 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiRST: Finetuning Router-Selective Transformers for Input-Adaptive Latency Reduction
Oct 16, 2024

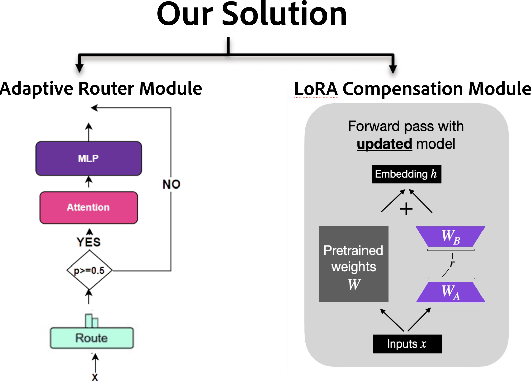

Auto-regressive Large Language Models (LLMs) demonstrate remarkable performance across domanins such as vision and language processing. However, due to sequential processing through a stack of transformer layers, autoregressive decoding faces significant computation/latency challenges, particularly in resource constrained environments like mobile and edge devices. Existing approaches in literature that aim to improve latency via skipping layers have two distinct flavors - 1) Early exit 2) Input-agnostic heuristics where tokens exit at pre-determined layers irrespective of input sequence. Both the above strategies have limitations - the former cannot be applied to handle KV Caching necessary for speed-ups in modern framework and the latter does not capture the variation in layer importance across tasks or more generally, across input sequences. To address both limitations, we propose FIRST, an algorithm that reduces inference latency by using layer-specific routers to select a subset of transformer layers adaptively for each input sequence - the prompt (during prefill stage) decides which layers will be skipped during decoding. FIRST preserves compatibility with KV caching enabling faster inference while being quality-aware. FIRST is model-agnostic and can be easily enabled on any pre-trained LLM. We further improve performance by incorporating LoRA adapters for fine-tuning on external datasets, enhancing task-specific accuracy while maintaining latency benefits. Our approach reveals that input adaptivity is critical - indeed, different task-specific middle layers play a crucial role in evolving hidden representations depending on task. Extensive experiments show that FIRST significantly reduces latency while retaining competitive performance (as compared to baselines), making our approach an efficient solution for LLM deployment in low-resource environments.