 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextFocus: Activation Steering for Contextual Faithfulness in Large Language Models
Jan 07, 2026Large Language Models (LLMs) encode vast amounts of parametric knowledge during pre-training. As world knowledge evolves, effective deployment increasingly depends on their ability to faithfully follow externally retrieved context. When such evidence conflicts with the model's internal knowledge, LLMs often default to memorized facts, producing unfaithful outputs. In this work, we introduce ContextFocus, a lightweight activation steering approach that improves context faithfulness in such knowledge-conflict settings while preserving fluency and efficiency. Unlike prior approaches, our solution requires no model finetuning and incurs minimal inference-time overhead, making it highly efficient. We evaluate ContextFocus on the ConFiQA benchmark, comparing it against strong baselines including ContextDPO, COIECD, and prompting-based methods. Furthermore, we show that our method is complementary to prompting strategies and remains effective on larger models. Extensive experiments show that ContextFocus significantly improves contextual-faithfulness. Our results highlight the effectiveness, robustness, and efficiency of ContextFocus in improving contextual-faithfulness of LLM outputs.
From Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
PromptRefine: Enhancing Few-Shot Performance on Low-Resource Indic Languages with Example Selection from Related Example Banks
Dec 07, 2024



Large Language Models (LLMs) have recently demonstrated impressive few-shot learning capabilities through in-context learning (ICL). However, ICL performance is highly dependent on the choice of few-shot demonstrations, making the selection of the most optimal examples a persistent research challenge. This issue is further amplified in low-resource Indic languages, where the scarcity of ground-truth data complicates the selection process. In this work, we propose PromptRefine, a novel Alternating Minimization approach for example selection that improves ICL performance on low-resource Indic languages. PromptRefine leverages auxiliary example banks from related high-resource Indic languages and employs multi-task learning techniques to align language-specific retrievers, enabling effective cross-language retrieval. Additionally, we incorporate diversity in the selected examples to enhance generalization and reduce bias. Through comprehensive evaluations on four text generation tasks -- Cross-Lingual Question Answering, Multilingual Question Answering, Machine Translation, and Cross-Lingual Summarization using state-of-the-art LLMs such as LLAMA-3.1-8B, LLAMA-2-7B, Qwen-2-7B, and Qwen-2.5-7B, we demonstrate that PromptRefine significantly outperforms existing frameworks for retrieving examples.
FiRST: Finetuning Router-Selective Transformers for Input-Adaptive Latency Reduction
Oct 16, 2024

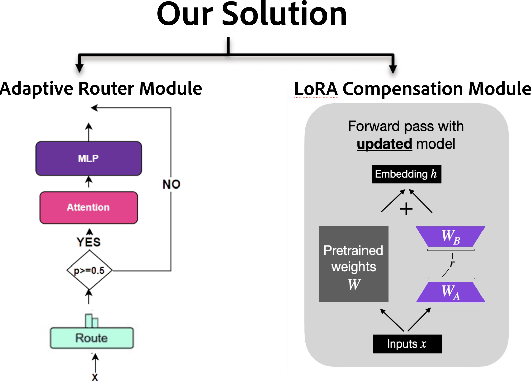

Auto-regressive Large Language Models (LLMs) demonstrate remarkable performance across domanins such as vision and language processing. However, due to sequential processing through a stack of transformer layers, autoregressive decoding faces significant computation/latency challenges, particularly in resource constrained environments like mobile and edge devices. Existing approaches in literature that aim to improve latency via skipping layers have two distinct flavors - 1) Early exit 2) Input-agnostic heuristics where tokens exit at pre-determined layers irrespective of input sequence. Both the above strategies have limitations - the former cannot be applied to handle KV Caching necessary for speed-ups in modern framework and the latter does not capture the variation in layer importance across tasks or more generally, across input sequences. To address both limitations, we propose FIRST, an algorithm that reduces inference latency by using layer-specific routers to select a subset of transformer layers adaptively for each input sequence - the prompt (during prefill stage) decides which layers will be skipped during decoding. FIRST preserves compatibility with KV caching enabling faster inference while being quality-aware. FIRST is model-agnostic and can be easily enabled on any pre-trained LLM. We further improve performance by incorporating LoRA adapters for fine-tuning on external datasets, enhancing task-specific accuracy while maintaining latency benefits. Our approach reveals that input adaptivity is critical - indeed, different task-specific middle layers play a crucial role in evolving hidden representations depending on task. Extensive experiments show that FIRST significantly reduces latency while retaining competitive performance (as compared to baselines), making our approach an efficient solution for LLM deployment in low-resource environments.
