 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Not Leave a Gap: Hallucination-Free Object Concealment in Vision-Language Models
Mar 16, 2026Vision-language models (VLMs) have recently shown remarkable capabilities in visual understanding and generation, but remain vulnerable to adversarial manipulations of visual content. Prior object-hiding attacks primarily rely on suppressing or blocking region-specific representations, often creating semantic gaps that inadvertently induce hallucination, where models invent plausible but incorrect objects. In this work, we demonstrate that hallucination arises not from object absence per se, but from semantic discontinuity introduced by such suppression-based attacks. We propose a new class of \emph{background-consistent object concealment} attacks, which hide target objects by re-encoding their visual representations to be statistically and semantically consistent with surrounding background regions. Crucially, our approach preserves token structure and attention flow, avoiding representational voids that trigger hallucination. We present a pixel-level optimization framework that enforces background-consistent re-encoding across multiple transformer layers while preserving global scene semantics. Extensive experiments on state-of-the-art vision-language models show that our method effectively conceals target objects while preserving up to $86\%$ of non-target objects and reducing grounded hallucination by up to $3\times$ compared to attention-suppression-based attacks.
PatchBlock: A Lightweight Defense Against Adversarial Patches for Embedded EdgeAI Devices
Jan 01, 2026Adversarial attacks pose a significant challenge to the reliable deployment of machine learning models in EdgeAI applications, such as autonomous driving and surveillance, which rely on resource-constrained devices for real-time inference. Among these, patch-based adversarial attacks, where small malicious patches (e.g., stickers) are applied to objects, can deceive neural networks into making incorrect predictions with potentially severe consequences. In this paper, we present PatchBlock, a lightweight framework designed to detect and neutralize adversarial patches in images. Leveraging outlier detection and dimensionality reduction, PatchBlock identifies regions affected by adversarial noise and suppresses their impact. It operates as a pre-processing module at the sensor level, efficiently running on CPUs in parallel with GPU inference, thus preserving system throughput while avoiding additional GPU overhead. The framework follows a three-stage pipeline: splitting the input into chunks (Chunking), detecting anomalous regions via a redesigned isolation forest with targeted cuts for faster convergence (Separating), and applying dimensionality reduction on the identified outliers (Mitigating). PatchBlock is both model- and patch-agnostic, can be retrofitted to existing pipelines, and integrates seamlessly between sensor inputs and downstream models. Evaluations across multiple neural architectures, benchmark datasets, attack types, and diverse edge devices demonstrate that PatchBlock consistently improves robustness, recovering up to 77% of model accuracy under strong patch attacks such as the Google Adversarial Patch, while maintaining high portability and minimal clean accuracy loss. Additionally, PatchBlock outperforms the state-of-the-art defenses in efficiency, in terms of computation time and energy consumption per sample, making it suitable for EdgeAI applications.
TESSER: Transfer-Enhancing Adversarial Attacks from Vision Transformers via Spectral and Semantic Regularization
May 26, 2025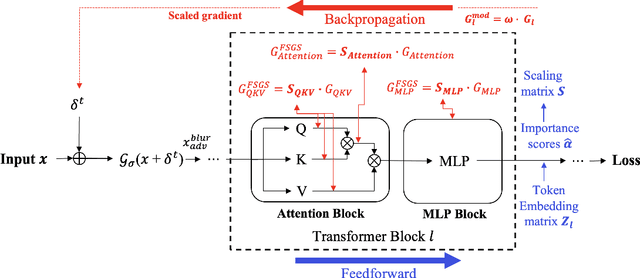



