 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRAP-ViT: Segregated Tokens with Randomized -- Transformations for Defense against Adversarial Patches in ViTs
Mar 13, 2026Adversarial patches are physically realizable localized noise, which are able to hijack Vision Transformers (ViT) self-attention, pulling focus toward a small, high-contrast region and corrupting the class token to force confident misclassifications. In this paper, we claim that the tokens which correspond to the areas of the image that contain the adversarial noise, have different statistical properties when compared to the tokens which do not overlap with the adversarial perturbations. We use this insight to propose a mechanism, called STRAP-ViT, which uses Jensen-Shannon Divergence as a metric for segregating tokens that behave as anomalies in the Detection Phase, and then apply randomized composite transformations on them during the Mitigation Phase to make the adversarial noise ineffective. The minimum number of tokens to transform is a hyper-parameter for the defense mechanism and is chosen such that at least 50% of the patch is covered by the transformed tokens. STRAP-ViT fits as a non-trainable plug-and-play block within the ViT architectures, for inference purposes only, with a minimal computational cost and does not require any additional training cost/effort. STRAP-ViT has been tested on multiple pre-trained vision transformer architectures (ViT-base-16 and DinoV2) and datasets (ImageNet and CalTech-101), across multiple adversarial attacks (Adversarial Patch, LAVAN, GDPA and RP2), and found to provide excellent robust accuracies lying within a 2-3% range of the clean baselines, and outperform the state-of-the-art.
PatchBlock: A Lightweight Defense Against Adversarial Patches for Embedded EdgeAI Devices
Jan 01, 2026Adversarial attacks pose a significant challenge to the reliable deployment of machine learning models in EdgeAI applications, such as autonomous driving and surveillance, which rely on resource-constrained devices for real-time inference. Among these, patch-based adversarial attacks, where small malicious patches (e.g., stickers) are applied to objects, can deceive neural networks into making incorrect predictions with potentially severe consequences. In this paper, we present PatchBlock, a lightweight framework designed to detect and neutralize adversarial patches in images. Leveraging outlier detection and dimensionality reduction, PatchBlock identifies regions affected by adversarial noise and suppresses their impact. It operates as a pre-processing module at the sensor level, efficiently running on CPUs in parallel with GPU inference, thus preserving system throughput while avoiding additional GPU overhead. The framework follows a three-stage pipeline: splitting the input into chunks (Chunking), detecting anomalous regions via a redesigned isolation forest with targeted cuts for faster convergence (Separating), and applying dimensionality reduction on the identified outliers (Mitigating). PatchBlock is both model- and patch-agnostic, can be retrofitted to existing pipelines, and integrates seamlessly between sensor inputs and downstream models. Evaluations across multiple neural architectures, benchmark datasets, attack types, and diverse edge devices demonstrate that PatchBlock consistently improves robustness, recovering up to 77% of model accuracy under strong patch attacks such as the Google Adversarial Patch, while maintaining high portability and minimal clean accuracy loss. Additionally, PatchBlock outperforms the state-of-the-art defenses in efficiency, in terms of computation time and energy consumption per sample, making it suitable for EdgeAI applications.
Learning Nonlinearity of Boolean Functions: An Experimentation with Neural Networks
Feb 03, 2025



This paper investigates the learnability of the nonlinearity property of Boolean functions using neural networks. We train encoder style deep neural networks to learn to predict the nonlinearity of Boolean functions from examples of functions in the form of a truth table and their corresponding nonlinearity values. We report empirical results to show that deep neural networks are able to learn to predict the property for functions in 4 and 5 variables with an accuracy above 95%. While these results are positive and a disciplined analysis is being presented for the first time in this regard, we should also underline the statutory warning that it seems quite challenging to extend the idea to higher number of variables, and it is also not clear whether one can get advantage in terms of time and space complexity over the existing combinatorial algorithms.
