 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLatent Random Steps as Relaxations of Max-Cut, Min-Cut, and More
Paper and Code
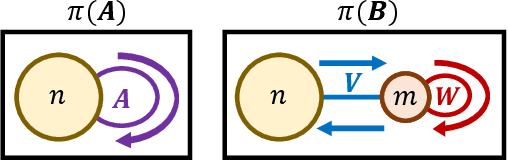
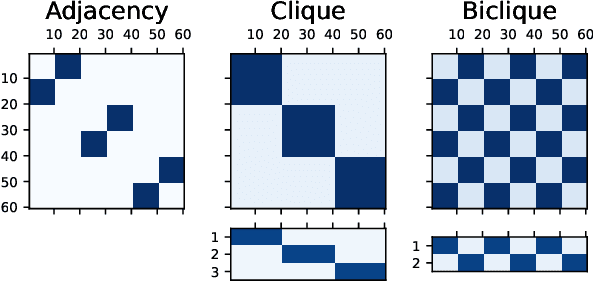
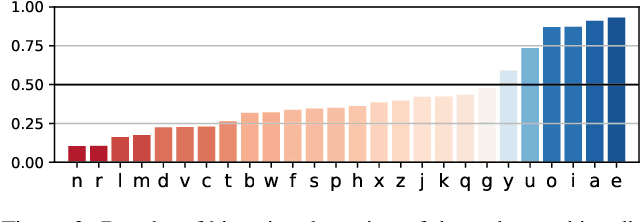
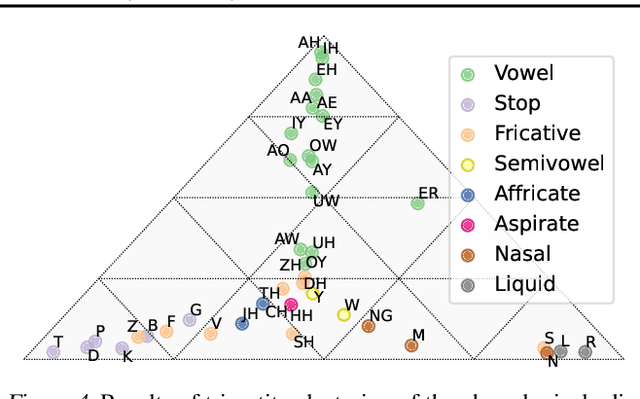
Algorithms for node clustering typically focus on finding homophilous structure in graphs. That is, they find sets of similar nodes with many edges within, rather than across, the clusters. However, graphs often also exhibit heterophilous structure, as exemplified by (nearly) bipartite and tripartite graphs, where most edges occur across the clusters. Grappling with such structure is typically left to the task of graph simplification. We present a probabilistic model based on non-negative matrix factorization which unifies clustering and simplification, and provides a framework for modeling arbitrary graph structure. Our model is based on factorizing the process of taking a random walk on the graph. It permits an unconstrained parametrization, allowing for optimization via simple gradient descent. By relaxing the hard clustering to a soft clustering, our algorithm relaxes potentially hard clustering problems to a tractable ones. We illustrate our algorithm's capabilities on a synthetic graph, as well as simple unsupervised learning tasks involving bipartite and tripartite clustering of orthographic and phonological data.