 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hypergraph Neural Network Framework for Learning Hyperedge-Dependent Node Embeddings
Dec 28, 2022In this work, we introduce a hypergraph representation learning framework called Hypergraph Neural Networks (HNN) that jointly learns hyperedge embeddings along with a set of hyperedge-dependent embeddings for each node in the hypergraph. HNN derives multiple embeddings per node in the hypergraph where each embedding for a node is dependent on a specific hyperedge of that node. Notably, HNN is accurate, data-efficient, flexible with many interchangeable components, and useful for a wide range of hypergraph learning tasks. We evaluate the effectiveness of the HNN framework for hyperedge prediction and hypergraph node classification. We find that HNN achieves an overall mean gain of 7.72% and 11.37% across all baseline models and graphs for hyperedge prediction and hypergraph node classification, respectively.
Graph Learning with Localized Neighborhood Fairness
Dec 22, 2022Learning fair graph representations for downstream applications is becoming increasingly important, but existing work has mostly focused on improving fairness at the global level by either modifying the graph structure or objective function without taking into account the local neighborhood of a node. In this work, we formally introduce the notion of neighborhood fairness and develop a computational framework for learning such locally fair embeddings. We argue that the notion of neighborhood fairness is more appropriate since GNN-based models operate at the local neighborhood level of a node. Our neighborhood fairness framework has two main components that are flexible for learning fair graph representations from arbitrary data: the first aims to construct fair neighborhoods for any arbitrary node in a graph and the second enables adaption of these fair neighborhoods to better capture certain application or data-dependent constraints, such as allowing neighborhoods to be more biased towards certain attributes or neighbors in the graph.Furthermore, while link prediction has been extensively studied, we are the first to investigate the graph representation learning task of fair link classification. We demonstrate the effectiveness of the proposed neighborhood fairness framework for a variety of graph machine learning tasks including fair link prediction, link classification, and learning fair graph embeddings. Notably, our approach achieves not only better fairness but also increases the accuracy in the majority of cases across a wide variety of graphs, problem settings, and metrics.
Direct Embedding of Temporal Network Edges via Time-Decayed Line Graphs
Sep 30, 2022
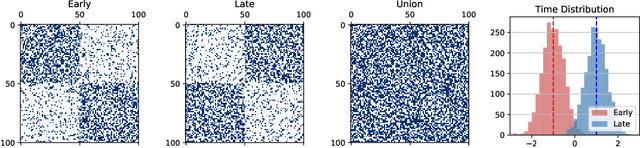
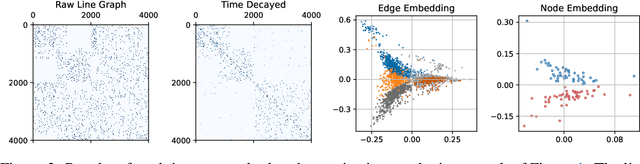
Temporal networks model a variety of important phenomena involving timed interactions between entities. Existing methods for machine learning on temporal networks generally exhibit at least one of two limitations. First, time is assumed to be discretized, so if the time data is continuous, the user must determine the discretization and discard precise time information. Second, edge representations can only be calculated indirectly from the nodes, which may be suboptimal for tasks like edge classification. We present a simple method that avoids both shortcomings: construct the line graph of the network, which includes a node for each interaction, and weigh the edges of this graph based on the difference in time between interactions. From this derived graph, edge representations for the original network can be computed with efficient classical methods. The simplicity of this approach facilitates explicit theoretical analysis: we can constructively show the effectiveness of our method's representations for a natural synthetic model of temporal networks. Empirical results on real-world networks demonstrate our method's efficacy and efficiency on both edge classification and temporal link prediction.