Towards Optimizing the Costs of LLM Usage
Jan 29, 2024Generative AI and LLMs in particular are heavily used nowadays for various document processing tasks such as question answering and summarization. However, different LLMs come with different capabilities for different tasks as well as with different costs, tokenization, and latency. In fact, enterprises are already incurring huge costs of operating or using LLMs for their respective use cases. In this work, we propose optimizing the usage costs of LLMs by estimating their output quality (without actually invoking the LLMs), and then solving an optimization routine for the LLM selection to either keep costs under a budget, or minimize the costs, in a quality and latency aware manner. We propose a model to predict the output quality of LLMs on document processing tasks like summarization, followed by an LP rounding algorithm to optimize the selection of LLMs. We study optimization problems trading off the quality and costs, both theoretically and empirically. We further propose a sentence simplification model for reducing the number of tokens in a controlled manner. Additionally, we propose several deterministic heuristics for reducing tokens in a quality aware manner, and study the related optimization problem of applying the heuristics optimizing the quality and cost trade-off. We perform extensive empirical validation of our methods on not only enterprise datasets but also on open-source datasets, annotated by us, and show that we perform much better compared to closest baselines. Our methods reduce costs by 40%- 90% while improving quality by 4%-7%. We will release the annotated open source datasets to the community for further research and exploration.
Approximate Caching for Efficiently Serving Diffusion Models
Dec 07, 2023
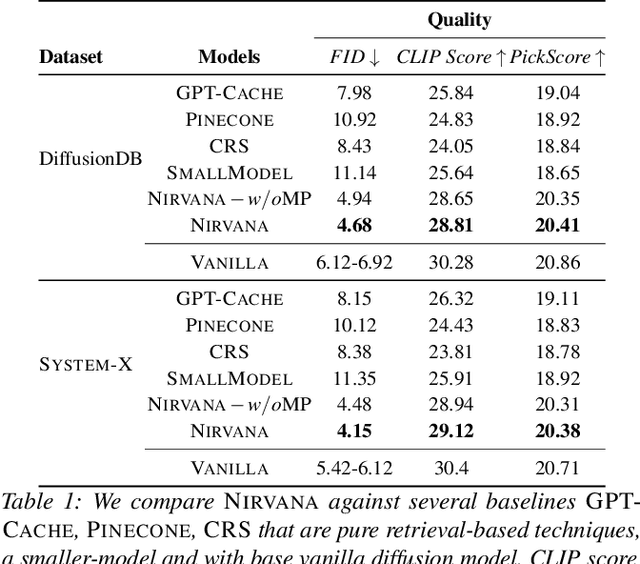

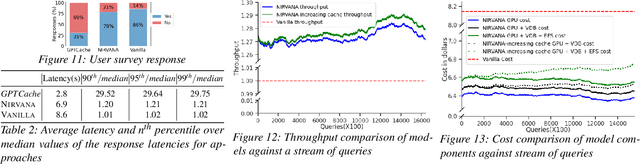
Text-to-image generation using diffusion models has seen explosive popularity owing to their ability in producing high quality images adhering to text prompts. However, production-grade diffusion model serving is a resource intensive task that not only require high-end GPUs which are expensive but also incurs considerable latency. In this paper, we introduce a technique called approximate-caching that can reduce such iterative denoising steps for an image generation based on a prompt by reusing intermediate noise states created during a prior image generation for similar prompts. Based on this idea, we present an end to end text-to-image system, Nirvana, that uses the approximate-caching with a novel cache management-policy Least Computationally Beneficial and Frequently Used (LCBFU) to provide % GPU compute savings, 19.8% end-to-end latency reduction and 19% dollar savings, on average, on two real production workloads. We further present an extensive characterization of real production text-to-image prompts from the perspective of caching, popularity and reuse of intermediate states in a large production environment.
