 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFVD: Inference-Time Alignment of Diffusion Models via Fleming-Viot Resampling
Apr 08, 2026We introduce Fleming-Viot Diffusion (FVD), an inference-time alignment method that resolves the diversity collapse commonly observed in Sequential Monte Carlo (SMC) based diffusion samplers. Existing SMC-based diffusion samplers often rely on multinomial resampling or closely related resampling schemes, which can still reduce diversity and lead to lineage collapse under strong selection pressure. Inspired by Fleming-Viot population dynamics, FVD replaces multinomial resampling with a specialized birth-death mechanism designed for diffusion alignment. To handle cases where rewards are only approximately available and naive rebirth would collapse deterministic trajectories, FVD integrates independent reward-based survival decisions with stochastic rebirth noise. This yields flexible population dynamics that preserve broader trajectory support while effectively exploring reward-tilted distributions, all without requiring value function approximation or costly rollouts. FVD is fully parallelizable and scales efficiently with inference compute. Empirically, it achieves substantial gains across settings: on DrawBench it outperforms prior methods by 7% in ImageReward, while on class-conditional tasks it improves FID by roughly 14-20% over strong baselines and is up to 66 times faster than value-based approaches.
GT-SVJ: Generative-Transformer-Based Self-Supervised Video Judge For Efficient Video Reward Modeling
Feb 05, 2026Aligning video generative models with human preferences remains challenging: current approaches rely on Vision-Language Models (VLMs) for reward modeling, but these models struggle to capture subtle temporal dynamics. We propose a fundamentally different approach: repurposing video generative models, which are inherently designed to model temporal structure, as reward models. We present the Generative-Transformer-based Self-Supervised Video Judge (\modelname), a novel evaluation model that transforms state-of-the-art video generation models into powerful temporally-aware reward models. Our key insight is that generative models can be reformulated as energy-based models (EBMs) that assign low energy to high-quality videos and high energy to degraded ones, enabling them to discriminate video quality with remarkable precision when trained via contrastive objectives. To prevent the model from exploiting superficial differences between real and generated videos, we design challenging synthetic negative videos through controlled latent-space perturbations: temporal slicing, feature swapping, and frame shuffling, which simulate realistic but subtle visual degradations. This forces the model to learn meaningful spatiotemporal features rather than trivial artifacts. \modelname achieves state-of-the-art performance on GenAI-Bench and MonteBench using only 30K human-annotations: $6\times$ to $65\times$ fewer than existing VLM-based approaches.
ROCM: RLHF on consistency models
Mar 08, 2025



Diffusion models have revolutionized generative modeling in continuous domains like image, audio, and video synthesis. However, their iterative sampling process leads to slow generation and inefficient training, challenges that are further exacerbated when incorporating Reinforcement Learning from Human Feedback (RLHF) due to sparse rewards and long time horizons. Consistency models address these issues by enabling single-step or efficient multi-step generation, significantly reducing computational costs. In this work, we propose a direct reward optimization framework for applying RLHF to consistency models, incorporating distributional regularization to enhance training stability and prevent reward hacking. We investigate various $f$-divergences as regularization strategies, striking a balance between reward maximization and model consistency. Unlike policy gradient methods, our approach leverages first-order gradients, making it more efficient and less sensitive to hyperparameter tuning. Empirical results show that our method achieves competitive or superior performance compared to policy gradient based RLHF methods, across various automatic metrics and human evaluation. Additionally, our analysis demonstrates the impact of different regularization techniques in improving model generalization and preventing overfitting.
SEE-DPO: Self Entropy Enhanced Direct Preference Optimization
Nov 06, 2024


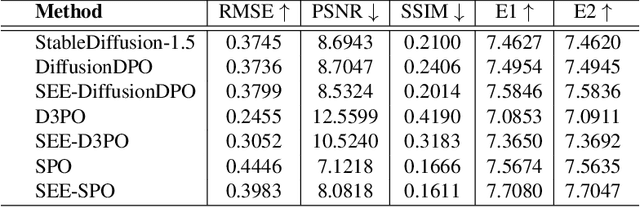
Direct Preference Optimization (DPO) has been successfully used to align large language models (LLMs) according to human preferences, and more recently it has also been applied to improving the quality of text-to-image diffusion models. However, DPO-based methods such as SPO, Diffusion-DPO, and D3PO are highly susceptible to overfitting and reward hacking, especially when the generative model is optimized to fit out-of-distribution during prolonged training. To overcome these challenges and stabilize the training of diffusion models, we introduce a self-entropy regularization mechanism in reinforcement learning from human feedback. This enhancement improves DPO training by encouraging broader exploration and greater robustness. Our regularization technique effectively mitigates reward hacking, leading to improved stability and enhanced image quality across the latent space. Extensive experiments demonstrate that integrating human feedback with self-entropy regularization can significantly boost image diversity and specificity, achieving state-of-the-art results on key image generation metrics.
