 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKunlun: Establishing Scaling Laws for Massive-Scale Recommendation Systems through Unified Architecture Design
Feb 13, 2026Deriving predictable scaling laws that govern the relationship between model performance and computational investment is crucial for designing and allocating resources in massive-scale recommendation systems. While such laws are established for large language models, they remain challenging for recommendation systems, especially those processing both user history and context features. We identify poor scaling efficiency as the main barrier to predictable power-law scaling, stemming from inefficient modules with low Model FLOPs Utilization (MFU) and suboptimal resource allocation. We introduce Kunlun, a scalable architecture that systematically improves model efficiency and resource allocation. Our low-level optimizations include Generalized Dot-Product Attention (GDPA), Hierarchical Seed Pooling (HSP), and Sliding Window Attention. Our high-level innovations feature Computation Skip (CompSkip) and Event-level Personalization. These advances increase MFU from 17% to 37% on NVIDIA B200 GPUs and double scaling efficiency over state-of-the-art methods. Kunlun is now deployed in major Meta Ads models, delivering significant production impact.
On the Role of Edge Dependency in Graph Generative Models
Dec 06, 2023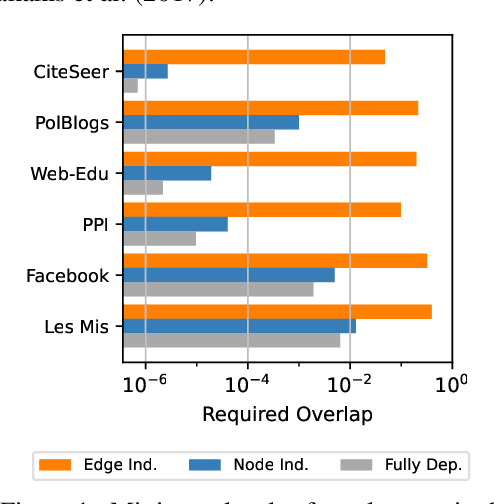

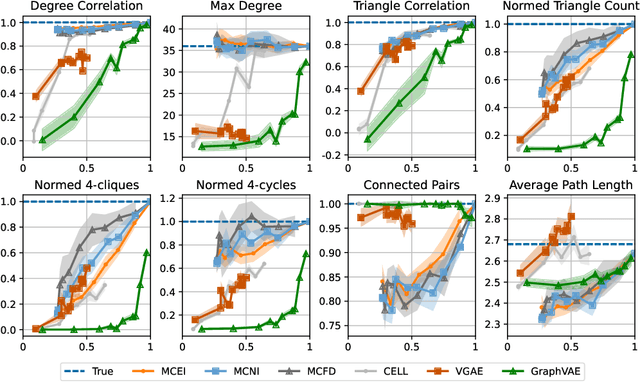
In this work, we introduce a novel evaluation framework for generative models of graphs, emphasizing the importance of model-generated graph overlap (Chanpuriya et al., 2021) to ensure both accuracy and edge-diversity. We delineate a hierarchy of graph generative models categorized into three levels of complexity: edge independent, node independent, and fully dependent models. This hierarchy encapsulates a wide range of prevalent methods. We derive theoretical bounds on the number of triangles and other short-length cycles producible by each level of the hierarchy, contingent on the model overlap. We provide instances demonstrating the asymptotic optimality of our bounds. Furthermore, we introduce new generative models for each of the three hierarchical levels, leveraging dense subgraph discovery (Gionis & Tsourakakis, 2015). Our evaluation, conducted on real-world datasets, focuses on assessing the output quality and overlap of our proposed models in comparison to other popular models. Our results indicate that our simple, interpretable models provide competitive baselines to popular generative models. Through this investigation, we aim to propel the advancement of graph generative models by offering a structured framework and robust evaluation metrics, thereby facilitating the development of models capable of generating accurate and edge-diverse graphs.
