 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3TC: Spiking Separated Spatial and Temporal Convolutions with Unsupervised STDP-based Learning for Action Recognition
Sep 22, 2023



Video analysis is a major computer vision task that has received a lot of attention in recent years. The current state-of-the-art performance for video analysis is achieved with Deep Neural Networks (DNNs) that have high computational costs and need large amounts of labeled data for training. Spiking Neural Networks (SNNs) have significantly lower computational costs (thousands of times) than regular non-spiking networks when implemented on neuromorphic hardware. They have been used for video analysis with methods like 3D Convolutional Spiking Neural Networks (3D CSNNs). However, these networks have a significantly larger number of parameters compared with spiking 2D CSNN. This, not only increases the computational costs, but also makes these networks more difficult to implement with neuromorphic hardware. In this work, we use CSNNs trained in an unsupervised manner with the Spike Timing-Dependent Plasticity (STDP) rule, and we introduce, for the first time, Spiking Separated Spatial and Temporal Convolutions (S3TCs) for the sake of reducing the number of parameters required for video analysis. This unsupervised learning has the advantage of not needing large amounts of labeled data for training. Factorizing a single spatio-temporal spiking convolution into a spatial and a temporal spiking convolution decreases the number of parameters of the network. We test our network with the KTH, Weizmann, and IXMAS datasets, and we show that S3TCs successfully extract spatio-temporal information from videos, while increasing the output spiking activity, and outperforming spiking 3D convolutions.
Spiking Two-Stream Methods with Unsupervised STDP-based Learning for Action Recognition
Jun 23, 2023



Video analysis is a computer vision task that is useful for many applications like surveillance, human-machine interaction, and autonomous vehicles. Deep Convolutional Neural Networks (CNNs) are currently the state-of-the-art methods for video analysis. However they have high computational costs, and need a large amount of labeled data for training. In this paper, we use Convolutional Spiking Neural Networks (CSNNs) trained with the unsupervised Spike Timing-Dependent Plasticity (STDP) learning rule for action classification. These networks represent the information using asynchronous low-energy spikes. This allows the network to be more energy efficient and neuromorphic hardware-friendly. However, the behaviour of CSNNs is not studied enough with spatio-temporal computer vision models. Therefore, we explore transposing two-stream neural networks into the spiking domain. Implementing this model with unsupervised STDP-based CSNNs allows us to further study the performance of these networks with video analysis. In this work, we show that two-stream CSNNs can successfully extract spatio-temporal information from videos despite using limited training data, and that the spiking spatial and temporal streams are complementary. We also show that using a spatio-temporal stream within a spiking STDP-based two-stream architecture leads to information redundancy and does not improve the performance.
2D versus 3D Convolutional Spiking Neural Networks Trained with Unsupervised STDP for Human Action Recognition
May 26, 2022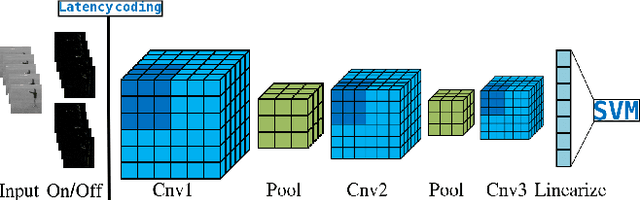


Current advances in technology have highlighted the importance of video analysis in the domain of computer vision. However, video analysis has considerably high computational costs with traditional artificial neural networks (ANNs). Spiking neural networks (SNNs) are third generation biologically plausible models that process the information in the form of spikes. Unsupervised learning with SNNs using the spike timing dependent plasticity (STDP) rule has the potential to overcome some bottlenecks of regular artificial neural networks, but STDP-based SNNs are still immature and their performance is far behind that of ANNs. In this work, we study the performance of SNNs when challenged with the task of human action recognition, because this task has many real-time applications in computer vision, such as video surveillance. In this paper we introduce a multi-layered 3D convolutional SNN model trained with unsupervised STDP. We compare the performance of this model to those of a 2D STDP-based SNN when challenged with the KTH and Weizmann datasets. We also compare single-layer and multi-layer versions of these models in order to get an accurate assessment of their performance. We show that STDP-based convolutional SNNs can learn motion patterns using 3D kernels, thus enabling motion-based recognition from videos. Finally, we give evidence that 3D convolution is superior to 2D convolution with STDP-based SNNs, especially when dealing with long video sequences.