 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrozen Backpropagation: Relaxing Weight Symmetry in Temporally-Coded Deep Spiking Neural Networks
May 19, 2025Direct training of Spiking Neural Networks (SNNs) on neuromorphic hardware can greatly reduce energy costs compared to GPU-based training. However, implementing Backpropagation (BP) on such hardware is challenging because forward and backward passes are typically performed by separate networks with distinct weights. To compute correct gradients, forward and feedback weights must remain symmetric during training, necessitating weight transport between the two networks. This symmetry requirement imposes hardware overhead and increases energy costs. To address this issue, we introduce Frozen Backpropagation (fBP), a BP-based training algorithm relaxing weight symmetry in settings with separate networks. fBP updates forward weights by computing gradients with periodically frozen feedback weights, reducing weight transports during training and minimizing synchronization overhead. To further improve transport efficiency, we propose three partial weight transport schemes of varying computational complexity, where only a subset of weights is transported at a time. We evaluate our methods on image recognition tasks and compare them to existing approaches addressing the weight symmetry requirement. Our results show that fBP outperforms these methods and achieves accuracy comparable to BP. With partial weight transport, fBP can substantially lower transport costs by 1,000x with an accuracy drop of only 0.5pp on CIFAR-10 and 1.1pp on CIFAR-100, or by up to 10,000x at the expense of moderated accuracy loss. This work provides insights for guiding the design of neuromorphic hardware incorporating BP-based on-chip learning.
Neuronal Competition Groups with Supervised STDP for Spike-Based Classification
Oct 22, 2024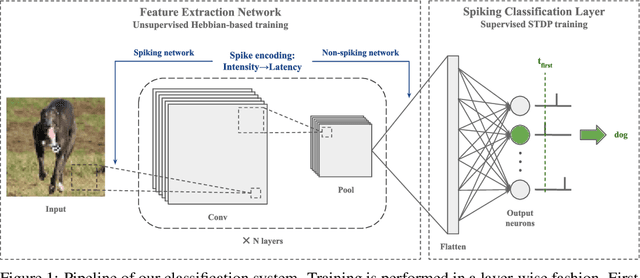
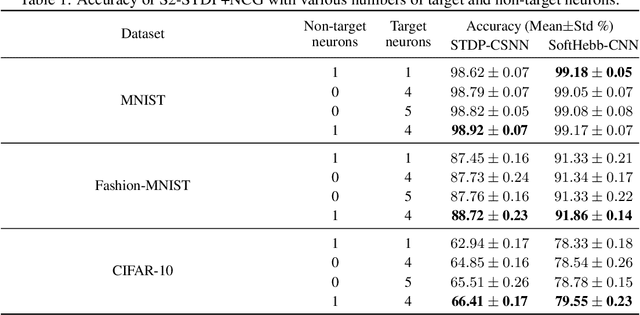
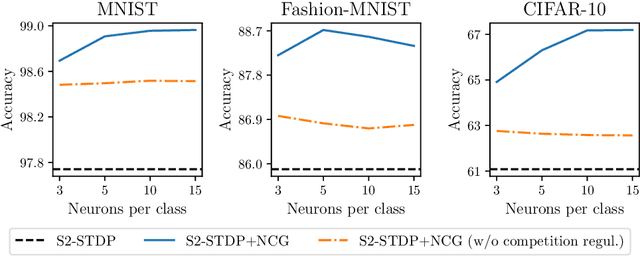
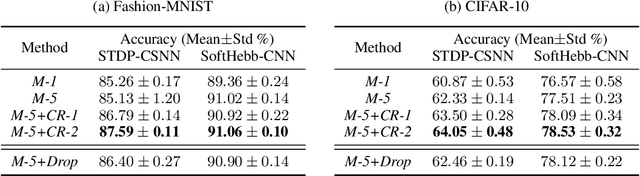
Spike Timing-Dependent Plasticity (STDP) is a promising substitute to backpropagation for local training of Spiking Neural Networks (SNNs) on neuromorphic hardware. STDP allows SNNs to address classification tasks by combining unsupervised STDP for feature extraction and supervised STDP for classification. Unsupervised STDP is usually employed with Winner-Takes-All (WTA) competition to learn distinct patterns. However, WTA for supervised STDP classification faces unbalanced competition challenges. In this paper, we propose a method to effectively implement WTA competition in a spiking classification layer employing first-spike coding and supervised STDP training. We introduce the Neuronal Competition Group (NCG), an architecture that improves classification capabilities by promoting the learning of various patterns per class. An NCG is a group of neurons mapped to a specific class, implementing intra-class WTA and a novel competition regulation mechanism based on two-compartment thresholds. We incorporate our proposed architecture into spiking classification layers trained with state-of-the-art supervised STDP rules. On top of two different unsupervised feature extractors, we obtain significant accuracy improvements on image recognition datasets such as CIFAR-10 and CIFAR-100. We show that our competition regulation mechanism is crucial for ensuring balanced competition and improved class separation.