Persistence of Backdoor-based Watermarks for Neural Networks: A Comprehensive Evaluation
Jan 06, 2025



Deep Neural Networks (DNNs) have gained considerable traction in recent years due to the unparalleled results they gathered. However, the cost behind training such sophisticated models is resource intensive, resulting in many to consider DNNs to be intellectual property (IP) to model owners. In this era of cloud computing, high-performance DNNs are often deployed all over the internet so that people can access them publicly. As such, DNN watermarking schemes, especially backdoor-based watermarks, have been actively developed in recent years to preserve proprietary rights. Nonetheless, there lies much uncertainty on the robustness of existing backdoor watermark schemes, towards both adversarial attacks and unintended means such as fine-tuning neural network models. One reason for this is that no complete guarantee of robustness can be assured in the context of backdoor-based watermark. In this paper, we extensively evaluate the persistence of recent backdoor-based watermarks within neural networks in the scenario of fine-tuning, we propose/develop a novel data-driven idea to restore watermark after fine-tuning without exposing the trigger set. Our empirical results show that by solely introducing training data after fine-tuning, the watermark can be restored if model parameters do not shift dramatically during fine-tuning. Depending on the types of trigger samples used, trigger accuracy can be reinstated to up to 100%. Our study further explores how the restoration process works using loss landscape visualization, as well as the idea of introducing training data in fine-tuning stage to alleviate watermark vanishing.
BlockDoor: Blocking Backdoor Based Watermarks in Deep Neural Networks
Dec 14, 2024Adoption of machine learning models across industries have turned Neural Networks (DNNs) into a prized Intellectual Property (IP), which needs to be protected from being stolen or being used without authorization. This topic gave rise to multiple watermarking schemes, through which, one can establish the ownership of a model. Watermarking using backdooring is the most well established method available in the literature, with specific works demonstrating the difficulty in removing the watermarks, embedded as backdoors within the weights of the network. However, in our work, we have identified a critical flaw in the design of the watermark verification with backdoors, pertaining to the behaviour of the samples of the Trigger Set, which acts as the secret key. In this paper, we present BlockDoor, which is a comprehensive package of techniques that is used as a wrapper to block all three different kinds of Trigger samples, which are used in the literature as means to embed watermarks within the trained neural networks as backdoors. The framework implemented through BlockDoor is able to detect potential Trigger samples, through separate functions for adversarial noise based triggers, out-of-distribution triggers and random label based triggers. Apart from a simple Denial-of-Service for a potential Trigger sample, our approach is also able to modify the Trigger samples for correct machine learning functionality. Extensive evaluation of BlockDoor establishes that it is able to significantly reduce the watermark validation accuracy of the Trigger set by up to $98\%$ without compromising on functionality, delivering up to a less than $1\%$ drop on the clean samples. BlockDoor has been tested on multiple datasets and neural architectures.
