 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrozen Backpropagation: Relaxing Weight Symmetry in Temporally-Coded Deep Spiking Neural Networks
May 19, 2025



Direct training of Spiking Neural Networks (SNNs) on neuromorphic hardware can greatly reduce energy costs compared to GPU-based training. However, implementing Backpropagation (BP) on such hardware is challenging because forward and backward passes are typically performed by separate networks with distinct weights. To compute correct gradients, forward and feedback weights must remain symmetric during training, necessitating weight transport between the two networks. This symmetry requirement imposes hardware overhead and increases energy costs. To address this issue, we introduce Frozen Backpropagation (fBP), a BP-based training algorithm relaxing weight symmetry in settings with separate networks. fBP updates forward weights by computing gradients with periodically frozen feedback weights, reducing weight transports during training and minimizing synchronization overhead. To further improve transport efficiency, we propose three partial weight transport schemes of varying computational complexity, where only a subset of weights is transported at a time. We evaluate our methods on image recognition tasks and compare them to existing approaches addressing the weight symmetry requirement. Our results show that fBP outperforms these methods and achieves accuracy comparable to BP. With partial weight transport, fBP can substantially lower transport costs by 1,000x with an accuracy drop of only 0.5pp on CIFAR-10 and 1.1pp on CIFAR-100, or by up to 10,000x at the expense of moderated accuracy loss. This work provides insights for guiding the design of neuromorphic hardware incorporating BP-based on-chip learning.
Neuronal Competition Groups with Supervised STDP for Spike-Based Classification
Oct 22, 2024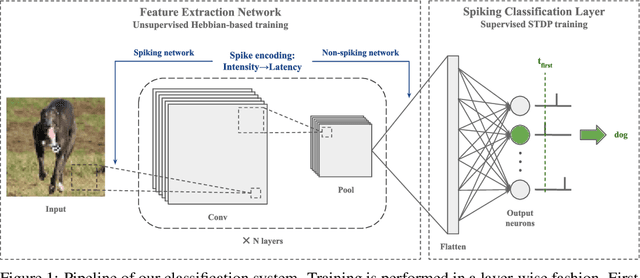
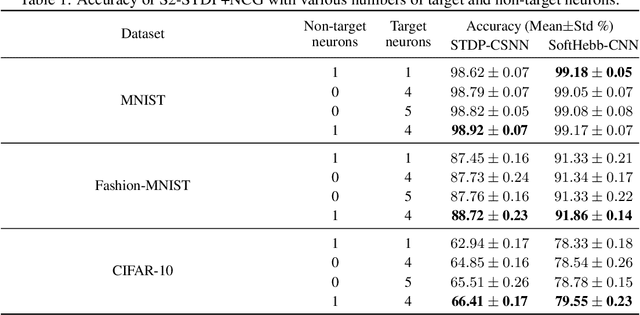
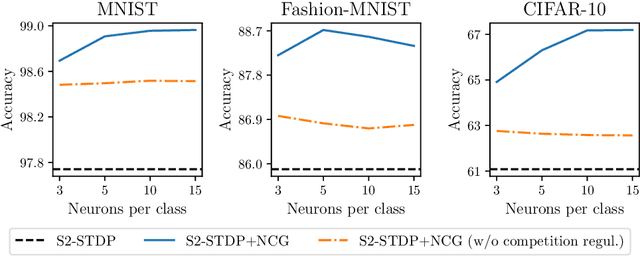
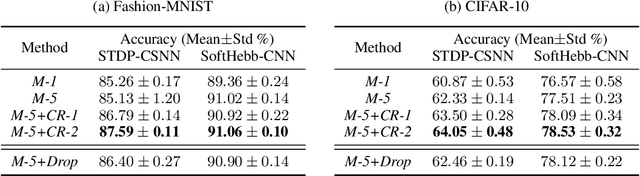
Spike Timing-Dependent Plasticity (STDP) is a promising substitute to backpropagation for local training of Spiking Neural Networks (SNNs) on neuromorphic hardware. STDP allows SNNs to address classification tasks by combining unsupervised STDP for feature extraction and supervised STDP for classification. Unsupervised STDP is usually employed with Winner-Takes-All (WTA) competition to learn distinct patterns. However, WTA for supervised STDP classification faces unbalanced competition challenges. In this paper, we propose a method to effectively implement WTA competition in a spiking classification layer employing first-spike coding and supervised STDP training. We introduce the Neuronal Competition Group (NCG), an architecture that improves classification capabilities by promoting the learning of various patterns per class. An NCG is a group of neurons mapped to a specific class, implementing intra-class WTA and a novel competition regulation mechanism based on two-compartment thresholds. We incorporate our proposed architecture into spiking classification layers trained with state-of-the-art supervised STDP rules. On top of two different unsupervised feature extractors, we obtain significant accuracy improvements on image recognition datasets such as CIFAR-10 and CIFAR-100. We show that our competition regulation mechanism is crucial for ensuring balanced competition and improved class separation.
