 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnGoal: Tracking and Visualizing Conversational Goals in Multi-Turn Dialogue with Large Language Models
Aug 28, 2025
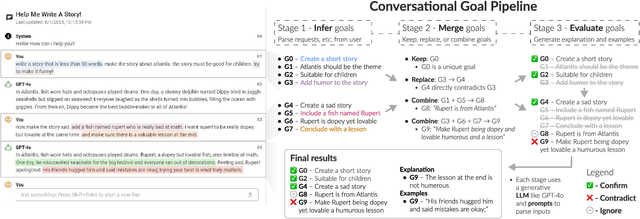

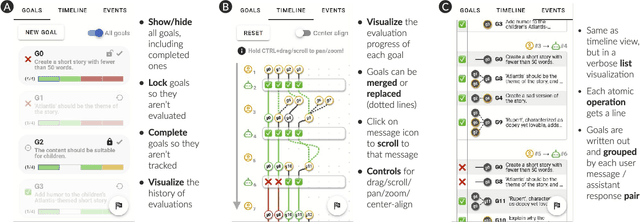
As multi-turn dialogues with large language models (LLMs) grow longer and more complex, how can users better evaluate and review progress on their conversational goals? We present OnGoal, an LLM chat interface that helps users better manage goal progress. OnGoal provides real-time feedback on goal alignment through LLM-assisted evaluation, explanations for evaluation results with examples, and overviews of goal progression over time, enabling users to navigate complex dialogues more effectively. Through a study with 20 participants on a writing task, we evaluate OnGoal against a baseline chat interface without goal tracking. Using OnGoal, participants spent less time and effort to achieve their goals while exploring new prompting strategies to overcome miscommunication, suggesting tracking and visualizing goals can enhance engagement and resilience in LLM dialogues. Our findings inspired design implications for future LLM chat interfaces that improve goal communication, reduce cognitive load, enhance interactivity, and enable feedback to improve LLM performance.
A Framework for Fine-Tuning LLMs using Heterogeneous Feedback
Aug 05, 2024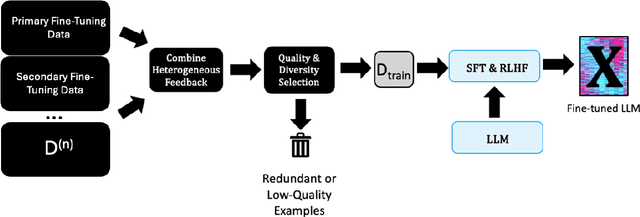
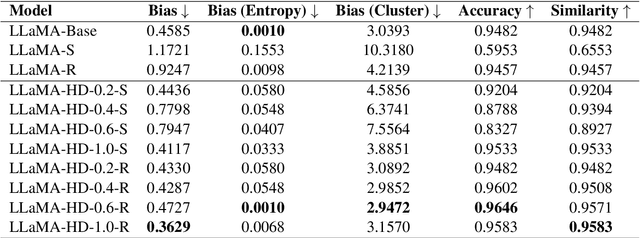
Large language models (LLMs) have been applied to a wide range of tasks, including text summarization, web navigation, and chatbots. They have benefitted from supervised fine-tuning (SFT) and reinforcement learning from human feedback (RLHF) following an unsupervised pretraining. These datasets can be difficult to collect, limited in scope, and vary in sample quality. Additionally, datasets can vary extensively in supervision format, from numerical to binary as well as multi-dimensional with many different values. We present a framework for fine-tuning LLMs using heterogeneous feedback, which has two main components. First, we combine the heterogeneous feedback data into a single supervision format, compatible with methods like SFT and RLHF. Next, given this unified feedback dataset, we extract a high-quality and diverse subset to obtain performance increases potentially exceeding the full dataset. We conduct extensive experiments to understand the effectiveness of these techniques for incorporating heterogeneous feedback, and demonstrate improvements from using a high-quality and diverse subset of the data. We find that our framework is able to improve models in multiple areas simultaneously, such as in instruction following and bias reduction.
A Hypergraph Neural Network Framework for Learning Hyperedge-Dependent Node Embeddings
Dec 28, 2022In this work, we introduce a hypergraph representation learning framework called Hypergraph Neural Networks (HNN) that jointly learns hyperedge embeddings along with a set of hyperedge-dependent embeddings for each node in the hypergraph. HNN derives multiple embeddings per node in the hypergraph where each embedding for a node is dependent on a specific hyperedge of that node. Notably, HNN is accurate, data-efficient, flexible with many interchangeable components, and useful for a wide range of hypergraph learning tasks. We evaluate the effectiveness of the HNN framework for hyperedge prediction and hypergraph node classification. We find that HNN achieves an overall mean gain of 7.72% and 11.37% across all baseline models and graphs for hyperedge prediction and hypergraph node classification, respectively.