Adversarial Attacks and Dimensionality in Text Classifiers
Apr 03, 2024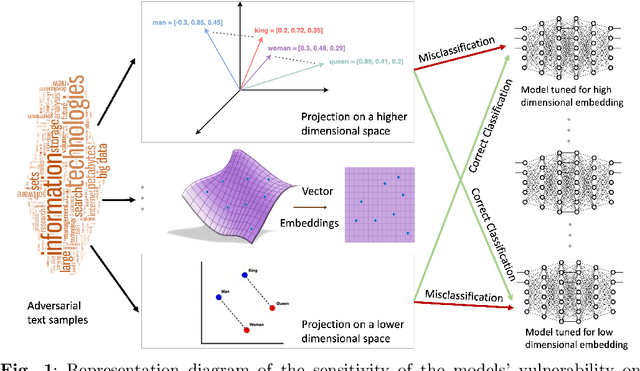
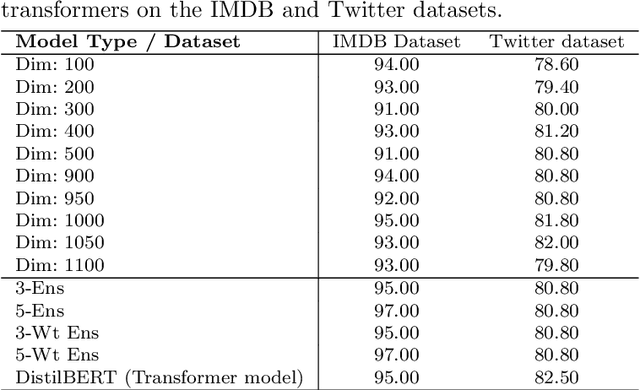
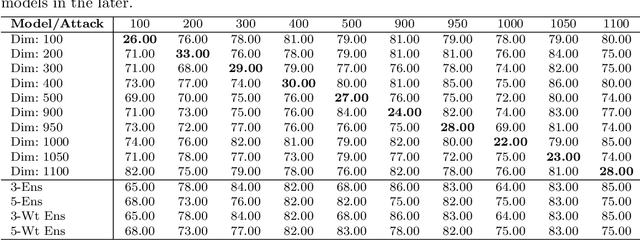
Adversarial attacks on machine learning algorithms have been a key deterrent to the adoption of AI in many real-world use cases. They significantly undermine the ability of high-performance neural networks by forcing misclassifications. These attacks introduce minute and structured perturbations or alterations in the test samples, imperceptible to human annotators in general, but trained neural networks and other models are sensitive to it. Historically, adversarial attacks have been first identified and studied in the domain of image processing. In this paper, we study adversarial examples in the field of natural language processing, specifically text classification tasks. We investigate the reasons for adversarial vulnerability, particularly in relation to the inherent dimensionality of the model. Our key finding is that there is a very strong correlation between the embedding dimensionality of the adversarial samples and their effectiveness on models tuned with input samples with same embedding dimension. We utilize this sensitivity to design an adversarial defense mechanism. We use ensemble models of varying inherent dimensionality to thwart the attacks. This is tested on multiple datasets for its efficacy in providing robustness. We also study the problem of measuring adversarial perturbation using different distance metrics. For all of the aforementioned studies, we have run tests on multiple models with varying dimensionality and used a word-vector level adversarial attack to substantiate the findings.
Anomaly Unveiled: Securing Image Classification against Adversarial Patch Attacks
Feb 09, 2024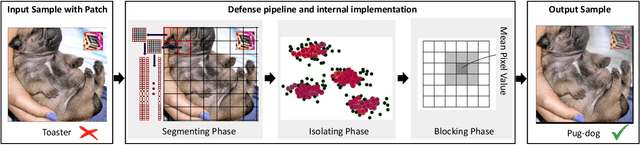
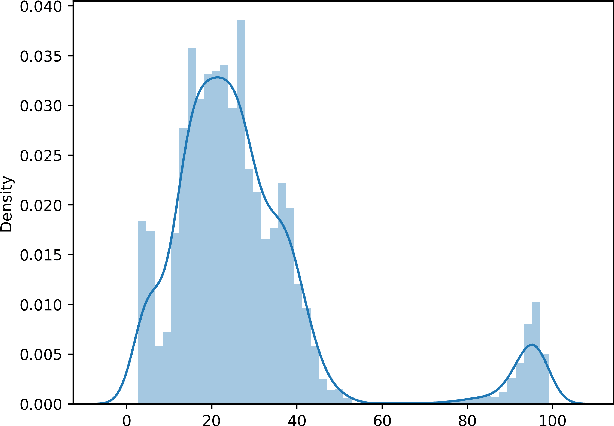

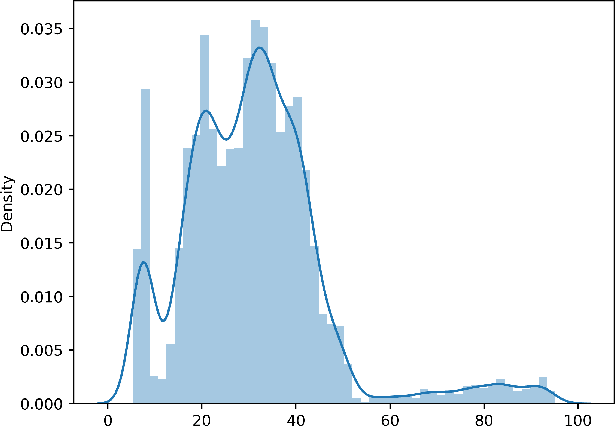
Adversarial patch attacks pose a significant threat to the practical deployment of deep learning systems. However, existing research primarily focuses on image pre-processing defenses, which often result in reduced classification accuracy for clean images and fail to effectively counter physically feasible attacks. In this paper, we investigate the behavior of adversarial patches as anomalies within the distribution of image information and leverage this insight to develop a robust defense strategy. Our proposed defense mechanism utilizes a clustering-based technique called DBSCAN to isolate anomalous image segments, which is carried out by a three-stage pipeline consisting of Segmenting, Isolating, and Blocking phases to identify and mitigate adversarial noise. Upon identifying adversarial components, we neutralize them by replacing them with the mean pixel value, surpassing alternative replacement options. Our model-agnostic defense mechanism is evaluated across multiple models and datasets, demonstrating its effectiveness in countering various adversarial patch attacks in image classification tasks. Our proposed approach significantly improves accuracy, increasing from 38.8\% without the defense to 67.1\% with the defense against LaVAN and GoogleAp attacks, surpassing prominent state-of-the-art methods such as LGS (53.86\%) and Jujutsu (60\%)
ODDR: Outlier Detection & Dimension Reduction Based Defense Against Adversarial Patches
Nov 20, 2023



