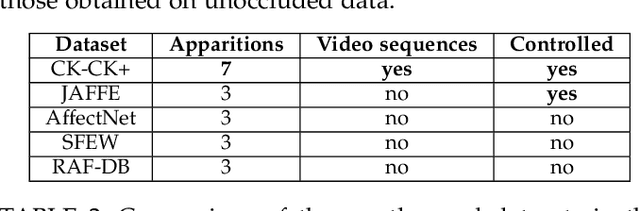
Video facial expression recognition is useful for many applications and received much interest lately. Although some solutions give really good results in a controlled environment (no occlusion), recognition in the presence of partial facial occlusion remains a challenging task. To handle occlusions, solutions based on the reconstruction of the occluded part of the face have been proposed. These solutions are mainly based on the texture or the geometry of the face. However, the similarity of the face movement between different persons doing the same expression seems to be a real asset for the reconstruction. In this paper we exploit this asset and propose a new solution based on an auto-encoder with skip connections to reconstruct the occluded part of the face in the optical flow domain. To the best of our knowledge, this is the first proposition to directly reconstruct the movement for facial expression recognition. We validated our approach in the controlled dataset CK+ on which different occlusions were generated. Our experiments show that the proposed method reduce significantly the gap, in terms of recognition accuracy, between occluded and non-occluded situations. We also compare our approach with existing state-of-the-art solutions. In order to lay the basis of a reproducible and fair comparison in the future, we also propose a new experimental protocol that includes occlusion generation and reconstruction evaluation.
Facial Expressions Analysis Under Occlusions Based on Specificities of Facial Motion Propagation
Apr 30, 2019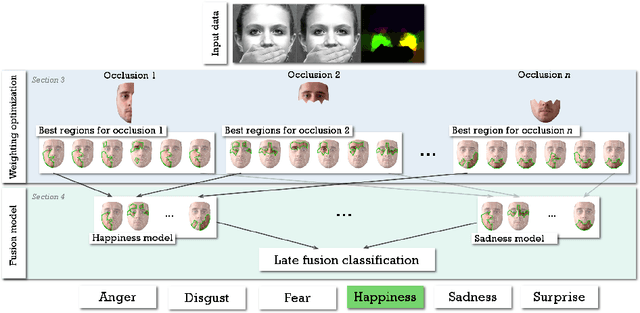

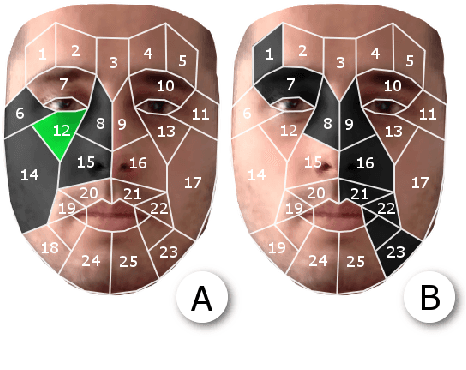
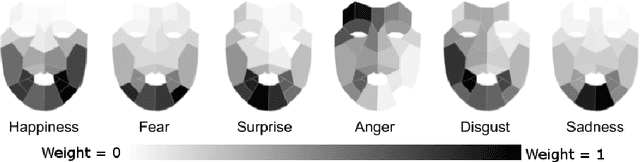
Although much progress has been made in the facial expression analysis field, facial occlusions are still challenging. The main innovation brought by this contribution consists in exploiting the specificities of facial movement propagation for recognizing expressions in presence of important occlusions. The movement induced by an expression extends beyond the movement epicenter. Thus, the movement occurring in an occluded region propagates towards neighboring visible regions. In presence of occlusions, per expression, we compute the importance of each unoccluded facial region and we construct adapted facial frameworks that boost the performance of per expression binary classifier. The output of each expression-dependant binary classifier is then aggregated and fed into a fusion process that aims constructing, per occlusion, a unique model that recognizes all the facial expressions considered. The evaluations highlight the robustness of this approach in presence of significant facial occlusions.