S3TC: Spiking Separated Spatial and Temporal Convolutions with Unsupervised STDP-based Learning for Action Recognition
Sep 22, 2023



Video analysis is a major computer vision task that has received a lot of attention in recent years. The current state-of-the-art performance for video analysis is achieved with Deep Neural Networks (DNNs) that have high computational costs and need large amounts of labeled data for training. Spiking Neural Networks (SNNs) have significantly lower computational costs (thousands of times) than regular non-spiking networks when implemented on neuromorphic hardware. They have been used for video analysis with methods like 3D Convolutional Spiking Neural Networks (3D CSNNs). However, these networks have a significantly larger number of parameters compared with spiking 2D CSNN. This, not only increases the computational costs, but also makes these networks more difficult to implement with neuromorphic hardware. In this work, we use CSNNs trained in an unsupervised manner with the Spike Timing-Dependent Plasticity (STDP) rule, and we introduce, for the first time, Spiking Separated Spatial and Temporal Convolutions (S3TCs) for the sake of reducing the number of parameters required for video analysis. This unsupervised learning has the advantage of not needing large amounts of labeled data for training. Factorizing a single spatio-temporal spiking convolution into a spatial and a temporal spiking convolution decreases the number of parameters of the network. We test our network with the KTH, Weizmann, and IXMAS datasets, and we show that S3TCs successfully extract spatio-temporal information from videos, while increasing the output spiking activity, and outperforming spiking 3D convolutions.
Paired Competing Neurons Improving STDP Supervised Local Learning In Spiking Neural Networks
