 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Noise-Aware Audio Deepfake Detection: Survey, SNR-Benchmarks, and Practical Recipes
Dec 15, 2025Deepfake audio detection has progressed rapidly with strong pre-trained encoders (e.g., WavLM, Wav2Vec2, MMS). However, performance in realistic capture conditions - background noise (domestic/office/transport), room reverberation, and consumer channels - often lags clean-lab results. We survey and evaluate robustness for state-of-the-art audio deepfake detection models and present a reproducible framework that mixes MS-SNSD noises with ASVspoof 2021 DF utterances to evaluate under controlled signal-to-noise ratios (SNRs). SNR is a measured proxy for noise severity used widely in speech; it lets us sweep from near-clean (35 dB) to very noisy (-5 dB) to quantify graceful degradation. We study multi-condition training and fixed-SNR testing for pretrained encoders (WavLM, Wav2Vec2, MMS), reporting accuracy, ROC-AUC, and EER on binary and four-class (authenticity x corruption) tasks. In our experiments, finetuning reduces EER by 10-15 percentage points at 10-0 dB SNR across backbones.
Federated Learning Optimization: A Comparative Study of Data and Model Exchange Strategies in Dynamic Networks
Jun 16, 2024



The promise and proliferation of large-scale dynamic federated learning gives rise to a prominent open question - is it prudent to share data or model across nodes, if efficiency of transmission and fast knowledge transfer are the prime objectives. This work investigates exactly that. Specifically, we study the choices of exchanging raw data, synthetic data, or (partial) model updates among devices. The implications of these strategies in the context of foundational models are also examined in detail. Accordingly, we obtain key insights about optimal data and model exchange mechanisms considering various environments with different data distributions and dynamic device and network connections. Across various scenarios that we considered, time-limited knowledge transfer efficiency can differ by up to 9.08\%, thus highlighting the importance of this work.
PeerFL: A Simulator for Peer-to-Peer Federated Learning at Scale
May 28, 2024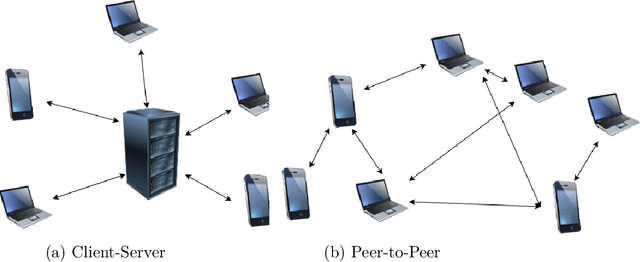
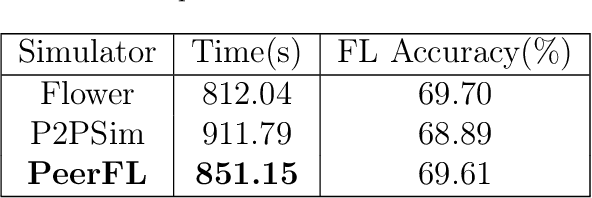
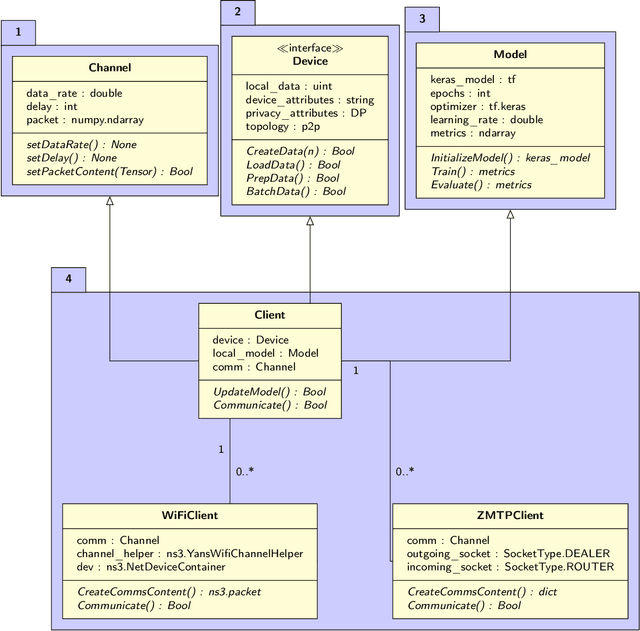
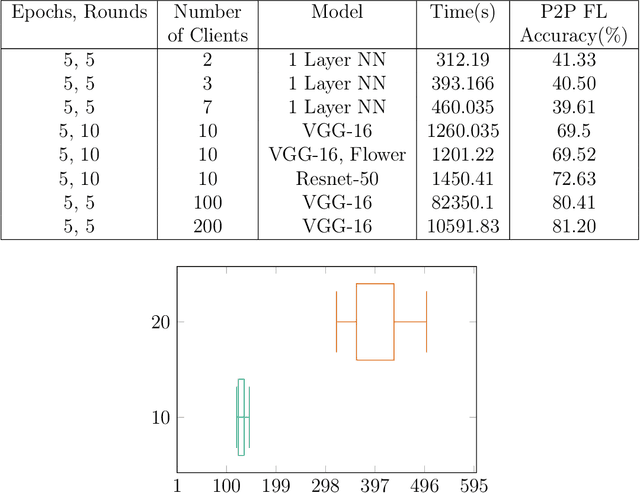
This work integrates peer-to-peer federated learning tools with NS3, a widely used network simulator, to create a novel simulator designed to allow heterogeneous device experiments in federated learning. This cross-platform adaptability addresses a critical gap in existing simulation tools, enhancing the overall utility and user experience. NS3 is leveraged to simulate WiFi dynamics to facilitate federated learning experiments with participants that move around physically during training, leading to dynamic network characteristics. Our experiments showcase the simulator's efficiency in computational resource utilization at scale, with a maximum of 450 heterogeneous devices modelled as participants in federated learning. This positions it as a valuable tool for simulation-based investigations in peer-to-peer federated learning. The framework is open source and available for use and extension to the community.
Privacy and Security Implications of Cloud-Based AI Services : A Survey
Jan 31, 2024This paper details the privacy and security landscape in today's cloud ecosystem and identifies that there is a gap in addressing the risks introduced by machine learning models. As machine learning algorithms continue to evolve and find applications across diverse domains, the need to categorize and quantify privacy and security risks becomes increasingly critical. With the emerging trend of AI-as-a-Service (AIaaS), machine learned AI models (or ML models) are deployed on the cloud by model providers and used by model consumers. We first survey the AIaaS landscape to document the various kinds of liabilities that ML models, especially Deep Neural Networks pose and then introduce a taxonomy to bridge this gap by holistically examining the risks that creators and consumers of ML models are exposed to and their known defences till date. Such a structured approach will be beneficial for ML model providers to create robust solutions. Likewise, ML model consumers will find it valuable to evaluate such solutions and understand the implications of their engagement with such services. The proposed taxonomies provide a foundational basis for solutions in private, secure and robust ML, paving the way for more transparent and resilient AI systems.