Model for Peanuts: Hijacking ML Models without Training Access is Possible
Jun 03, 2024



The massive deployment of Machine Learning (ML) models has been accompanied by the emergence of several attacks that threaten their trustworthiness and raise ethical and societal concerns such as invasion of privacy, discrimination risks, and lack of accountability. Model hijacking is one of these attacks, where the adversary aims to hijack a victim model to execute a different task than its original one. Model hijacking can cause accountability and security risks since a hijacked model owner can be framed for having their model offering illegal or unethical services. Prior state-of-the-art works consider model hijacking as a training time attack, whereby an adversary requires access to the ML model training to execute their attack. In this paper, we consider a stronger threat model where the attacker has no access to the training phase of the victim model. Our intuition is that ML models, typically over-parameterized, might (unintentionally) learn more than the intended task for they are trained. We propose a simple approach for model hijacking at inference time named SnatchML to classify unknown input samples using distance measures in the latent space of the victim model to previously known samples associated with the hijacking task classes. SnatchML empirically shows that benign pre-trained models can execute tasks that are semantically related to the initial task. Surprisingly, this can be true even for hijacking tasks unrelated to the original task. We also explore different methods to mitigate this risk. We first propose a novel approach we call meta-unlearning, designed to help the model unlearn a potentially malicious task while training on the original task dataset. We also provide insights on over-parameterization as one possible inherent factor that makes model hijacking easier, and we accordingly propose a compression-based countermeasure against this attack.
eMotion-GAN: A Motion-based GAN for Photorealistic and Facial Expression Preserving Frontal View Synthesis
Apr 15, 2024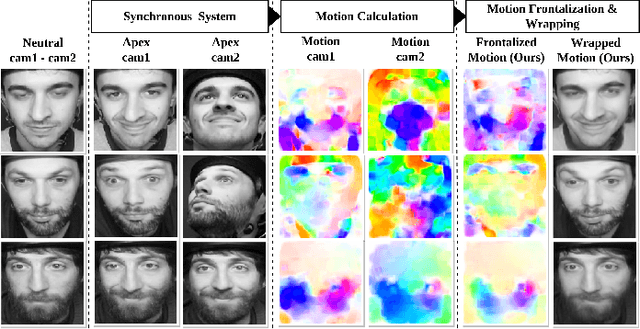

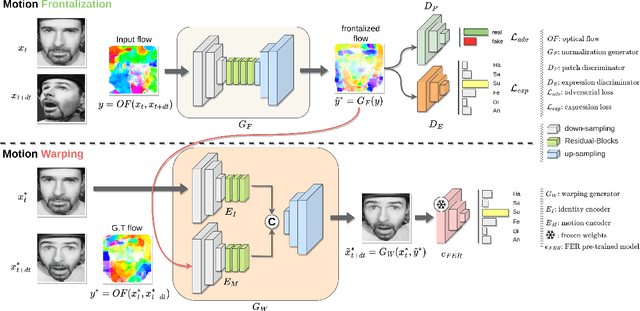
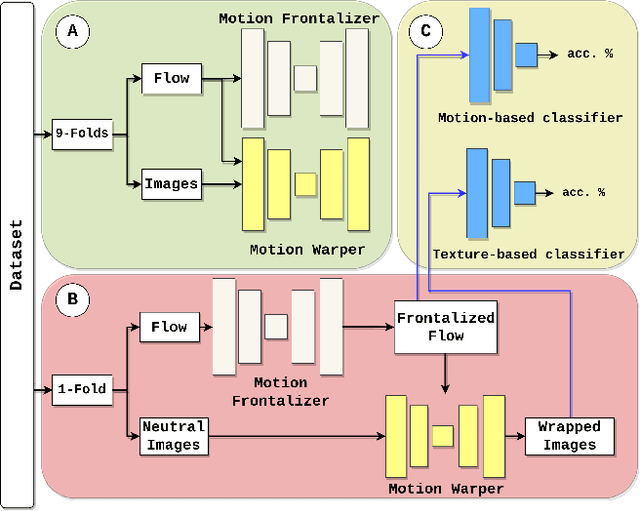
Many existing facial expression recognition (FER) systems encounter substantial performance degradation when faced with variations in head pose. Numerous frontalization methods have been proposed to enhance these systems' performance under such conditions. However, they often introduce undesirable deformations, rendering them less suitable for precise facial expression analysis. In this paper, we present eMotion-GAN, a novel deep learning approach designed for frontal view synthesis