 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTRAP-ViT: Segregated Tokens with Randomized -- Transformations for Defense against Adversarial Patches in ViTs
Mar 13, 2026Adversarial patches are physically realizable localized noise, which are able to hijack Vision Transformers (ViT) self-attention, pulling focus toward a small, high-contrast region and corrupting the class token to force confident misclassifications. In this paper, we claim that the tokens which correspond to the areas of the image that contain the adversarial noise, have different statistical properties when compared to the tokens which do not overlap with the adversarial perturbations. We use this insight to propose a mechanism, called STRAP-ViT, which uses Jensen-Shannon Divergence as a metric for segregating tokens that behave as anomalies in the Detection Phase, and then apply randomized composite transformations on them during the Mitigation Phase to make the adversarial noise ineffective. The minimum number of tokens to transform is a hyper-parameter for the defense mechanism and is chosen such that at least 50% of the patch is covered by the transformed tokens. STRAP-ViT fits as a non-trainable plug-and-play block within the ViT architectures, for inference purposes only, with a minimal computational cost and does not require any additional training cost/effort. STRAP-ViT has been tested on multiple pre-trained vision transformer architectures (ViT-base-16 and DinoV2) and datasets (ImageNet and CalTech-101), across multiple adversarial attacks (Adversarial Patch, LAVAN, GDPA and RP2), and found to provide excellent robust accuracies lying within a 2-3% range of the clean baselines, and outperform the state-of-the-art.
NutVLM: A Self-Adaptive Defense Framework against Full-Dimension Attacks for Vision Language Models in Autonomous Driving
Feb 09, 2026Vision Language Models (VLMs) have advanced perception in autonomous driving (AD), but they remain vulnerable to adversarial threats. These risks range from localized physical patches to imperceptible global perturbations. Existing defense methods for VLMs remain limited and often fail to reconcile robustness with clean-sample performance. To bridge these gaps, we propose NutVLM, a comprehensive self-adaptive defense framework designed to secure the entire perception-decision lifecycle. Specifically, we first employ NutNet++ as a sentinel, which is a unified detection-purification mechanism. It identifies benign samples, local patches, and global perturbations through three-way classification. Subsequently, localized threats are purified via efficient grayscale masking, while global perturbations trigger Expert-guided Adversarial Prompt Tuning (EAPT). Instead of the costly parameter updates of full-model fine-tuning, EAPT generates "corrective driving prompts" via gradient-based latent optimization and discrete projection. These prompts refocus the VLM's attention without requiring exhaustive full-model retraining. Evaluated on the Dolphins benchmark, our NutVLM yields a 4.89% improvement in overall metrics (e.g., Accuracy, Language Score, and GPT Score). These results validate NutVLM as a scalable security solution for intelligent transportation. Our code is available at https://github.com/PXX/NutVLM.
Toward Noise-Aware Audio Deepfake Detection: Survey, SNR-Benchmarks, and Practical Recipes
Dec 15, 2025Deepfake audio detection has progressed rapidly with strong pre-trained encoders (e.g., WavLM, Wav2Vec2, MMS). However, performance in realistic capture conditions - background noise (domestic/office/transport), room reverberation, and consumer channels - often lags clean-lab results. We survey and evaluate robustness for state-of-the-art audio deepfake detection models and present a reproducible framework that mixes MS-SNSD noises with ASVspoof 2021 DF utterances to evaluate under controlled signal-to-noise ratios (SNRs). SNR is a measured proxy for noise severity used widely in speech; it lets us sweep from near-clean (35 dB) to very noisy (-5 dB) to quantify graceful degradation. We study multi-condition training and fixed-SNR testing for pretrained encoders (WavLM, Wav2Vec2, MMS), reporting accuracy, ROC-AUC, and EER on binary and four-class (authenticity x corruption) tasks. In our experiments, finetuning reduces EER by 10-15 percentage points at 10-0 dB SNR across backbones.
Efficient and Encrypted Inference using Binarized Neural Networks within In-Memory Computing Architectures
Oct 27, 2025Binarized Neural Networks (BNNs) are a class of deep neural networks designed to utilize minimal computational resources, which drives their popularity across various applications. Recent studies highlight the potential of mapping BNN model parameters onto emerging non-volatile memory technologies, specifically using crossbar architectures, resulting in improved inference performance compared to traditional CMOS implementations. However, the common practice of protecting model parameters from theft attacks by storing them in an encrypted format and decrypting them at runtime introduces significant computational overhead, thus undermining the core principles of in-memory computing, which aim to integrate computation and storage. This paper presents a robust strategy for protecting BNN model parameters, particularly within in-memory computing frameworks. Our method utilizes a secret key derived from a physical unclonable function to transform model parameters prior to storage in the crossbar. Subsequently, the inference operations are performed on the encrypted weights, achieving a very special case of Fully Homomorphic Encryption (FHE) with minimal runtime overhead. Our analysis reveals that inference conducted without the secret key results in drastically diminished performance, with accuracy falling below 15%. These results validate the effectiveness of our protection strategy in securing BNNs within in-memory computing architectures while preserving computational efficiency.