A Simple Dynamic Learning Rate Tuning Algorithm For Automated Training of DNNs
Oct 25, 2019
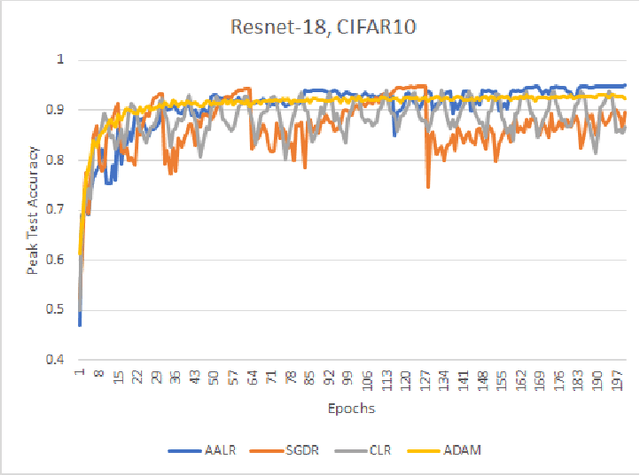

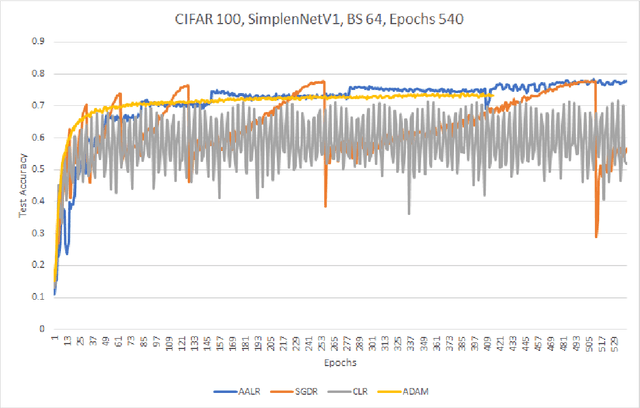
Training neural networks on image datasets generally require extensive experimentation to find the optimal learning rate regime. Especially, for the cases of adversarial training or for training a newly synthesized model, one would not know the best learning rate regime beforehand. We propose an automated algorithm for determining the learning rate trajectory, that works across datasets and models for both natural and adversarial training, without requiring any dataset/model specific tuning. It is a stand-alone, parameterless, adaptive approach with no computational overhead. We theoretically discuss the algorithm's convergence behavior. We empirically validate our algorithm extensively. Our results show that our proposed approach \emph{consistently} achieves top-level accuracy compared to SOTA baselines in the literature in natural as well as adversarial training.
Layer Dynamics of Linearised Neural Nets
Apr 24, 2019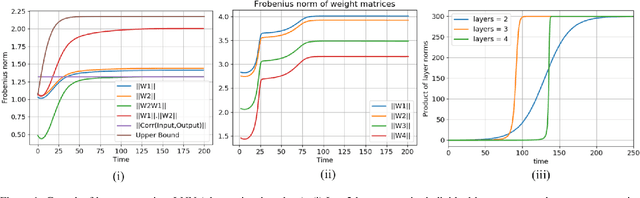
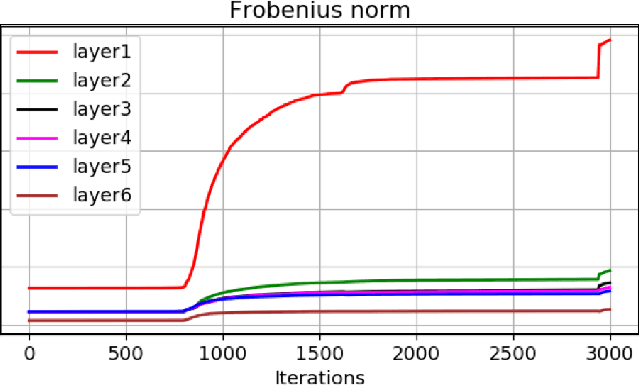
Despite the phenomenal success of deep learning in recent years, there remains a gap in understanding the fundamental mechanics of neural nets. More research is focussed on handcrafting complex and larger networks, and the design decisions are often ad-hoc and based on intuition. Some recent research has aimed to demystify the learning dynamics in neural nets by attempting to build a theory from first principles, such as characterising the non-linear dynamics of specialised \textit{linear} deep neural nets (such as orthogonal networks). In this work, we expand and derive properties of learning dynamics respected by general multi-layer linear neural nets. Although an over-parameterisation of a single layer linear network, linear multi-layer neural nets offer interesting insights that explain how learning dynamics proceed in small pockets of the data space. We show in particular that multiple layers in linear nets grow at approximately the same rate, and there are distinct phases of learning with markedly different layer growth. We then apply a linearisation process to a general RelU neural net and show how nonlinearity breaks down the growth symmetry observed in liner neural nets. Overall, our work can be viewed as an initial step in building a theory for understanding the effect of layer design on the learning dynamics from first principles.