while preserving facial expressions within the motion domain. Considering the motion induced by head variation as noise and the motion induced by facial expression as the relevant information, our model is trained to filter out the noisy motion in order to retain only the motion related to facial expression. The filtered motion is then mapped onto a neutral frontal face to generate the corresponding expressive frontal face. We conducted extensive evaluations using several widely recognized dynamic FER datasets, which encompass sequences exhibiting various degrees of head pose variations in both intensity and orientation. Our results demonstrate the effectiveness of our approach in significantly reducing the FER performance gap between frontal and non-frontal faces. Specifically, we achieved a FER improvement of up to +5\% for small pose variations and up to +20\% improvement for larger pose variations. Code available at \url{https://github.com/o-ikne/eMotion-GAN.git}.
S3TC: Spiking Separated Spatial and Temporal Convolutions with Unsupervised STDP-based Learning for Action Recognition
Sep 22, 2023



Video analysis is a major computer vision task that has received a lot of attention in recent years. The current state-of-the-art performance for video analysis is achieved with Deep Neural Networks (DNNs) that have high computational costs and need large amounts of labeled data for training. Spiking Neural Networks (SNNs) have significantly lower computational costs (thousands of times) than regular non-spiking networks when implemented on neuromorphic hardware. They have been used for video analysis with methods like 3D Convolutional Spiking Neural Networks (3D CSNNs). However, these networks have a significantly larger number of parameters compared with spiking 2D CSNN. This, not only increases the computational costs, but also makes these networks more difficult to implement with neuromorphic hardware. In this work, we use CSNNs trained in an unsupervised manner with the Spike Timing-Dependent Plasticity (STDP) rule, and we introduce, for the first time, Spiking Separated Spatial and Temporal Convolutions (S3TCs) for the sake of reducing the number of parameters required for video analysis. This unsupervised learning has the advantage of not needing large amounts of labeled data for training. Factorizing a single spatio-temporal spiking convolution into a spatial and a temporal spiking convolution decreases the number of parameters of the network. We test our network with the KTH, Weizmann, and IXMAS datasets, and we show that S3TCs successfully extract spatio-temporal information from videos, while increasing the output spiking activity, and outperforming spiking 3D convolutions.