Insight-centric Visualization Recommendation
Mar 21, 2021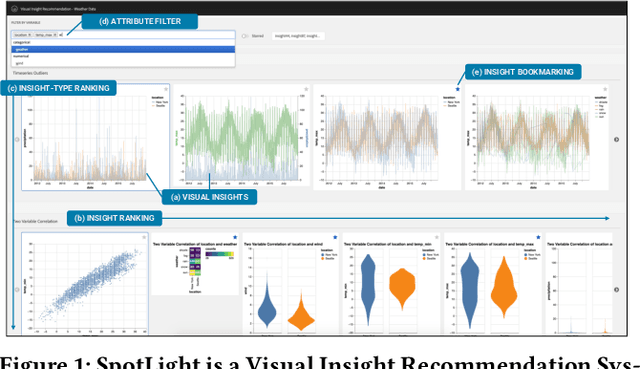
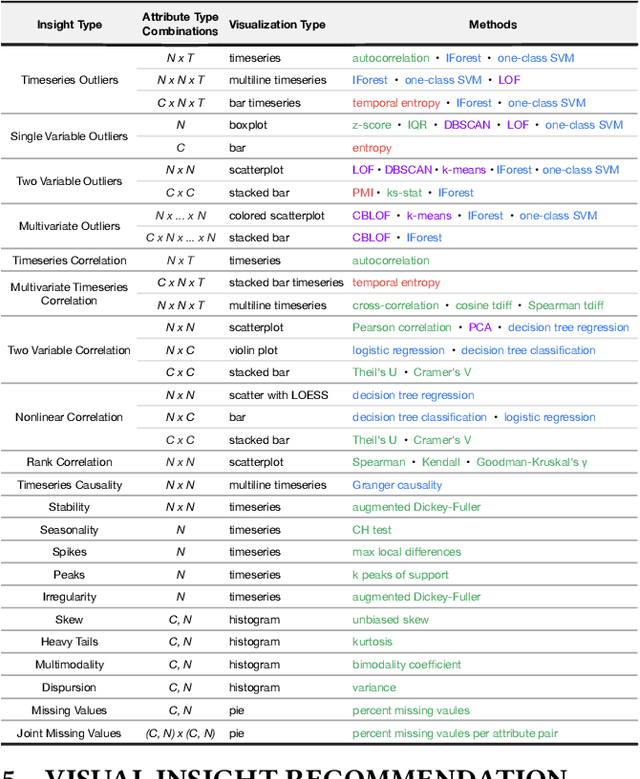
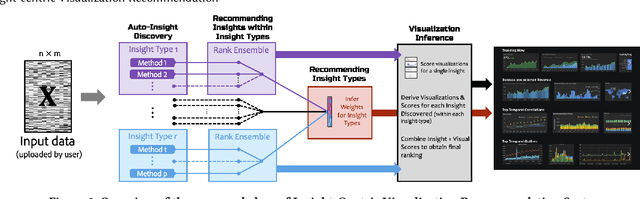
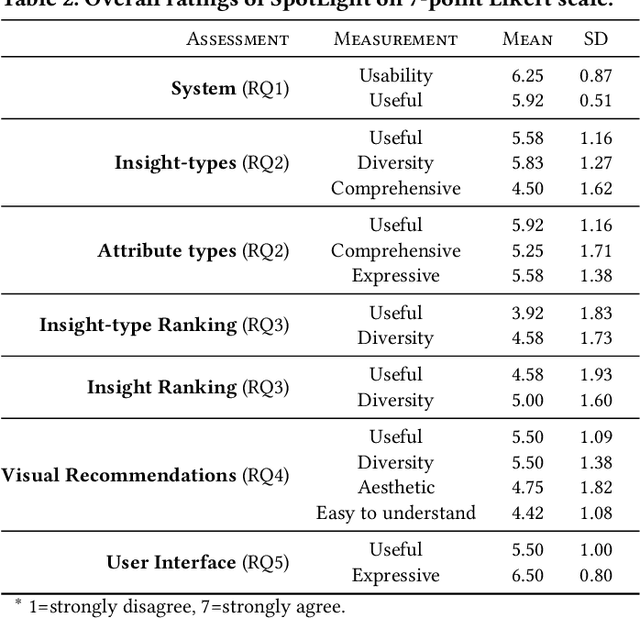
Visualization recommendation systems simplify exploratory data analysis (EDA) and make understanding data more accessible to users of all skill levels by automatically generating visualizations for users to explore. However, most existing visualization recommendation systems focus on ranking all visualizations into a single list or set of groups based on particular attributes or encodings. This global ranking makes it difficult and time-consuming for users to find the most interesting or relevant insights. To address these limitations, we introduce a novel class of visualization recommendation systems that automatically rank and recommend both groups of related insights as well as the most important insights within each group. Our proposed approach combines results from many different learning-based methods to discover insights automatically. A key advantage is that this approach generalizes to a wide variety of attribute types such as categorical, numerical, and temporal, as well as complex non-trivial combinations of these different attribute types. To evaluate the effectiveness of our approach, we implemented a new insight-centric visualization recommendation system, SpotLight, which generates and ranks annotated visualizations to explain each insight. We conducted a user study with 12 participants and two datasets which showed that users are able to quickly understand and find relevant insights in unfamiliar data.