PeerFL: A Simulator for Peer-to-Peer Federated Learning at Scale
May 28, 2024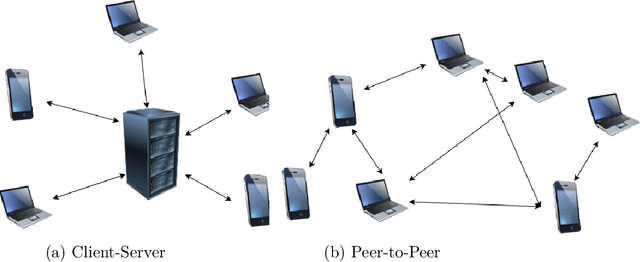
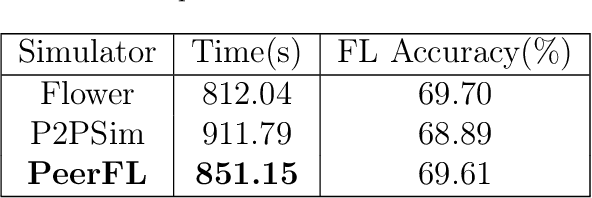
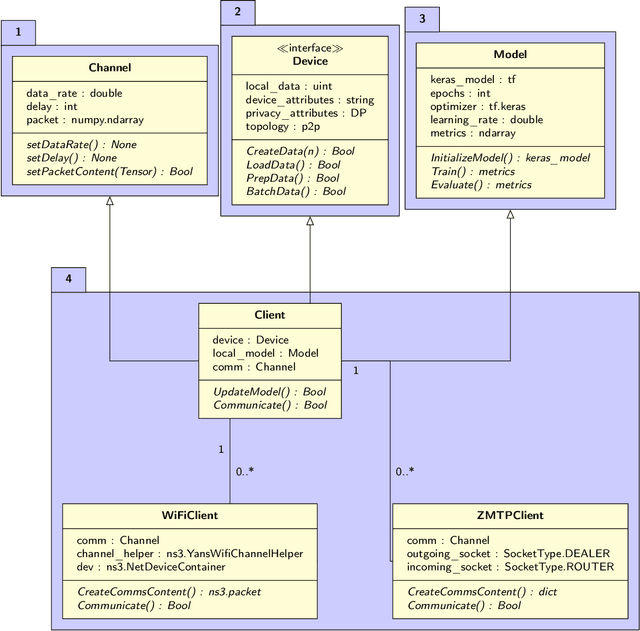
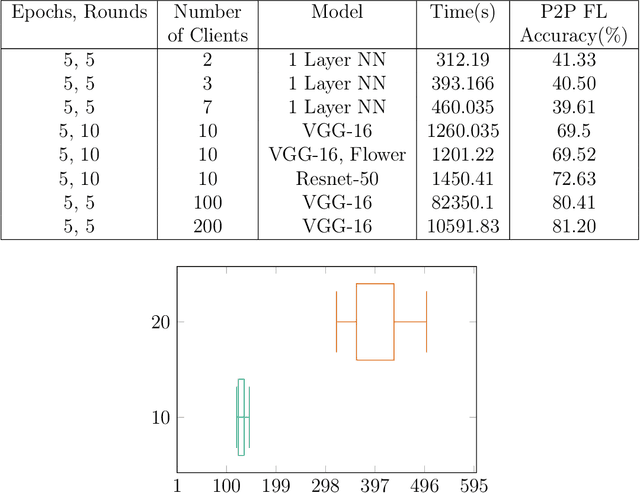
This work integrates peer-to-peer federated learning tools with NS3, a widely used network simulator, to create a novel simulator designed to allow heterogeneous device experiments in federated learning. This cross-platform adaptability addresses a critical gap in existing simulation tools, enhancing the overall utility and user experience. NS3 is leveraged to simulate WiFi dynamics to facilitate federated learning experiments with participants that move around physically during training, leading to dynamic network characteristics. Our experiments showcase the simulator's efficiency in computational resource utilization at scale, with a maximum of 450 heterogeneous devices modelled as participants in federated learning. This positions it as a valuable tool for simulation-based investigations in peer-to-peer federated learning. The framework is open source and available for use and extension to the community.
Towards Optimizing the Costs of LLM Usage
Jan 29, 2024Generative AI and LLMs in particular are heavily used nowadays for various document processing tasks such as question answering and summarization. However, different LLMs come with different capabilities for different tasks as well as with different costs, tokenization, and latency. In fact, enterprises are already incurring huge costs of operating or using LLMs for their respective use cases. In this work, we propose optimizing the usage costs of LLMs by estimating their output quality (without actually invoking the LLMs), and then solving an optimization routine for the LLM selection to either keep costs under a budget, or minimize the costs, in a quality and latency aware manner. We propose a model to predict the output quality of LLMs on document processing tasks like summarization, followed by an LP rounding algorithm to optimize the selection of LLMs. We study optimization problems trading off the quality and costs, both theoretically and empirically. We further propose a sentence simplification model for reducing the number of tokens in a controlled manner. Additionally, we propose several deterministic heuristics for reducing tokens in a quality aware manner, and study the related optimization problem of applying the heuristics optimizing the quality and cost trade-off. We perform extensive empirical validation of our methods on not only enterprise datasets but also on open-source datasets, annotated by us, and show that we perform much better compared to closest baselines. Our methods reduce costs by 40%- 90% while improving quality by 4%-7%. We will release the annotated open source datasets to the community for further research and exploration.