Paired Competing Neurons Improving STDP Supervised Local Learning In Spiking Neural Networks
Aug 04, 2023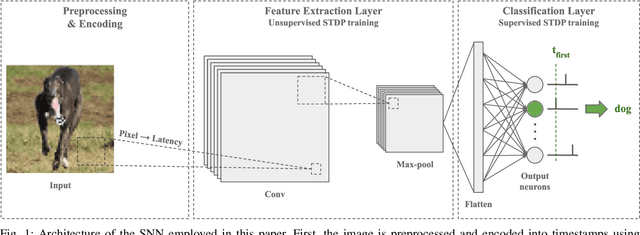
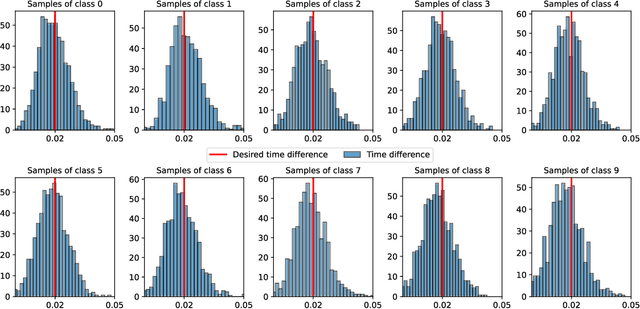
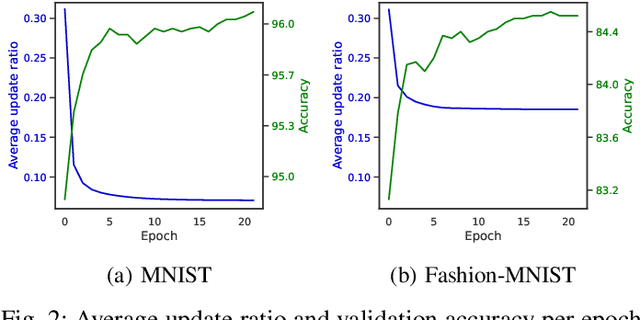
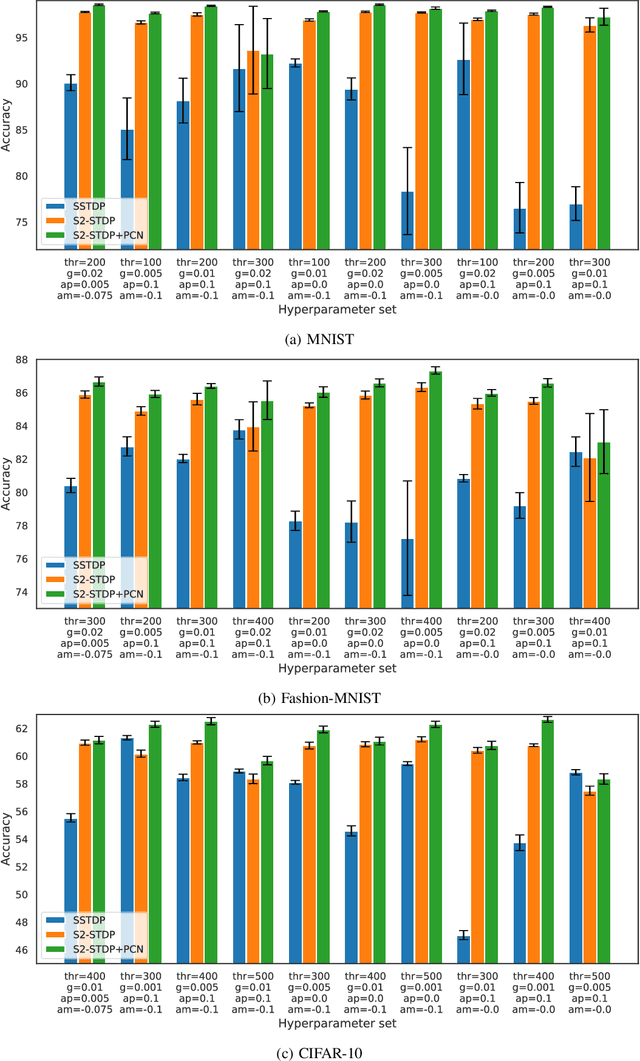
Direct training of Spiking Neural Networks (SNNs) on neuromorphic hardware has the potential to significantly reduce the high energy consumption of Artificial Neural Networks (ANNs) training on modern computers. The biological plausibility of SNNs allows them to benefit from bio-inspired plasticity rules, such as Spike Timing-Dependent Plasticity (STDP). STDP offers gradient-free and unsupervised local learning, which can be easily implemented on neuromorphic hardware. However, relying solely on unsupervised STDP to perform classification tasks is not enough. In this paper, we propose Stabilized Supervised STDP (S2-STDP), a supervised STDP learning rule to train the classification layer of an SNN equipped with unsupervised STDP. S2-STDP integrates error-modulated weight updates that align neuron spikes with desired timestamps derived from the average firing time within the layer. Then, we introduce a training architecture called Paired Competing Neurons (PCN) to further enhance the learning capabilities of our classification layer trained with S2-STDP. PCN associates each class with paired neurons and encourages neuron specialization through intra-class competition. We evaluated our proposed methods on image recognition datasets, including MNIST, Fashion-MNIST, and CIFAR-10. Results showed that our methods outperform current supervised STDP-based state of the art, for comparable architectures and numbers of neurons. Also, the use of PCN enhances the performance of S2-STDP, regardless of the configuration, and without introducing any hyperparameters.Further analysis demonstrated that our methods exhibited improved hyperparameter robustness, which reduces the need for tuning.