Latent Random Steps as Relaxations of Max-Cut, Min-Cut, and More
Aug 12, 2023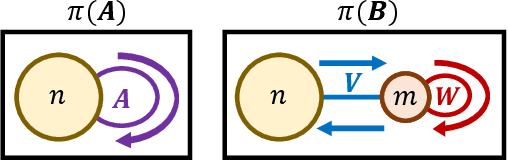
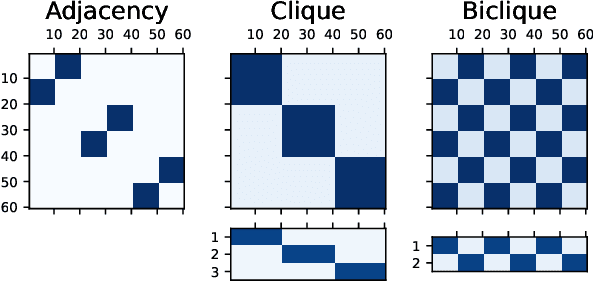
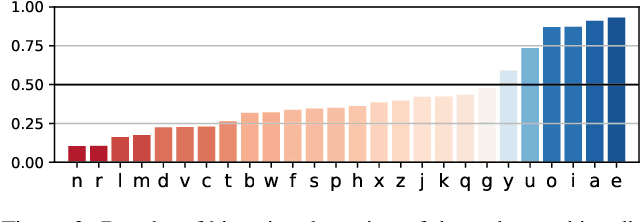
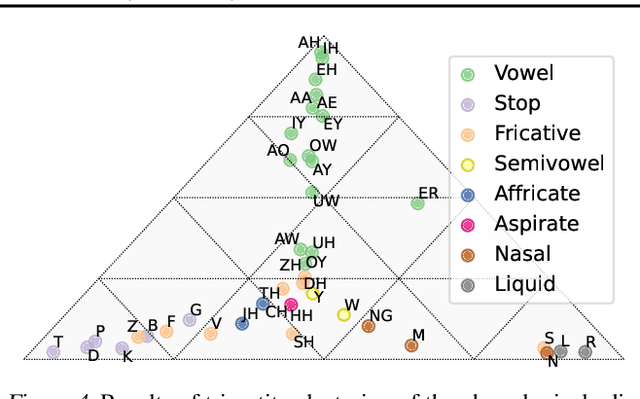
Algorithms for node clustering typically focus on finding homophilous structure in graphs. That is, they find sets of similar nodes with many edges within, rather than across, the clusters. However, graphs often also exhibit heterophilous structure, as exemplified by (nearly) bipartite and tripartite graphs, where most edges occur across the clusters. Grappling with such structure is typically left to the task of graph simplification. We present a probabilistic model based on non-negative matrix factorization which unifies clustering and simplification, and provides a framework for modeling arbitrary graph structure. Our model is based on factorizing the process of taking a random walk on the graph. It permits an unconstrained parametrization, allowing for optimization via simple gradient descent. By relaxing the hard clustering to a soft clustering, our algorithm relaxes potentially hard clustering problems to a tractable ones. We illustrate our algorithm's capabilities on a synthetic graph, as well as simple unsupervised learning tasks involving bipartite and tripartite clustering of orthographic and phonological data.
Direct Embedding of Temporal Network Edges via Time-Decayed Line Graphs
Sep 30, 2022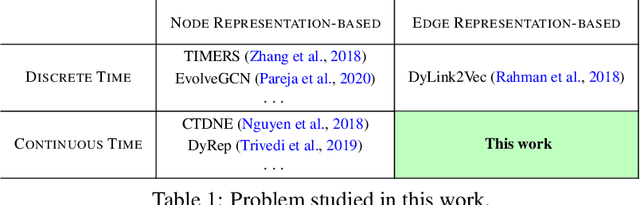
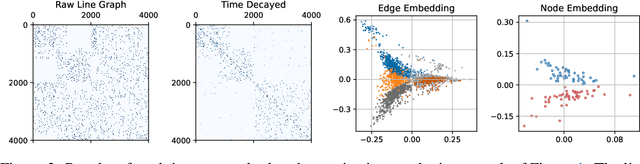
Temporal networks model a variety of important phenomena involving timed interactions between entities. Existing methods for machine learning on temporal networks generally exhibit at least one of two limitations. First, time is assumed to be discretized, so if the time data is continuous, the user must determine the discretization and discard precise time information. Second, edge representations can only be calculated indirectly from the nodes, which may be suboptimal for tasks like edge classification. We present a simple method that avoids both shortcomings: construct the line graph of the network, which includes a node for each interaction, and weigh the edges of this graph based on the difference in time between interactions. From this derived graph, edge representations for the original network can be computed with efficient classical methods. The simplicity of this approach facilitates explicit theoretical analysis: we can constructively show the effectiveness of our method's representations for a natural synthetic model of temporal networks. Empirical results on real-world networks demonstrate our method's efficacy and efficiency on both edge classification and temporal link prediction.