Adversarial transferability remains a critical challenge in evaluating the robustness of deep neural networks. In security-critical applications, transferability enables black-box attacks without access to model internals, making it a key concern for real-world adversarial threat assessment. While Vision Transformers (ViTs) have demonstrated strong adversarial performance, existing attacks often fail to transfer effectively across architectures, especially from ViTs to Convolutional Neural Networks (CNNs) or hybrid models. In this paper, we introduce \textbf{TESSER} -- a novel adversarial attack framework that enhances transferability via two key strategies: (1) \textit{Feature-Sensitive Gradient Scaling (FSGS)}, which modulates gradients based on token-wise importance derived from intermediate feature activations, and (2) \textit{Spectral Smoothness Regularization (SSR)}, which suppresses high-frequency noise in perturbations using a differentiable Gaussian prior. These components work in tandem to generate perturbations that are both semantically meaningful and spectrally smooth. Extensive experiments on ImageNet across 12 diverse architectures demonstrate that TESSER achieves +10.9\% higher attack succes rate (ASR) on CNNs and +7.2\% on ViTs compared to the state-of-the-art Adaptive Token Tuning (ATT) method. Moreover, TESSER significantly improves robustness against defended models, achieving 53.55\% ASR on adversarially trained CNNs. Qualitative analysis shows strong alignment between TESSER's perturbations and salient visual regions identified via Grad-CAM, while frequency-domain analysis reveals a 12\% reduction in high-frequency energy, confirming the effectiveness of spectral regularization.
Breaking the Limits of Quantization-Aware Defenses: QADT-R for Robustness Against Patch-Based Adversarial Attacks in QNNs
Mar 10, 2025



Quantized Neural Networks (QNNs) have emerged as a promising solution for reducing model size and computational costs, making them well-suited for deployment in edge and resource-constrained environments. While quantization is known to disrupt gradient propagation and enhance robustness against pixel-level adversarial attacks, its effectiveness against patch-based adversarial attacks remains largely unexplored. In this work, we demonstrate that adversarial patches remain highly transferable across quantized models, achieving over 70\% attack success rates (ASR) even at extreme bit-width reductions (e.g., 2-bit). This challenges the common assumption that quantization inherently mitigates adversarial threats. To address this, we propose Quantization-Aware Defense Training with Randomization (QADT-R), a novel defense strategy that integrates Adaptive Quantization-Aware Patch Generation (A-QAPA), Dynamic Bit-Width Training (DBWT), and Gradient-Inconsistent Regularization (GIR) to enhance resilience against highly transferable patch-based attacks. A-QAPA generates adversarial patches within quantized models, ensuring robustness across different bit-widths. DBWT introduces bit-width cycling during training to prevent overfitting to a specific quantization setting, while GIR injects controlled gradient perturbations to disrupt adversarial optimization. Extensive evaluations on CIFAR-10 and ImageNet show that QADT-R reduces ASR by up to 25\% compared to prior defenses such as PBAT and DWQ. Our findings further reveal that PBAT-trained models, while effective against seen patch configurations, fail to generalize to unseen patches due to quantization shift. Additionally, our empirical analysis of gradient alignment, spatial sensitivity, and patch visibility provides insights into the mechanisms that contribute to the high transferability of patch-based attacks in QNNs.
Navigating Threats: A Survey of Physical Adversarial Attacks on LiDAR Perception Systems in Autonomous Vehicles
Sep 30, 2024

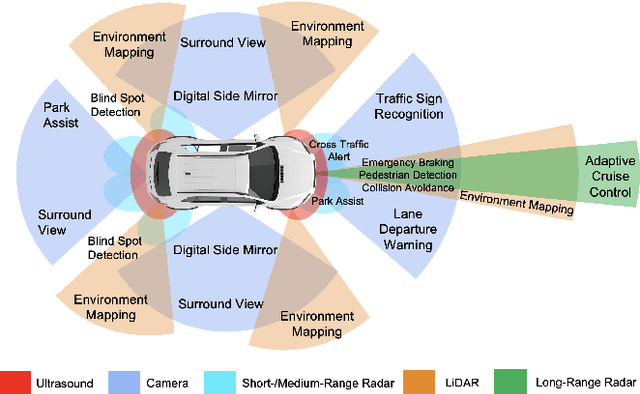

Autonomous vehicles (AVs) rely heavily on LiDAR (Light Detection and Ranging) systems for accurate perception and navigation, providing high-resolution 3D environmental data that is crucial for object detection and classification. However, LiDAR systems are vulnerable to adversarial attacks, which pose significant challenges to the safety and robustness of AVs. This survey presents a thorough review of the current research landscape on physical adversarial attacks targeting LiDAR-based perception systems, covering both single-modality and multi-modality contexts. We categorize and analyze various attack types, including spoofing and physical adversarial object attacks, detailing their methodologies, impacts, and potential real-world implications. Through detailed case studies and analyses, we identify critical challenges and highlight gaps in existing attacks for LiDAR-based systems. Additionally, we propose future research directions to enhance the security and resilience of these systems, ultimately contributing to the safer deployment of autonomous vehicles.
Exploring the Interplay of Interpretability and Robustness in Deep Neural Networks: A Saliency-guided Approach
May 10, 2024