Aug 04, 2023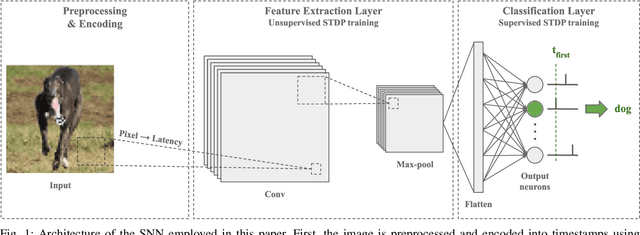
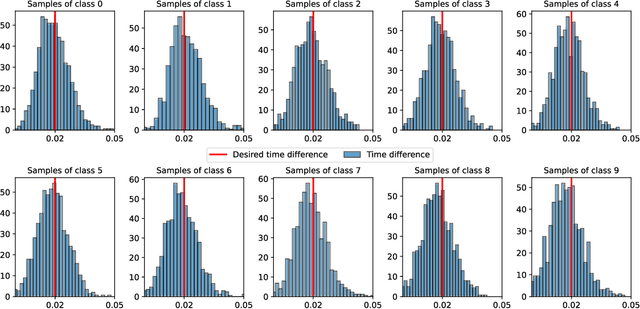
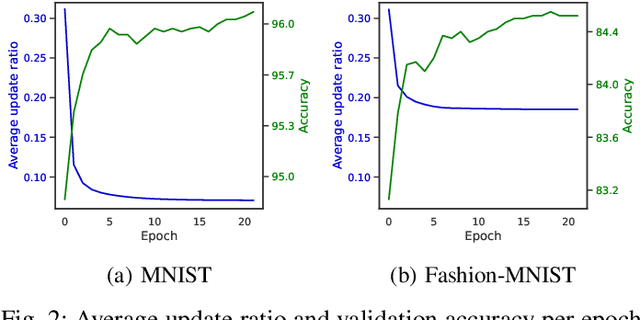
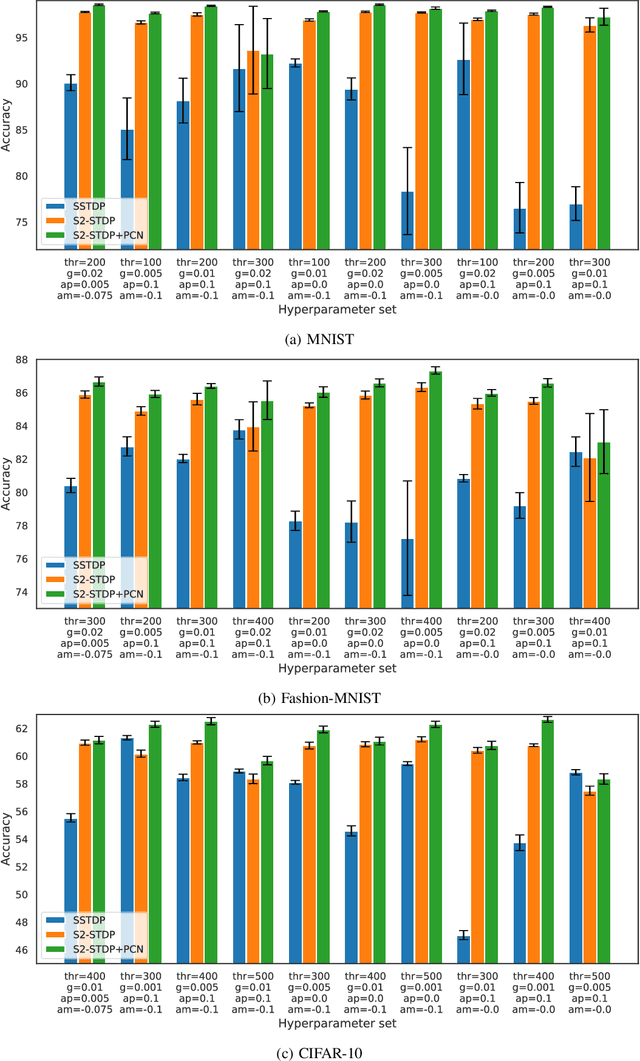
Direct training of Spiking Neural Networks (SNNs) on neuromorphic hardware has the potential to significantly reduce the high energy consumption of Artificial Neural Networks (ANNs) training on modern computers. The biological plausibility of SNNs allows them to benefit from bio-inspired plasticity rules, such as Spike Timing-Dependent Plasticity (STDP). STDP offers gradient-free and unsupervised local learning, which can be easily implemented on neuromorphic hardware. However, relying solely on unsupervised STDP to perform classification tasks is not enough. In this paper, we propose Stabilized Supervised STDP (S2-STDP), a supervised STDP learning rule to train the classification layer of an SNN equipped with unsupervised STDP. S2-STDP integrates error-modulated weight updates that align neuron spikes with desired timestamps derived from the average firing time within the layer. Then, we introduce a training architecture called Paired Competing Neurons (PCN) to further enhance the learning capabilities of our classification layer trained with S2-STDP. PCN associates each class with paired neurons and encourages neuron specialization through intra-class competition. We evaluated our proposed methods on image recognition datasets, including MNIST, Fashion-MNIST, and CIFAR-10. Results showed that our methods outperform current supervised STDP-based state of the art, for comparable architectures and numbers of neurons. Also, the use of PCN enhances the performance of S2-STDP, regardless of the configuration, and without introducing any hyperparameters.Further analysis demonstrated that our methods exhibited improved hyperparameter robustness, which reduces the need for tuning.