Simplified Graph Convolution with Heterophily
Feb 08, 2022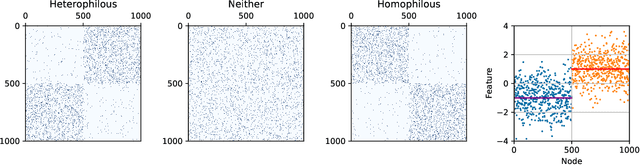
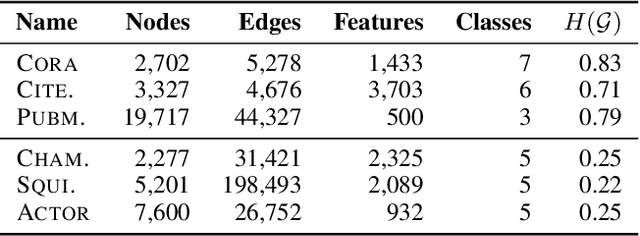
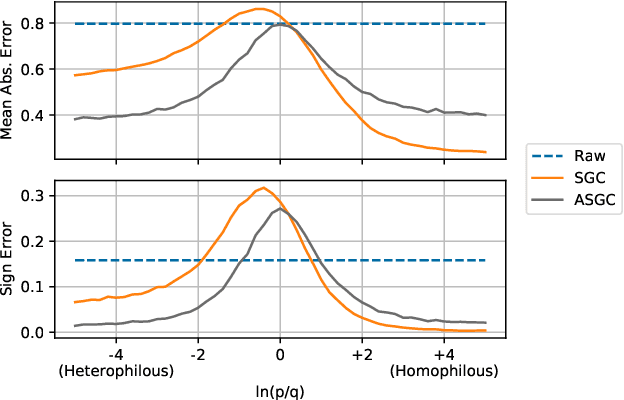
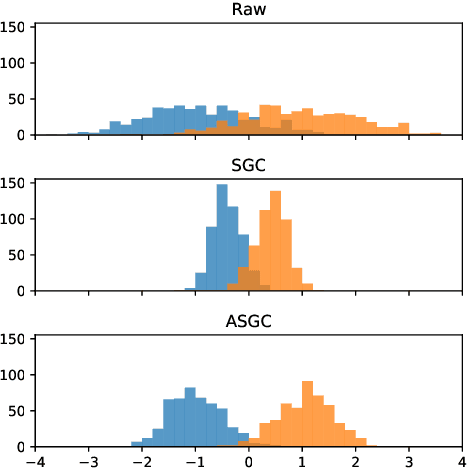
Graph convolutional networks (GCNs) (Kipf & Welling, 2017) attempt to extend the success of deep learning in modeling image and text data to graphs. However, like other deep models, GCNs comprise repeated nonlinear transformations of inputs and are therefore time and memory intensive to train. Recent work has shown that a much simpler and faster model, Simple Graph Convolution (SGC) (Wu et al., 2019), is competitive with GCNs in common graph machine learning benchmarks. The use of graph data in SGC implicitly assumes the common but not universal graph characteristic of homophily, wherein nodes link to nodes which are similar. Here we show that SGC is indeed ineffective for heterophilous (i.e., non-homophilous) graphs via experiments on synthetic and real-world datasets. We propose Adaptive Simple Graph Convolution (ASGC), which we show can adapt to both homophilous and heterophilous graph structure. Like SGC, ASGC is not a deep model, and hence is fast, scalable, and interpretable. We find that our non-deep method often outperforms state-of-the-art deep models at node classification on a benchmark of real-world datasets. The SGC paper questioned whether the complexity of graph neural networks is warranted for common graph problems involving homophilous networks; our results suggest that this question is still open even for more complicated problems involving heterophilous networks.
