 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Selection to Generation: A Survey of LLM-based Active Learning
Feb 17, 2025Active Learning (AL) has been a powerful paradigm for improving model efficiency and performance by selecting the most informative data points for labeling and training. In recent active learning frameworks, Large Language Models (LLMs) have been employed not only for selection but also for generating entirely new data instances and providing more cost-effective annotations. Motivated by the increasing importance of high-quality data and efficient model training in the era of LLMs, we present a comprehensive survey on LLM-based Active Learning. We introduce an intuitive taxonomy that categorizes these techniques and discuss the transformative roles LLMs can play in the active learning loop. We further examine the impact of AL on LLM learning paradigms and its applications across various domains. Finally, we identify open challenges and propose future research directions. This survey aims to serve as an up-to-date resource for researchers and practitioners seeking to gain an intuitive understanding of LLM-based AL techniques and deploy them to new applications.
GUI Agents: A Survey
Dec 18, 2024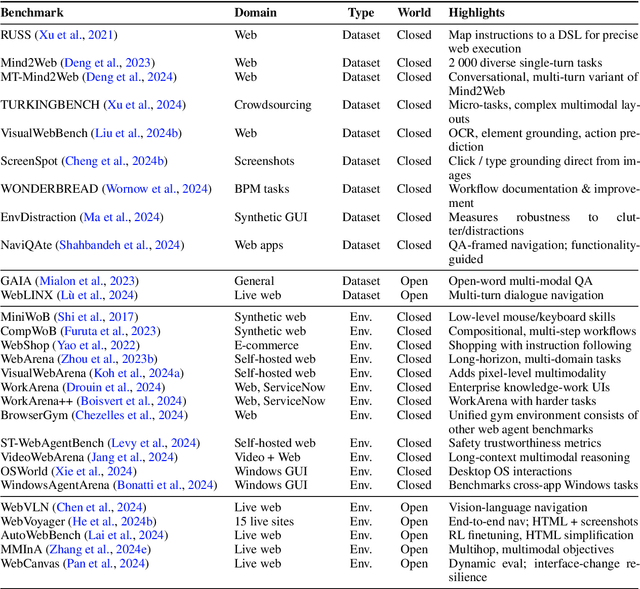
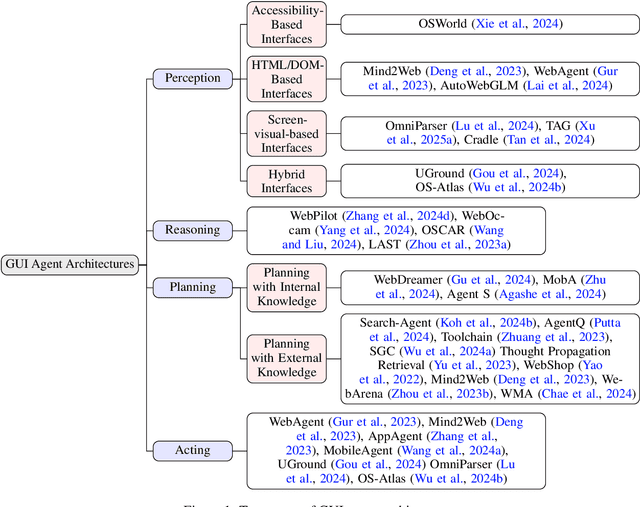

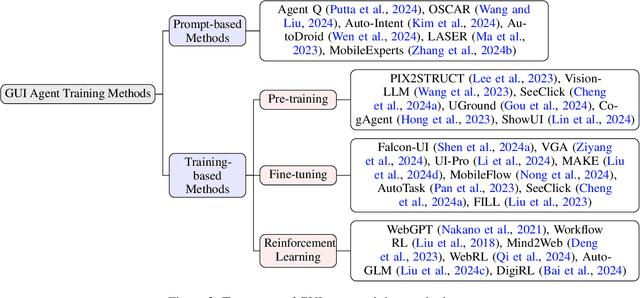
Graphical User Interface (GUI) agents, powered by Large Foundation Models, have emerged as a transformative approach to automating human-computer interaction. These agents autonomously interact with digital systems or software applications via GUIs, emulating human actions such as clicking, typing, and navigating visual elements across diverse platforms. Motivated by the growing interest and fundamental importance of GUI agents, we provide a comprehensive survey that categorizes their benchmarks, evaluation metrics, architectures, and training methods. We propose a unified framework that delineates their perception, reasoning, planning, and acting capabilities. Furthermore, we identify important open challenges and discuss key future directions. Finally, this work serves as a basis for practitioners and researchers to gain an intuitive understanding of current progress, techniques, benchmarks, and critical open problems that remain to be addressed.