Spiking Two-Stream Methods with Unsupervised STDP-based Learning for Action Recognition
Jun 23, 2023



Video analysis is a computer vision task that is useful for many applications like surveillance, human-machine interaction, and autonomous vehicles. Deep Convolutional Neural Networks (CNNs) are currently the state-of-the-art methods for video analysis. However they have high computational costs, and need a large amount of labeled data for training. In this paper, we use Convolutional Spiking Neural Networks (CSNNs) trained with the unsupervised Spike Timing-Dependent Plasticity (STDP) learning rule for action classification. These networks represent the information using asynchronous low-energy spikes. This allows the network to be more energy efficient and neuromorphic hardware-friendly. However, the behaviour of CSNNs is not studied enough with spatio-temporal computer vision models. Therefore, we explore transposing two-stream neural networks into the spiking domain. Implementing this model with unsupervised STDP-based CSNNs allows us to further study the performance of these networks with video analysis. In this work, we show that two-stream CSNNs can successfully extract spatio-temporal information from videos despite using limited training data, and that the spiking spatial and temporal streams are complementary. We also show that using a spatio-temporal stream within a spiking STDP-based two-stream architecture leads to information redundancy and does not improve the performance.
2D versus 3D Convolutional Spiking Neural Networks Trained with Unsupervised STDP for Human Action Recognition
May 26, 2022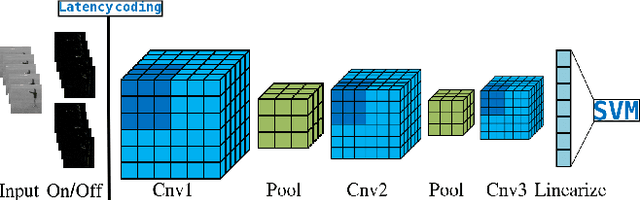
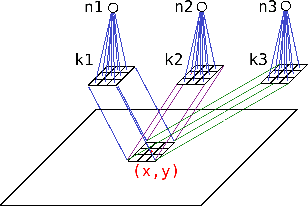


Current advances in technology have highlighted the importance of video analysis in the domain of computer vision. However, video analysis has considerably high computational costs with traditional artificial neural networks (ANNs). Spiking neural networks (SNNs) are third generation biologically plausible models that process the information in the form of spikes. Unsupervised learning with SNNs using the spike timing dependent plasticity (STDP) rule has the potential to overcome some bottlenecks of regular artificial neural networks, but STDP-based SNNs are still immature and their performance is far behind that of ANNs. In this work, we study the performance of SNNs when challenged with the task of human action recognition, because this task has many real-time applications in computer vision, such as video surveillance. In this paper we introduce a multi-layered 3D convolutional SNN model trained with unsupervised STDP. We compare the performance of this model to those of a 2D STDP-based SNN when challenged with the KTH and Weizmann datasets. We also compare single-layer and multi-layer versions of these models in order to get an accurate assessment of their performance. We show that STDP-based convolutional SNNs can learn motion patterns using 3D kernels, thus enabling motion-based recognition from videos. Finally, we give evidence that 3D convolution is superior to 2D convolution with STDP-based SNNs, especially when dealing with long video sequences.