Learning Nonlinearity of Boolean Functions: An Experimentation with Neural Networks
Feb 03, 2025



This paper investigates the learnability of the nonlinearity property of Boolean functions using neural networks. We train encoder style deep neural networks to learn to predict the nonlinearity of Boolean functions from examples of functions in the form of a truth table and their corresponding nonlinearity values. We report empirical results to show that deep neural networks are able to learn to predict the property for functions in 4 and 5 variables with an accuracy above 95%. While these results are positive and a disciplined analysis is being presented for the first time in this regard, we should also underline the statutory warning that it seems quite challenging to extend the idea to higher number of variables, and it is also not clear whether one can get advantage in terms of time and space complexity over the existing combinatorial algorithms.
Persistence of Backdoor-based Watermarks for Neural Networks: A Comprehensive Evaluation
Jan 06, 2025



Deep Neural Networks (DNNs) have gained considerable traction in recent years due to the unparalleled results they gathered. However, the cost behind training such sophisticated models is resource intensive, resulting in many to consider DNNs to be intellectual property (IP) to model owners. In this era of cloud computing, high-performance DNNs are often deployed all over the internet so that people can access them publicly. As such, DNN watermarking schemes, especially backdoor-based watermarks, have been actively developed in recent years to preserve proprietary rights. Nonetheless, there lies much uncertainty on the robustness of existing backdoor watermark schemes, towards both adversarial attacks and unintended means such as fine-tuning neural network models. One reason for this is that no complete guarantee of robustness can be assured in the context of backdoor-based watermark. In this paper, we extensively evaluate the persistence of recent backdoor-based watermarks within neural networks in the scenario of fine-tuning, we propose/develop a novel data-driven idea to restore watermark after fine-tuning without exposing the trigger set. Our empirical results show that by solely introducing training data after fine-tuning, the watermark can be restored if model parameters do not shift dramatically during fine-tuning. Depending on the types of trigger samples used, trigger accuracy can be reinstated to up to 100%. Our study further explores how the restoration process works using loss landscape visualization, as well as the idea of introducing training data in fine-tuning stage to alleviate watermark vanishing.
BlockDoor: Blocking Backdoor Based Watermarks in Deep Neural Networks
Dec 14, 2024Adoption of machine learning models across industries have turned Neural Networks (DNNs) into a prized Intellectual Property (IP), which needs to be protected from being stolen or being used without authorization. This topic gave rise to multiple watermarking schemes, through which, one can establish the ownership of a model. Watermarking using backdooring is the most well established method available in the literature, with specific works demonstrating the difficulty in removing the watermarks, embedded as backdoors within the weights of the network. However, in our work, we have identified a critical flaw in the design of the watermark verification with backdoors, pertaining to the behaviour of the samples of the Trigger Set, which acts as the secret key. In this paper, we present BlockDoor, which is a comprehensive package of techniques that is used as a wrapper to block all three different kinds of Trigger samples, which are used in the literature as means to embed watermarks within the trained neural networks as backdoors. The framework implemented through BlockDoor is able to detect potential Trigger samples, through separate functions for adversarial noise based triggers, out-of-distribution triggers and random label based triggers. Apart from a simple Denial-of-Service for a potential Trigger sample, our approach is also able to modify the Trigger samples for correct machine learning functionality. Extensive evaluation of BlockDoor establishes that it is able to significantly reduce the watermark validation accuracy of the Trigger set by up to $98\%$ without compromising on functionality, delivering up to a less than $1\%$ drop on the clean samples. BlockDoor has been tested on multiple datasets and neural architectures.
Privacy-Preserving Graph-Based Machine Learning with Fully Homomorphic Encryption for Collaborative Anti-Money Laundering
Nov 05, 2024



Combating money laundering has become increasingly complex with the rise of cybercrime and digitalization of financial transactions. Graph-based machine learning techniques have emerged as promising tools for Anti-Money Laundering (AML) detection, capturing intricate relationships within money laundering networks. However, the effectiveness of AML solutions is hindered by data silos within financial institutions, limiting collaboration and overall efficacy. This research presents a novel privacy-preserving approach for collaborative AML machine learning, facilitating secure data sharing across institutions and borders while preserving privacy and regulatory compliance. Leveraging Fully Homomorphic Encryption (FHE), computations are directly performed on encrypted data, ensuring the confidentiality of financial data. Notably, FHE over the Torus (TFHE) was integrated with graph-based machine learning using Zama Concrete ML. The research contributes two key privacy-preserving pipelines. First, the development of a privacy-preserving Graph Neural Network (GNN) pipeline was explored. Optimization techniques like quantization and pruning were used to render the GNN FHE-compatible. Second, a privacy-preserving graph-based XGBoost pipeline leveraging Graph Feature Preprocessor (GFP) was successfully developed. Experiments demonstrated strong predictive performance, with the XGBoost model consistently achieving over 99% accuracy, F1-score, precision, and recall on the balanced AML dataset in both unencrypted and FHE-encrypted inference settings. On the imbalanced dataset, the incorporation of graph-based features improved the F1-score by 8%. The research highlights the need to balance the trade-off between privacy and computational efficiency.