Graph Learning with Localized Neighborhood Fairness
Dec 22, 2022Learning fair graph representations for downstream applications is becoming increasingly important, but existing work has mostly focused on improving fairness at the global level by either modifying the graph structure or objective function without taking into account the local neighborhood of a node. In this work, we formally introduce the notion of neighborhood fairness and develop a computational framework for learning such locally fair embeddings. We argue that the notion of neighborhood fairness is more appropriate since GNN-based models operate at the local neighborhood level of a node. Our neighborhood fairness framework has two main components that are flexible for learning fair graph representations from arbitrary data: the first aims to construct fair neighborhoods for any arbitrary node in a graph and the second enables adaption of these fair neighborhoods to better capture certain application or data-dependent constraints, such as allowing neighborhoods to be more biased towards certain attributes or neighbors in the graph.Furthermore, while link prediction has been extensively studied, we are the first to investigate the graph representation learning task of fair link classification. We demonstrate the effectiveness of the proposed neighborhood fairness framework for a variety of graph machine learning tasks including fair link prediction, link classification, and learning fair graph embeddings. Notably, our approach achieves not only better fairness but also increases the accuracy in the majority of cases across a wide variety of graphs, problem settings, and metrics.
Direct Embedding of Temporal Network Edges via Time-Decayed Line Graphs
Sep 30, 2022
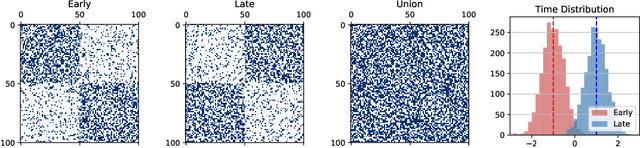
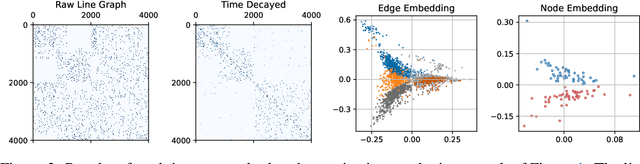
Temporal networks model a variety of important phenomena involving timed interactions between entities. Existing methods for machine learning on temporal networks generally exhibit at least one of two limitations. First, time is assumed to be discretized, so if the time data is continuous, the user must determine the discretization and discard precise time information. Second, edge representations can only be calculated indirectly from the nodes, which may be suboptimal for tasks like edge classification. We present a simple method that avoids both shortcomings: construct the line graph of the network, which includes a node for each interaction, and weigh the edges of this graph based on the difference in time between interactions. From this derived graph, edge representations for the original network can be computed with efficient classical methods. The simplicity of this approach facilitates explicit theoretical analysis: we can constructively show the effectiveness of our method's representations for a natural synthetic model of temporal networks. Empirical results on real-world networks demonstrate our method's efficacy and efficiency on both edge classification and temporal link prediction.
Visual Causality Analysis of Event Sequence Data
Sep 01, 2020
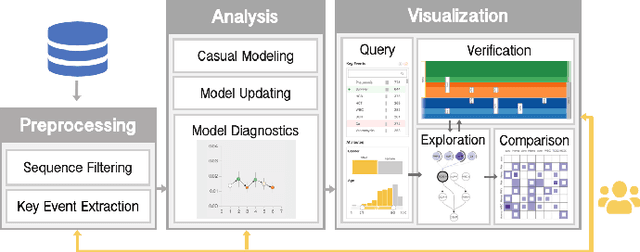
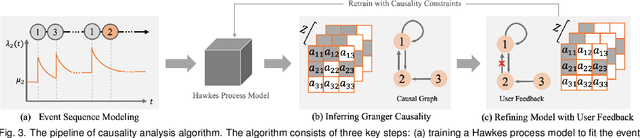
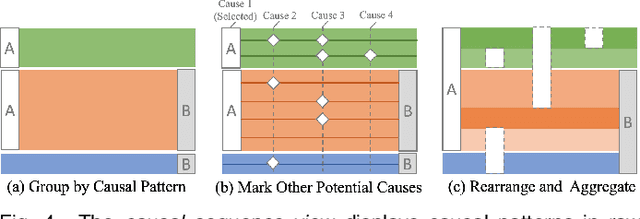
Causality is crucial to understanding the mechanisms behind complex systems and making decisions that lead to intended outcomes. Event sequence data is widely collected from many real-world processes, such as electronic health records, web clickstreams, and financial transactions, which transmit a great deal of information reflecting the causal relations among event types. Unfortunately, recovering causalities from observational event sequences is challenging, as the heterogeneous and high-dimensional event variables are often connected to rather complex underlying event excitation mechanisms that are hard to infer from limited observations. Many existing automated causal analysis techniques suffer from poor explainability and fail to include an adequate amount of human knowledge. In this paper, we introduce a visual analytics method for recovering causalities in event sequence data. We extend the Granger causality analysis algorithm on Hawkes processes to incorporate user feedback into causal model refinement. The visualization system includes an interactive causal analysis framework that supports bottom-up causal exploration, iterative causal verification and refinement, and causal comparison through a set of novel visualizations and interactions. We report two forms of evaluation: a quantitative evaluation of the model improvements resulting from the user-feedback mechanism, and a qualitative evaluation through case studies in different application domains to demonstrate the usefulness of the system.