Improving STDP-based Visual Feature Learning with Whitening
Feb 24, 2020
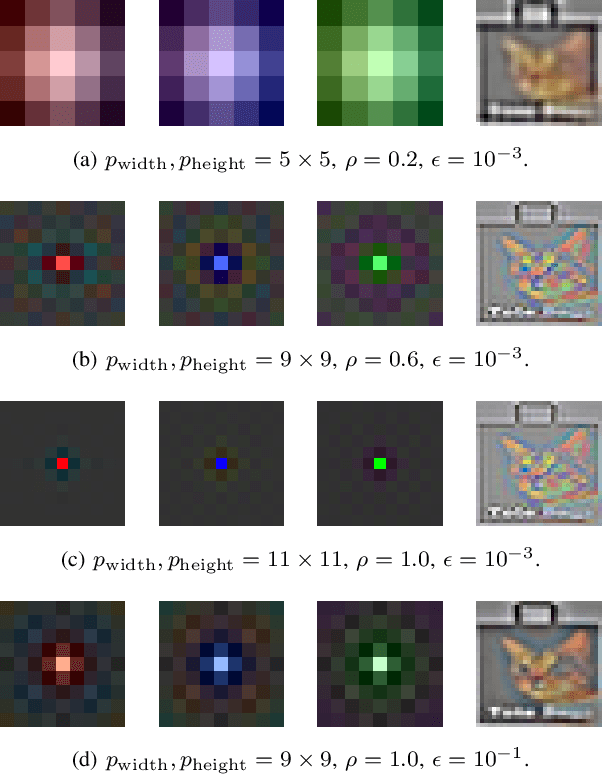
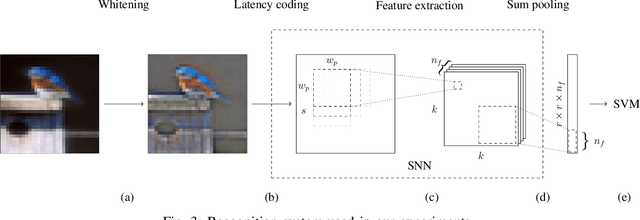
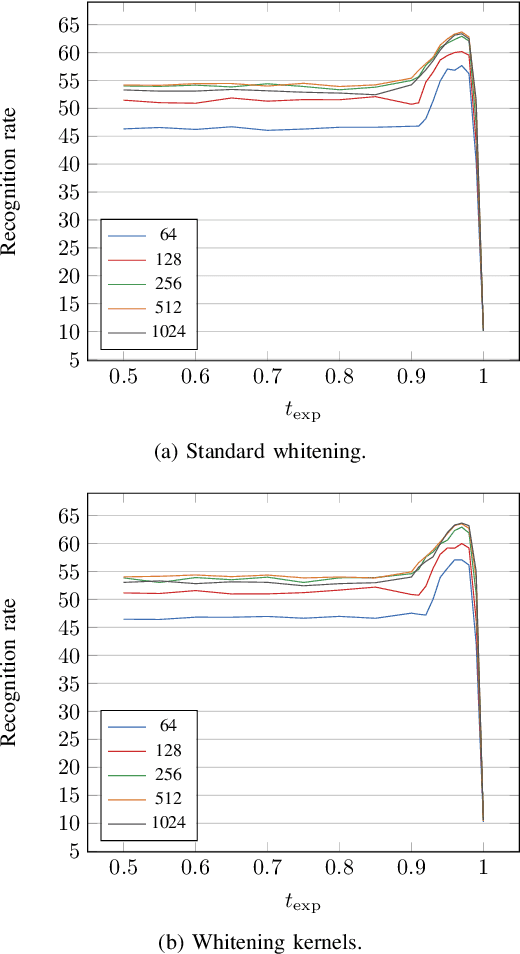
In recent years, spiking neural networks (SNNs) emerge as an alternative to deep neural networks (DNNs). SNNs present a higher computational efficiency using low-power neuromorphic hardware and require less labeled data for training using local and unsupervised learning rules such as spike timing-dependent plasticity (STDP). SNN have proven their effectiveness in image classification on simple datasets such as MNIST. However, to process natural images, a pre-processing step is required. Difference-of-Gaussians (DoG) filtering is typically used together with on-center/off-center coding, but it results in a loss of information that is detrimental to the classification performance. In this paper, we propose to use whitening as a pre-processing step before learning features with STDP. Experiments on CIFAR-10 show that whitening allows STDP to learn visual features that are closer to the ones learned with standard neural networks, with a significantly increased classification performance as compared to DoG filtering. We also propose an approximation of whitening as convolution kernels that is computationally cheaper to learn and more suited to be implemented on neuromorphic hardware. Experiments on CIFAR-10 show that it performs similarly to regular whitening. Cross-dataset experiments on CIFAR-10 and STL-10 also show that it is fairly stable across datasets, making it possible to learn a single whitening transformation to process different datasets.