A Survey of Small Language Models
Oct 25, 2024


Small Language Models (SLMs) have become increasingly important due to their efficiency and performance to perform various language tasks with minimal computational resources, making them ideal for various settings including on-device, mobile, edge devices, among many others. In this article, we present a comprehensive survey on SLMs, focusing on their architectures, training techniques, and model compression techniques. We propose a novel taxonomy for categorizing the methods used to optimize SLMs, including model compression, pruning, and quantization techniques. We summarize the benchmark datasets that are useful for benchmarking SLMs along with the evaluation metrics commonly used. Additionally, we highlight key open challenges that remain to be addressed. Our survey aims to serve as a valuable resource for researchers and practitioners interested in developing and deploying small yet efficient language models.
A Framework for Fine-Tuning LLMs using Heterogeneous Feedback
Aug 05, 2024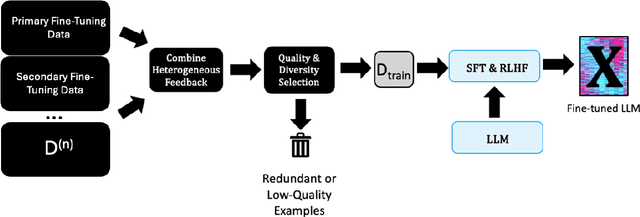
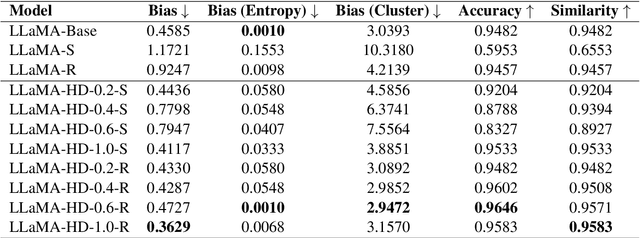
Large language models (LLMs) have been applied to a wide range of tasks, including text summarization, web navigation, and chatbots. They have benefitted from supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) following an unsupervised pretraining. These datasets can be difficult to collect, limited in scope, and vary in sample quality. Additionally, datasets can vary extensively in supervision format, from numerical to binary as well as multi-dimensional with many different values. We present a framework for fine-tuning LLMs using heterogeneous feedback, which has two main components. First, we combine the heterogeneous feedback data into a single supervision format, compatible with methods like SFT and RLHF. Next, given this unified feedback dataset, we extract a high-quality and diverse subset to obtain performance increases potentially exceeding the full dataset. We conduct extensive experiments to understand the effectiveness of these techniques for incorporating heterogeneous feedback, and demonstrate improvements from using a high-quality and diverse subset of the data. We find that our framework is able to improve models in multiple areas simultaneously, such as in instruction following and bias reduction.
A Hypergraph Neural Network Framework for Learning Hyperedge-Dependent Node Embeddings
Dec 28, 2022In this work, we introduce a hypergraph representation learning framework called Hypergraph Neural Networks (HNN) that jointly learns hyperedge embeddings along with a set of hyperedge-dependent embeddings for each node in the hypergraph. HNN derives multiple embeddings per node in the hypergraph where each embedding for a node is dependent on a specific hyperedge of that node. Notably, HNN is accurate, data-efficient, flexible with many interchangeable components, and useful for a wide range of hypergraph learning tasks. We evaluate the effectiveness of the HNN framework for hyperedge prediction and hypergraph node classification. We find that HNN achieves an overall mean gain of 7.72% and 11.37% across all baseline models and graphs for hyperedge prediction and hypergraph node classification, respectively.