Learning to Partition using Score Based Compatibilities
Mar 22, 2017
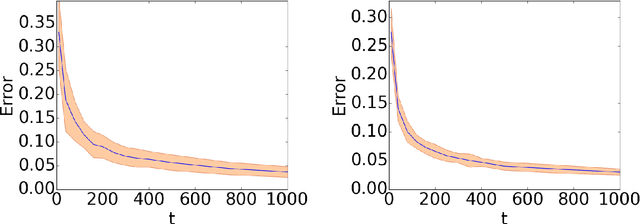
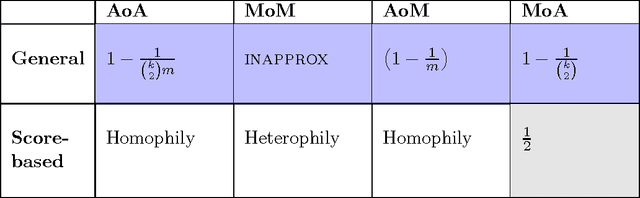
We study the problem of learning to partition users into groups, where one must learn the compatibilities between the users to achieve optimal groupings. We define four natural objectives that optimize for average and worst case compatibilities and propose new algorithms for adaptively learning optimal groupings. When we do not impose any structure on the compatibilities, we show that the group formation objectives considered are $NP$ hard to solve and we either give approximation guarantees or prove inapproximability results. We then introduce an elegant structure, namely that of \textit{intrinsic scores}, that makes many of these problems polynomial time solvable. We explicitly characterize the optimal groupings under this structure and show that the optimal solutions are related to \emph{homophilous} and \emph{heterophilous} partitions, well-studied in the psychology literature. For one of the four objectives, we show $NP$ hardness under the score structure and give a $\frac{1}{2}$ approximation algorithm for which no constant approximation was known thus far. Finally, under the score structure, we propose an online low sample complexity PAC algorithm for learning the optimal partition. We demonstrate the efficacy of the proposed algorithm on synthetic and real world datasets.
A Game-Theoretic Model Motivated by the DARPA Network Challenge
Jan 30, 2013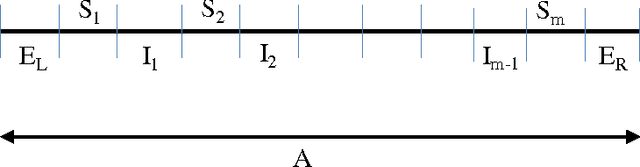
In this paper we propose a game-theoretic model to analyze events similar to the 2009 \emph{DARPA Network Challenge}, which was organized by the Defense Advanced Research Projects Agency (DARPA) for exploring the roles that the Internet and social networks play in incentivizing wide-area collaborations. The challenge was to form a group that would be the first to find the locations of ten moored weather balloons across the United States. We consider a model in which $N$ people (who can form groups) are located in some topology with a fixed coverage volume around each person's geographical location. We consider various topologies where the players can be located such as the Euclidean $d$-dimension space and the vertices of a graph. A balloon is placed in the space and a group wins if it is the first one to report the location of the balloon. A larger team has a higher probability of finding the balloon, but we assume that the prize money is divided equally among the team members. Hence there is a competing tension to keep teams as small as possible. \emph{Risk aversion} is the reluctance of a person to accept a bargain with an uncertain payoff rather than another bargain with a more certain, but possibly lower, expected payoff. In our model we consider the \emph{isoelastic} utility function derived from the Arrow-Pratt measure of relative risk aversion. The main aim is to analyze the structures of the groups in Nash equilibria for our model. For the $d$-dimensional Euclidean space ($d\geq 1$) and the class of bounded degree regular graphs we show that in any Nash Equilibrium the \emph{richest} group (having maximum expected utility per person) covers a constant fraction of the total volume.