What is the relationship between face alignment and facial expression recognition?
May 26, 2019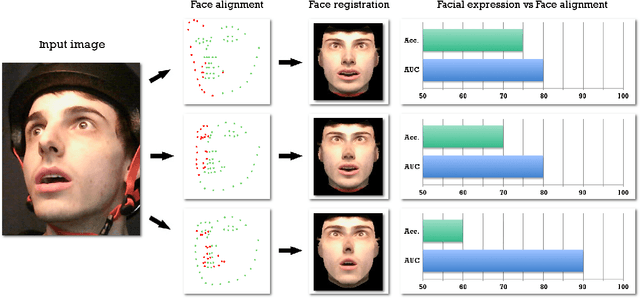
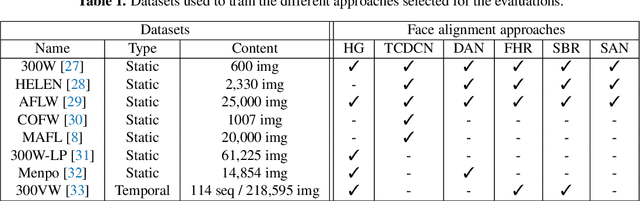

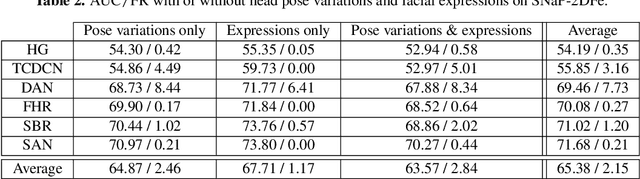
Face expression recognition is still a complex task, particularly due to the presence of head pose variations. Although face alignment approaches are becoming increasingly accurate for characterizing facial regions, it is important to consider the impact of these approaches when they are used for other related tasks such as head pose registration or facial expression recognition. In this paper, we compare the performance of recent face alignment approaches to highlight the most appropriate techniques for preserving facial geometry when correcting the head pose variation. Also, we highlight the most suitable techniques that locate facial landmarks in the presence of head pose variations and facial expressions.
Multi-layered Spiking Neural Network with Target Timestamp Threshold Adaptation and STDP
Apr 03, 2019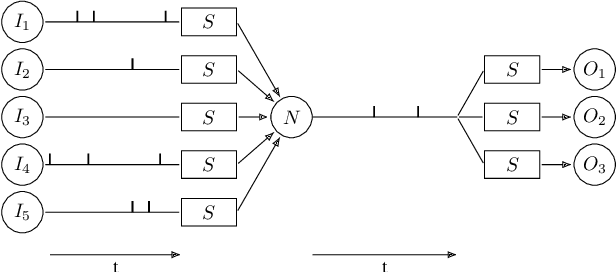

Spiking neural networks (SNNs) are good candidates to produce ultra-energy-efficient hardware. However, the performance of these models is currently behind traditional methods. Introducing multi-layered SNNs is a promising way to reduce this gap. We propose in this paper a new threshold adaptation system which uses a timestamp objective at which neurons should fire. We show that our method leads to state-of-the-art classification rates on the MNIST dataset (98.60%) and the Faces/Motorbikes dataset (99.46%) with an unsupervised SNN followed by a linear SVM. We also investigate the sparsity level of the network by testing different inhibition policies and STDP rules.