An Interpretable Graph Generative Model with Heterophily
Nov 04, 2021
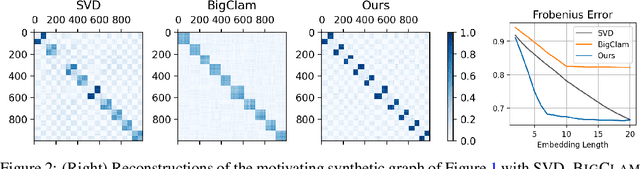
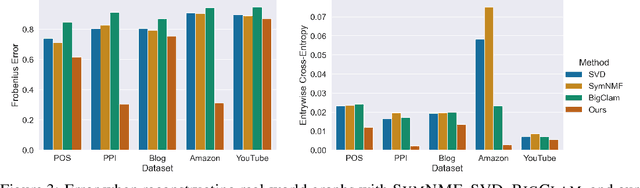
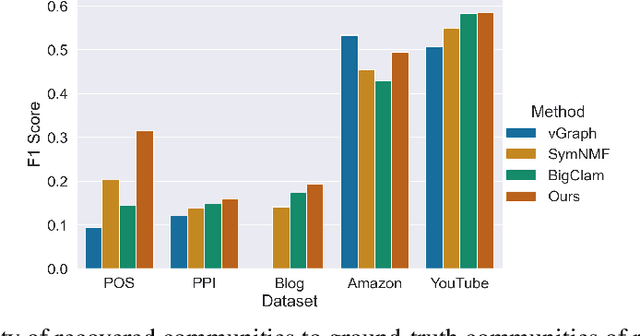
Many models for graphs fall under the framework of edge-independent dot product models. These models output the probabilities of edges existing between all pairs of nodes, and the probability of a link between two nodes increases with the dot product of vectors associated with the nodes. Recent work has shown that these models are unable to capture key structures in real-world graphs, particularly heterophilous structures, wherein links occur between dissimilar nodes. We propose the first edge-independent graph generative model that is a) expressive enough to capture heterophily, b) produces nonnegative embeddings, which allow link predictions to be interpreted in terms of communities, and c) optimizes effectively on real-world graphs with gradient descent on a cross-entropy loss. Our theoretical results demonstrate the expressiveness of our model in its ability to exactly reconstruct a graph using a number of clusters that is linear in the maximum degree, along with its ability to capture both heterophily and homophily in the data. Further, our experiments demonstrate the effectiveness of our model for a variety of important application tasks such as multi-label clustering and link prediction.
On the Power of Edge Independent Graph Models
Oct 29, 2021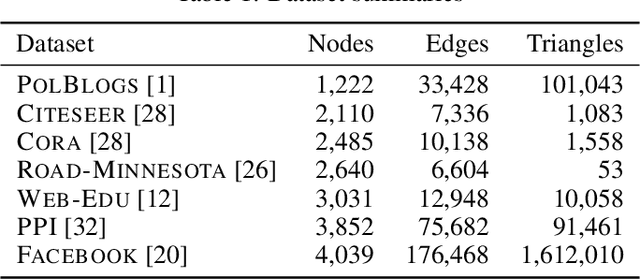
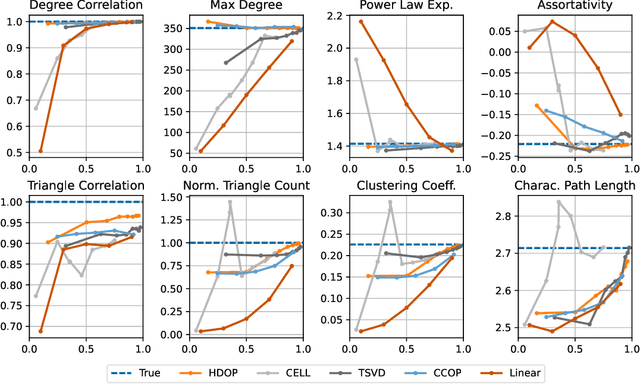
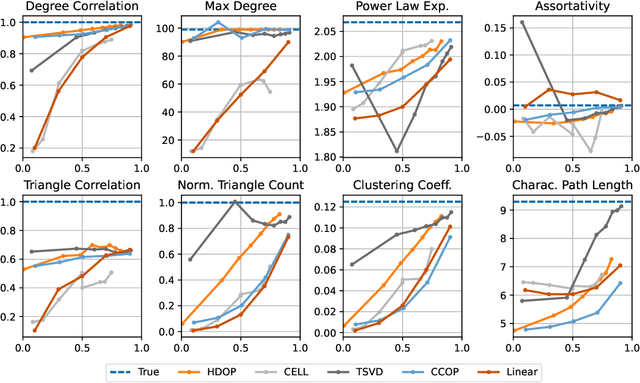
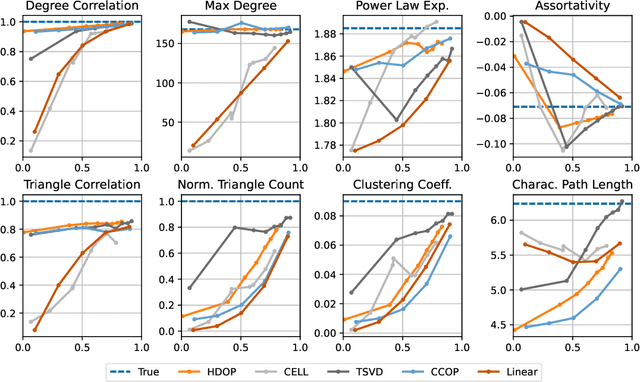