Federated Learning Optimization: A Comparative Study of Data and Model Exchange Strategies in Dynamic Networks
Jun 16, 2024



The promise and proliferation of large-scale dynamic federated learning gives rise to a prominent open question - is it prudent to share data or model across nodes, if efficiency of transmission and fast knowledge transfer are the prime objectives. This work investigates exactly that. Specifically, we study the choices of exchanging raw data, synthetic data, or (partial) model updates among devices. The implications of these strategies in the context of foundational models are also examined in detail. Accordingly, we obtain key insights about optimal data and model exchange mechanisms considering various environments with different data distributions and dynamic device and network connections. Across various scenarios that we considered, time-limited knowledge transfer efficiency can differ by up to 9.08\%, thus highlighting the importance of this work.
PeerFL: A Simulator for Peer-to-Peer Federated Learning at Scale
May 28, 2024
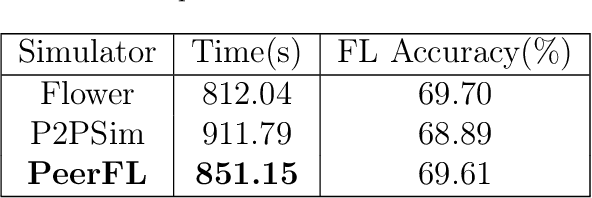
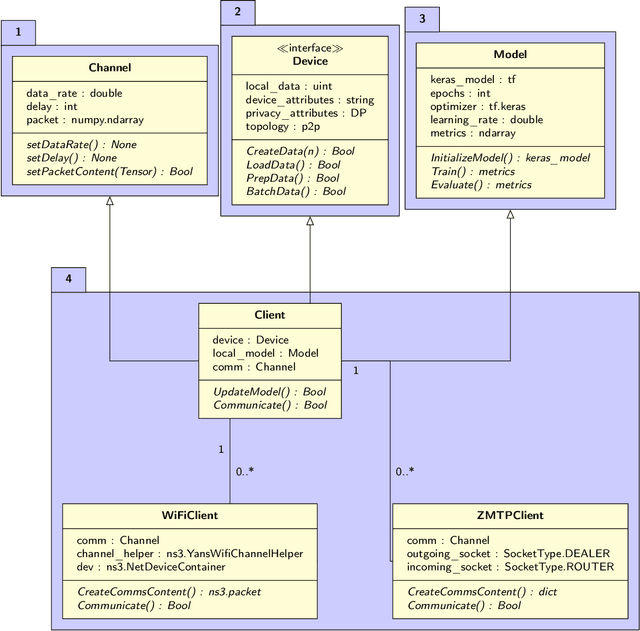
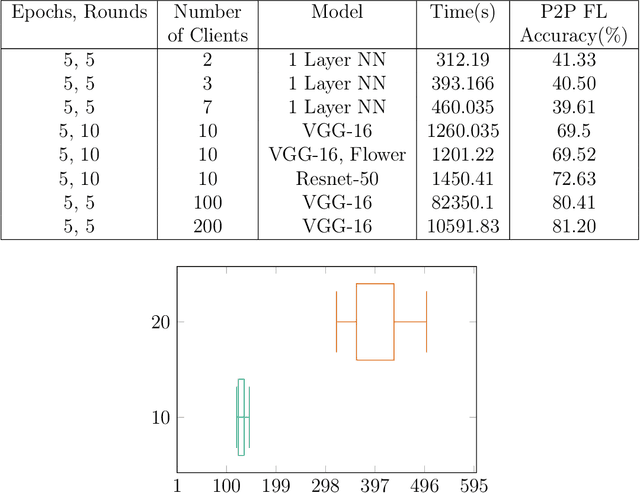
This work integrates peer-to-peer federated learning tools with NS3, a widely used network simulator, to create a novel simulator designed to allow heterogeneous device experiments in federated learning. This cross-platform adaptability addresses a critical gap in existing simulation tools, enhancing the overall utility and user experience. NS3 is leveraged to simulate WiFi dynamics to facilitate federated learning experiments with participants that move around physically during training, leading to dynamic network characteristics. Our experiments showcase the simulator's efficiency in computational resource utilization at scale, with a maximum of 450 heterogeneous devices modelled as participants in federated learning. This positions it as a valuable tool for simulation-based investigations in peer-to-peer federated learning. The framework is open source and available for use and extension to the community.