Adversarial attacks pose a significant challenge to deploying deep learning models in safety-critical applications. Maintaining model robustness while ensuring interpretability is vital for fostering trust and comprehension in these models. This study investigates the impact of Saliency-guided Training (SGT) on model robustness, a technique aimed at improving the clarity of saliency maps to deepen understanding of the model's decision-making process. Experiments were conducted on standard benchmark datasets using various deep learning architectures trained with and without SGT. Findings demonstrate that SGT enhances both model robustness and interpretability. Additionally, we propose a novel approach combining SGT with standard adversarial training to achieve even greater robustness while preserving saliency map quality. Our strategy is grounded in the assumption that preserving salient features crucial for correctly classifying adversarial examples enhances model robustness, while masking non-relevant features improves interpretability. Our technique yields significant gains, achieving a 35\% and 20\% improvement in robustness against PGD attack with noise magnitudes of $0.2$ and $0.02$ for the MNIST and CIFAR-10 datasets, respectively, while producing high-quality saliency maps.
Examining Changes in Internal Representations of Continual Learning Models Through Tensor Decomposition
May 06, 2024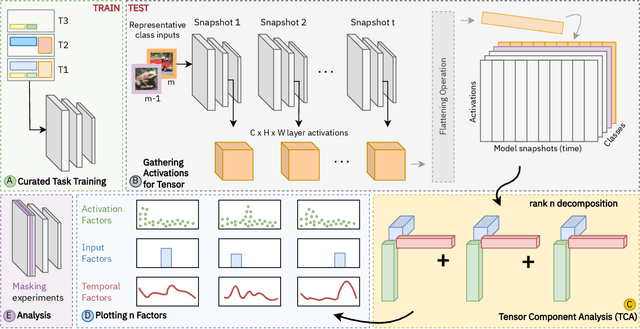

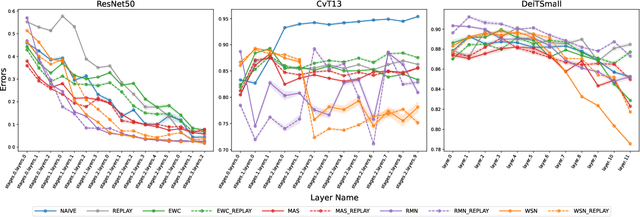
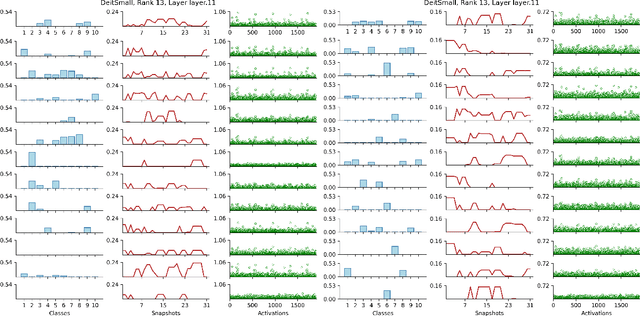
Continual learning (CL) has spurred the development of several methods aimed at consolidating previous knowledge across sequential learning. Yet, the evaluations of these methods have primarily focused on the final output, such as changes in the accuracy of predicted classes, overlooking the issue of representational forgetting within the model. In this paper, we propose a novel representation-based evaluation framework for CL models. This approach involves gathering internal representations from throughout the continual learning process and formulating three-dimensional tensors. The tensors are formed by stacking representations, such as layer activations, generated from several inputs and model `snapshots', throughout the learning process. By conducting tensor component analysis (TCA), we aim to uncover meaningful patterns about how the internal representations evolve, expecting to highlight the merits or shortcomings of examined CL strategies. We conduct our analyses across different model architectures and importance-based continual learning strategies, with a curated task selection. While the results of our approach mirror the difference in performance of various CL strategies, we found that our methodology did not directly highlight specialized clusters of neurons, nor provide an immediate understanding the evolution of filters. We believe a scaled down version of our approach will provide insight into the benefits and pitfalls of using TCA to study continual learning dynamics.
SSAP: A Shape-Sensitive Adversarial Patch for Comprehensive Disruption of Monocular Depth Estimation in Autonomous Navigation Applications
Mar 18, 2024