Why do many modern neural-network-based graph generative models fail to reproduce typical real-world network characteristics, such as high triangle density? In this work we study the limitations of edge independent random graph models, in which each edge is added to the graph independently with some probability. Such models include both the classic Erd\"{o}s-R\'{e}nyi and stochastic block models, as well as modern generative models such as NetGAN, variational graph autoencoders, and CELL. We prove that subject to a bounded overlap condition, which ensures that the model does not simply memorize a single graph, edge independent models are inherently limited in their ability to generate graphs with high triangle and other subgraph densities. Notably, such high densities are known to appear in real-world social networks and other graphs. We complement our negative results with a simple generative model that balances overlap and accuracy, performing comparably to more complex models in reconstructing many graph statistics.
DeepWalking Backwards: From Embeddings Back to Graphs
Feb 17, 2021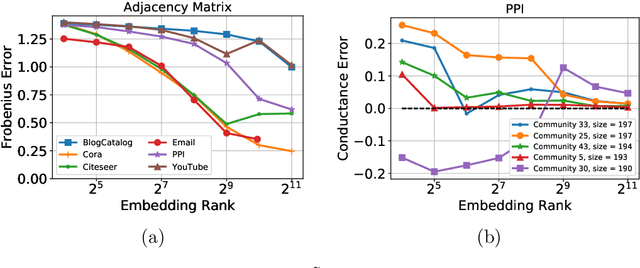
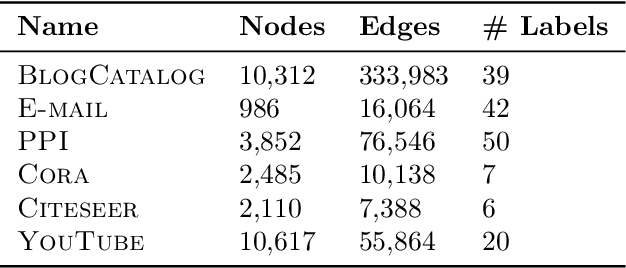
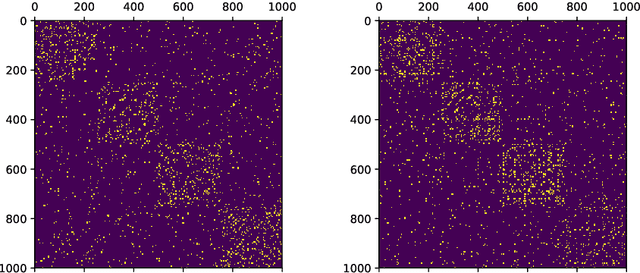
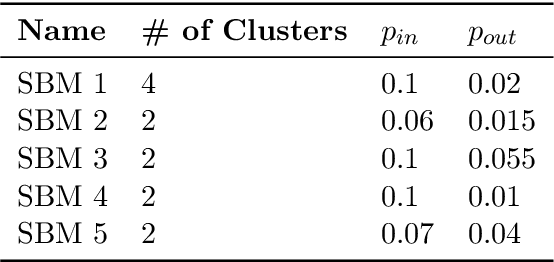
Low-dimensional node embeddings play a key role in analyzing graph datasets. However, little work studies exactly what information is encoded by popular embedding methods, and how this information correlates with performance in downstream machine learning tasks. We tackle this question by studying whether embeddings can be inverted to (approximately) recover the graph used to generate them. Focusing on a variant of the popular DeepWalk method (Perozzi et al., 2014; Qiu et al., 2018), we present algorithms for accurate embedding inversion - i.e., from the low-dimensional embedding of a graph G, we can find a graph H with a very similar embedding. We perform numerous experiments on real-world networks, observing that significant information