Unsupervised Visual Feature Learning with Spike-timing-dependent Plasticity: How Far are we from Traditional Feature Learning Approaches?
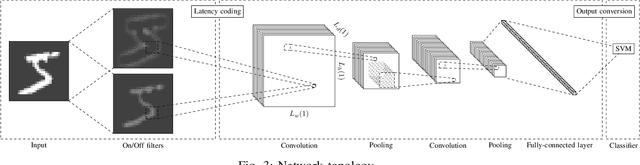
Jan 14, 2019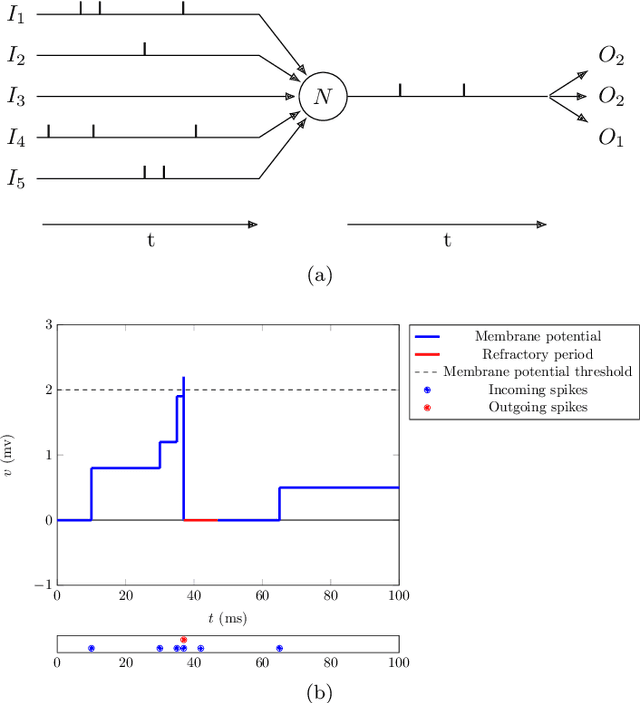

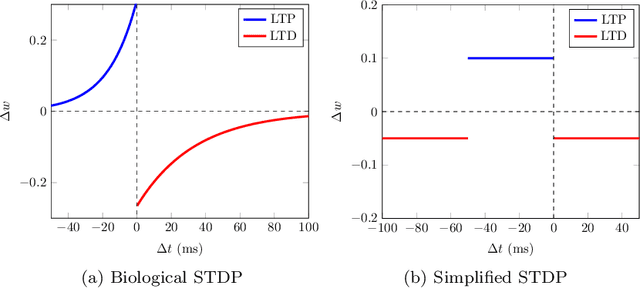
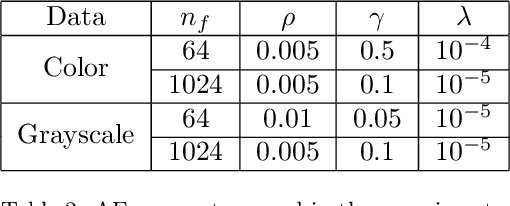
Spiking neural networks (SNNs) equipped with latency coding and spike-timing dependent plasticity rules offer an alternative to solve the data and energy bottlenecks of standard computer vision approaches: they can learn visual features without supervision and can be implemented by ultra-low power hardware architectures. However, their performance in image classification has never been evaluated on recent image datasets. In this paper, we compare SNNs to auto-encoders on three visual recognition datasets, and extend the use of SNNs to color images. Results show that SNNs are not competitive yet with traditional feature learning approaches, especially for color features. Further analyses of the results allow us to identify some of the bottlenecks of SNNs and provide specific directions towards improving their performance on vision tasks.