Spiking Two-Stream Methods with Unsupervised STDP-based Learning for Action Recognition
Jun 23, 2023



Video analysis is a computer vision task that is useful for many applications like surveillance, human-machine interaction, and autonomous vehicles. Deep Convolutional Neural Networks (CNNs) are currently the state-of-the-art methods for video analysis. However they have high computational costs, and need a large amount of labeled data for training. In this paper, we use Convolutional Spiking Neural Networks (CSNNs) trained with the unsupervised Spike Timing-Dependent Plasticity (STDP) learning rule for action classification. These networks represent the information using asynchronous low-energy spikes. This allows the network to be more energy efficient and neuromorphic hardware-friendly. However, the behaviour of CSNNs is not studied enough with spatio-temporal computer vision models. Therefore, we explore transposing two-stream neural networks into the spiking domain. Implementing this model with unsupervised STDP-based CSNNs allows us to further study the performance of these networks with video analysis. In this work, we show that two-stream CSNNs can successfully extract spatio-temporal information from videos despite using limited training data, and that the spiking spatial and temporal streams are complementary. We also show that using a spatio-temporal stream within a spiking STDP-based two-stream architecture leads to information redundancy and does not improve the performance.
AdvART: Adversarial Art for Camouflaged Object Detection Attacks
Mar 03, 2023



A majority of existing physical attacks in the real world result in conspicuous and eye-catching patterns for generated patches, which made them identifiable/detectable by humans. To overcome this limitation, recent work has proposed several approaches that aim at generating naturalistic patches using generative adversarial networks (GANs), which may not catch human's attention. However, these approaches are computationally intensive and do not always converge to natural looking patterns. In this paper, we propose a novel lightweight framework that systematically generates naturalistic adversarial patches without using GANs. To illustrate the proposed approach, we generate adversarial art (AdvART), which are patches generated to look like artistic paintings while maintaining high attack efficiency. In fact, we redefine the optimization problem by introducing a new similarity objective. Specifically, we leverage similarity metrics to construct a similarity loss that is added to the optimized objective function. This component guides the patch to follow a predefined artistic patterns while maximizing the victim model's loss function. Our patch achieves high success rates with $12.53\%$ mean average precision (mAP) on YOLOv4tiny for INRIA dataset.