Monocular depth estimation (MDE) has advanced significantly, primarily through the integration of convolutional neural networks (CNNs) and more recently, Transformers. However, concerns about their susceptibility to adversarial attacks have emerged, especially in safety-critical domains like autonomous driving and robotic navigation. Existing approaches for assessing CNN-based depth prediction methods have fallen short in inducing comprehensive disruptions to the vision system, often limited to specific local areas. In this paper, we introduce SSAP (Shape-Sensitive Adversarial Patch), a novel approach designed to comprehensively disrupt monocular depth estimation (MDE) in autonomous navigation applications. Our patch is crafted to selectively undermine MDE in two distinct ways: by distorting estimated distances or by creating the illusion of an object disappearing from the system's perspective. Notably, our patch is shape-sensitive, meaning it considers the specific shape and scale of the target object, thereby extending its influence beyond immediate proximity. Furthermore, our patch is trained to effectively address different scales and distances from the camera. Experimental results demonstrate that our approach induces a mean depth estimation error surpassing 0.5, impacting up to 99% of the targeted region for CNN-based MDE models. Additionally, we investigate the vulnerability of Transformer-based MDE models to patch-based attacks, revealing that SSAP yields a significant error of 0.59 and exerts substantial influence over 99% of the target region on these models.
Anomaly Unveiled: Securing Image Classification against Adversarial Patch Attacks
Feb 09, 2024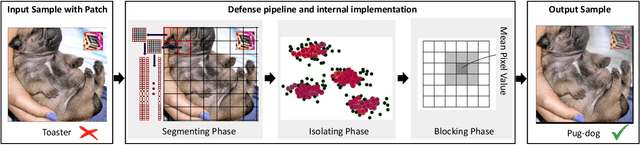

Adversarial patch attacks pose a significant threat to the practical deployment of deep learning systems. However, existing research primarily focuses on image pre-processing defenses, which often result in reduced classification accuracy for clean images and fail to effectively counter physically feasible attacks. In this paper, we investigate the behavior of adversarial patches as anomalies within the distribution of image information and leverage this insight to develop a robust defense strategy. Our proposed defense mechanism utilizes a clustering-based technique called DBSCAN to isolate anomalous image segments, which is carried out by a three-stage pipeline consisting of Segmenting, Isolating, and Blocking phases to identify and mitigate adversarial noise. Upon identifying adversarial components, we neutralize them by replacing them with the mean pixel value, surpassing alternative replacement options. Our model-agnostic defense mechanism is evaluated across multiple models and datasets, demonstrating its effectiveness in countering various adversarial patch attacks in image classification tasks. Our proposed approach significantly improves accuracy, increasing from 38.8\% without the defense to 67.1\% with the defense against LaVAN and GoogleAp attacks, surpassing prominent state-of-the-art methods such as LGS (53.86\%) and Jujutsu (60\%)
ODDR: Outlier Detection & Dimension Reduction Based Defense Against Adversarial Patches
Nov 20, 2023



Adversarial attacks are a major deterrent towards the reliable use of machine learning models. A powerful type of adversarial attacks is the patch-based attack, wherein the adversarial perturbations modify localized patches or specific areas within the images to deceive the trained machine learning model. In this paper, we introduce Outlier Detection and Dimension Reduction (ODDR), a holistic defense mechanism designed to effectively mitigate patch-based adversarial attacks. In our approach, we posit that input features corresponding to adversarial patches, whether naturalistic or otherwise, deviate from the inherent distribution of the remaining image sample and can be identified as outliers or anomalies. ODDR employs a three-stage pipeline: Fragmentation, Segregation, and Neutralization, providing a model-agnostic solution applicable to both image classification and object detection tasks. The Fragmentation stage parses the samples into chunks for the subsequent Segregation process. Here, outlier detection techniques identify and segregate the anomalous features associated with adversarial perturbations. The Neutralization stage utilizes dimension reduction methods on the outliers to mitigate the impact of adversarial perturbations without sacrificing pertinent information necessary for the machine learning task. Extensive testing on benchmark datasets and state-of-the-art adversarial patches demonstrates the effectiveness of ODDR. Results indicate robust accuracies matching and lying within a small range of clean accuracies (1%-3% for classification and 3%-5% for object detection), with only a marginal compromise of 1%-2% in performance on clean samples, thereby significantly outperforming other defenses.