 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Fine-Tuning LLMs using Heterogeneous Feedback
Paper and Code
Aug 05, 2024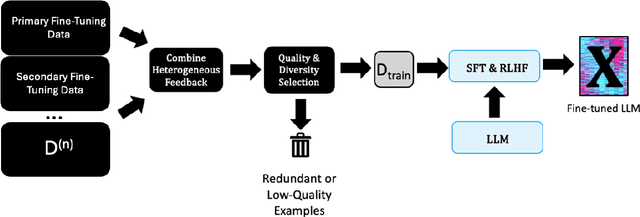
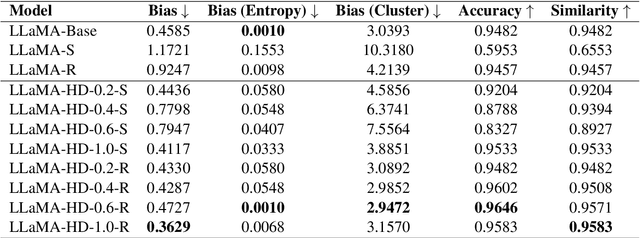
Large language models (LLMs) have been applied to a wide range of tasks, including text summarization, web navigation, and chatbots. They have benefitted from supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) following an unsupervised pretraining. These datasets can be difficult to collect, limited in scope, and vary in sample quality. Additionally, datasets can vary extensively in supervision format, from numerical to binary as well as multi-dimensional with many different values. We present a framework for fine-tuning LLMs using heterogeneous feedback, which has two main components. First, we combine the heterogeneous feedback data into a single supervision format, compatible with methods like SFT and RLHF. Next, given this unified feedback dataset, we extract a high-quality and diverse subset to obtain performance increases potentially exceeding the full dataset. We conduct extensive experiments to understand the effectiveness of these techniques for incorporating heterogeneous feedback, and demonstrate improvements from using a high-quality and diverse subset of the data. We find that our framework is able to improve models in multiple areas simultaneously, such as in instruction following and bias reduction.