2D versus 3D Convolutional Spiking Neural Networks Trained with Unsupervised STDP for Human Action Recognition
May 26, 2022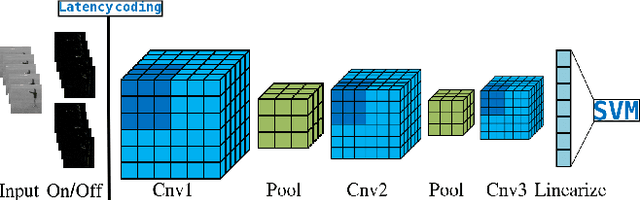
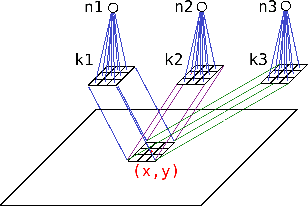


Current advances in technology have highlighted the importance of video analysis in the domain of computer vision. However, video analysis has considerably high computational costs with traditional artificial neural networks (ANNs). Spiking neural networks (SNNs) are third generation biologically plausible models that process the information in the form of spikes. Unsupervised learning with SNNs using the spike timing dependent plasticity (STDP) rule has the potential to overcome some bottlenecks of regular artificial neural networks, but STDP-based SNNs are still immature and their performance is far behind that of ANNs. In this work, we study the performance of SNNs when challenged with the task of human action recognition, because this task has many real-time applications in computer vision, such as video surveillance. In this paper we introduce a multi-layered 3D convolutional SNN model trained with unsupervised STDP. We compare the performance of this model to those of a 2D STDP-based SNN when challenged with the KTH and Weizmann datasets. We also compare single-layer and multi-layer versions of these models in order to get an accurate assessment of their performance. We show that STDP-based convolutional SNNs can learn motion patterns using 3D kernels, thus enabling motion-based recognition from videos. Finally, we give evidence that 3D convolution is superior to 2D convolution with STDP-based SNNs, especially when dealing with long video sequences.
Dynamic Facial Expression Recognition under Partial Occlusion with Optical Flow Reconstruction
Dec 24, 2020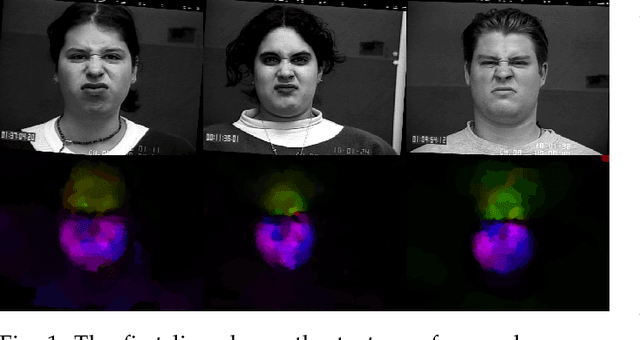
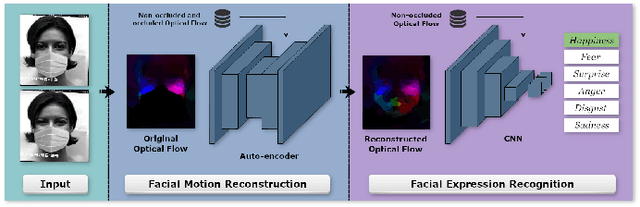
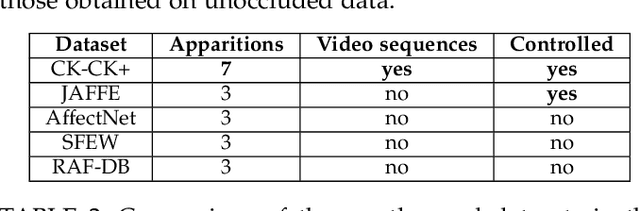
Video facial expression recognition is useful for many applications and received much interest lately. Although some solutions give really good results in a controlled environment (no occlusion), recognition in the presence of partial facial occlusion remains a challenging task. To handle occlusions, solutions based on the reconstruction of the occluded part of the face have been proposed. These solutions are mainly based on the texture or the geometry of the face. However, the similarity of the face movement between different persons doing the same expression seems to be a real asset for the reconstruction. In this paper we exploit this asset and propose a new solution based on an auto-encoder with skip connections to reconstruct the occluded part of the face in the optical flow domain. To the best of our knowledge, this is the first proposition to directly reconstruct the movement for facial expression recognition. We validated our approach in the controlled dataset CK+ on which different occlusions were generated. Our experiments show that the proposed method reduce significantly the gap, in terms of recognition accuracy, between occluded and non-occluded situations. We also compare our approach with existing state-of-the-art solutions. In order to lay the basis of a reproducible and fair comparison in the future, we also propose a new experimental protocol that includes occlusion generation and reconstruction evaluation.