about G, such as specific edges and bulk properties like triangle density, is often lost in H. However, community structure is often preserved or even enhanced. Our findings are a step towards a more rigorous understanding of exactly what information embeddings encode about the input graph, and why this information is useful for learning tasks.
Node Embeddings and Exact Low-Rank Representations of Complex Networks
Jun 10, 2020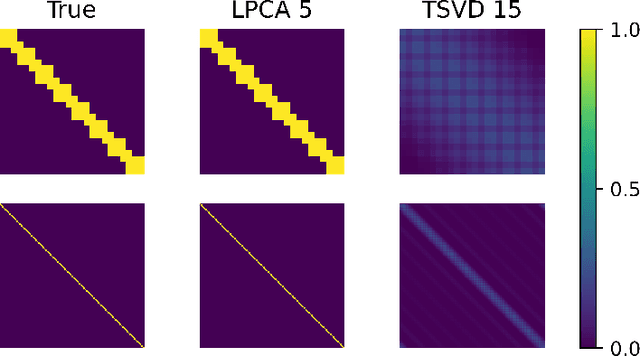
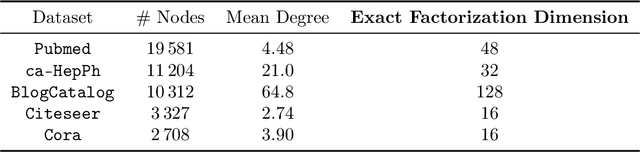
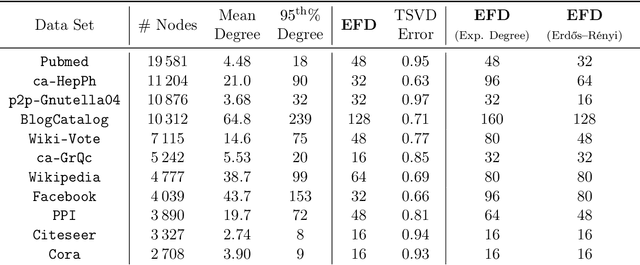
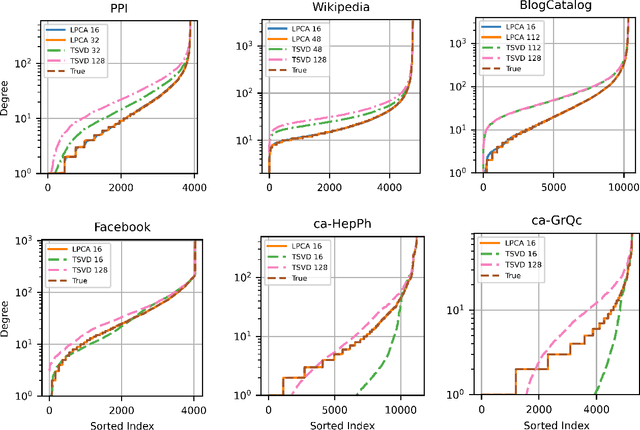
Low-dimensional embeddings, from classical spectral embeddings to modern neural-net-inspired methods, are a cornerstone in the modeling and analysis of complex networks. Recent work by Seshadhri et al. (PNAS 2020) suggests that such embeddings cannot capture local structure arising in complex networks. In particular, they show that any network generated from a natural low-dimensional model cannot be both sparse and have high triangle density (high clustering coefficient), two hallmark properties of many real-world networks. In this work we show that the results of Seshadhri et al. are intimately connected to the model they use rather than the low-dimensional structure of complex networks. Specifically, we prove that a minor relaxation of their model can generate sparse graphs with high triangle density. Surprisingly, we show that this same model leads to exact low-dimensional factorizations of many real-world networks. We give a simple algorithm based on logistic principal component analysis (LPCA) that succeeds in finding such exact embeddings. Finally, we perform a large number of experiments that verify the ability of very low-dimensional embeddings to capture local structure in real-world networks.