Adversarial attacks are a major deterrent towards the reliable use of machine learning models. A powerful type of adversarial attacks is the patch-based attack, wherein the adversarial perturbations modify localized patches or specific areas within the images to deceive the trained machine learning model. In this paper, we introduce Outlier Detection and Dimension Reduction (ODDR), a holistic defense mechanism designed to effectively mitigate patch-based adversarial attacks. In our approach, we posit that input features corresponding to adversarial patches, whether naturalistic or otherwise, deviate from the inherent distribution of the remaining image sample and can be identified as outliers or anomalies. ODDR employs a three-stage pipeline: Fragmentation, Segregation, and Neutralization, providing a model-agnostic solution applicable to both image classification and object detection tasks. The Fragmentation stage parses the samples into chunks for the subsequent Segregation process. Here, outlier detection techniques identify and segregate the anomalous features associated with adversarial perturbations. The Neutralization stage utilizes dimension reduction methods on the outliers to mitigate the impact of adversarial perturbations without sacrificing pertinent information necessary for the machine learning task. Extensive testing on benchmark datasets and state-of-the-art adversarial patches demonstrates the effectiveness of ODDR. Results indicate robust accuracies matching and lying within a small range of clean accuracies (1%-3% for classification and 3%-5% for object detection), with only a marginal compromise of 1%-2% in performance on clean samples, thereby significantly outperforming other defenses.
Spatially Correlated Patterns in Adversarial Images
Nov 21, 2020
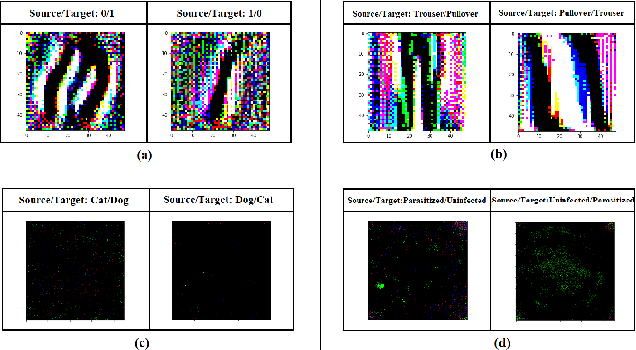
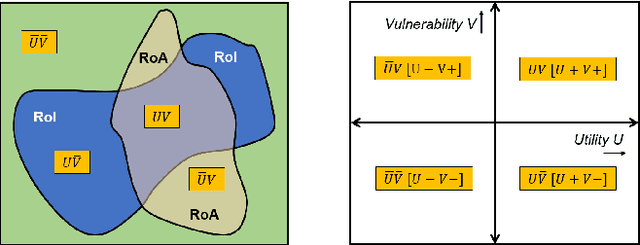

Adversarial attacks have proved to be the major impediment in the progress on research towards reliable machine learning solutions. Carefully crafted perturbations, imperceptible to human vision, can be added to images to force misclassification by an otherwise high performing neural network. To have a better understanding of the key contributors of such structured attacks, we searched for and studied spatially co-located patterns in the distribution of pixels in the input space. In this paper, we propose a framework for segregating and isolating regions within an input image which are particularly critical towards either classification (during inference), or adversarial vulnerability or both. We assert that during inference, the trained model looks at a specific region in the image, which we call Region of Importance (RoI); and the attacker looks at a region to alter/modify, which we call Region of Attack (RoA). The success of this approach could also be used to design a post-hoc adversarial defence method, as illustrated by our observations. This uses the notion of blocking out (we call neutralizing) that region of the image which is highly vulnerable to adversarial attacks but is not important for the task of classification. We establish the theoretical setup for formalising the process of segregation, isolation and neutralization and substantiate it through empirical analysis on standard benchmarking datasets. The findings strongly indicate that mapping features into the input space preserves the significant patterns typically observed in the feature-space while adding major interpretability and therefore simplifies potential defensive mechanisms.