InfiniteWalk: Deep Network Embeddings as Laplacian Embeddings with a Nonlinearity
May 29, 2020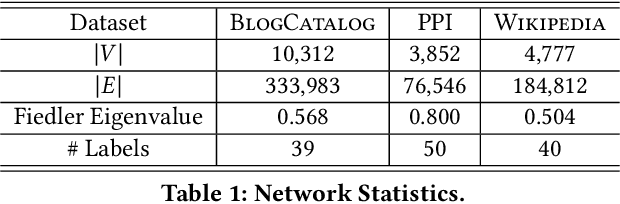
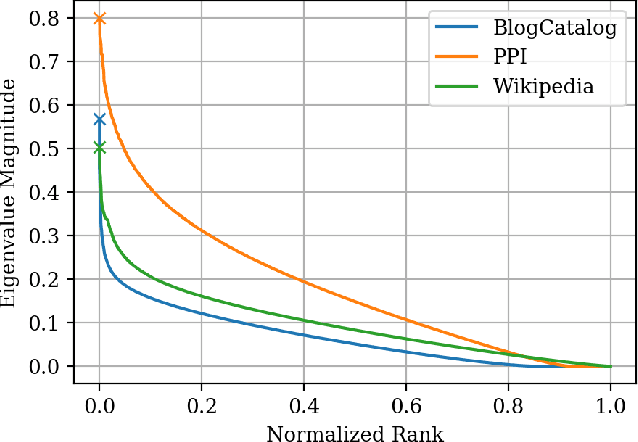

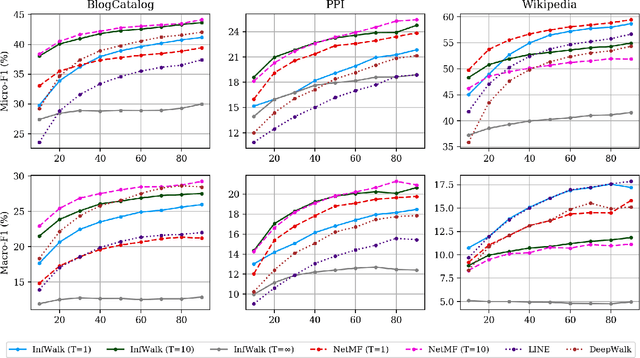
The skip-gram model for learning word embeddings (Mikolov et al. 2013) has been widely popular, and DeepWalk (Perozzi et al. 2014), among other methods, has extended the model to learning node representations from networks. Recent work of Qiu et al. (2018) provides a closed-form expression for the DeepWalk objective, obviating the need for sampling for small datasets and improving accuracy. In these methods, the "window size" T within which words or nodes are considered to co-occur is a key hyperparameter. We study the objective in the limit as T goes to infinity, which allows us to simplify the expression of Qiu et al. We prove that this limiting objective corresponds to factoring a simple transformation of the pseudoinverse of the graph Laplacian, linking DeepWalk to extensive prior work in spectral graph embeddings. Further, we show that by a applying a simple nonlinear entrywise transformation to this pseudoinverse, we recover a good approximation of the finite-T objective and embeddings that are competitive with those from DeepWalk and other skip-gram methods in multi-label classification. Surprisingly, we find that even simple binary thresholding of the Laplacian pseudoinverse is often competitive, suggesting that the core advancement of recent methods is a nonlinearity on top of the classical spectral embedding approach.