 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff the Rails: Hijacking the Scoring Head in Generative End-to-End Driving Planners with Safety-Violating Adversarial Perturbations
Jun 29, 2026Generative models have recently seen rapid adoption in End-to-End (E2E) autonomous driving (AD), with diffusion-based denoising and vocabulary-based retrieval becoming the dominant trajectory-decoding paradigms. Despite their architectural diversity, current generative AD planners share a common inference pattern: a fixed set of candidate trajectories (anchors, vocabulary entries, or proposal queries) is scored by one or more learned heads conditioned on the Bird's-Eye-View (BEV) features, and the highest-scored candidate is returned as the final trajectory. Under this design, the scoring head is the only barrier between perception and the motion command, and its decision margins between competing candidates are often small. We introduce \textsc{Derail}, an adversarial framework that exploits this scoring-head attack surface. Evaluated on various generative planners, \textsc{Derail} flips the trajectory selection from a safe to an unsafe candidate, with score drops of $39$--$80\%$ and collision rates of up to $50\%$, consistently outperforming generic loss-maximization and feature-divergence attacks. Our analysis suggests that safety-violating objectives govern attack effectiveness against generative AD planners, and that the scoring-head inference pattern itself is a recurring attack surface worth explicit defensive consideration.
Out of Sight, Out of Track: Adversarial Attacks on Propagation-based Multi-Object Trackers via Query State Manipulation
Apr 01, 2026Recent Tracking-by-Query-Propagation (TBP) methods have advanced Multi-Object Tracking (MOT) by enabling end-to-end (E2E) pipelines with long-range temporal modeling. However, this reliance on query propagation introduces unexplored architectural vulnerabilities to adversarial attacks. We present FADE, a novel attack framework designed to exploit these specific vulnerabilities. FADE employs two attack strategies targeting core TBP mechanisms: (i) Temporal Query Flooding: Generates spurious temporally consistent track queries to exhaust the tracker's limited query budget, forcing it to terminate valid tracks. (ii) Temporal Memory Corruption: Directly attacks the query updater's memory by severing temporal links via state de-correlation and erasing the learned feature identity of matched tracks. Furthermore, we introduce a differentiable pipeline to optimize these attacks for physical-world realizability by leveraging simulations of advanced perception sensor spoofing. Experiments on MOT17 and MOT20 benchmarks demonstrate that FADE is highly effective against state-of-the-art TBP trackers, causing significant identity switches and track terminations.
Model for Peanuts: Hijacking ML Models without Training Access is Possible
Jun 03, 2024



The massive deployment of Machine Learning (ML) models has been accompanied by the emergence of several attacks that threaten their trustworthiness and raise ethical and societal concerns such as invasion of privacy, discrimination risks, and lack of accountability. Model hijacking is one of these attacks, where the adversary aims to hijack a victim model to execute a different task than its original one. Model hijacking can cause accountability and security risks since a hijacked model owner can be framed for having their model offering illegal or unethical services. Prior state-of-the-art works consider model hijacking as a training time attack, whereby an adversary requires access to the ML model training to execute their attack. In this paper, we consider a stronger threat model where the attacker has no access to the training phase of the victim model. Our intuition is that ML models, typically over-parameterized, might (unintentionally) learn more than the intended task for they are trained. We propose a simple approach for model hijacking at inference time named SnatchML to classify unknown input samples using distance measures in the latent space of the victim model to previously known samples associated with the hijacking task classes. SnatchML empirically shows that benign pre-trained models can execute tasks that are semantically related to the initial task. Surprisingly, this can be true even for hijacking tasks unrelated to the original task. We also explore different methods to mitigate this risk. We first propose a novel approach we call meta-unlearning, designed to help the model unlearn a potentially malicious task while training on the original task dataset. We also provide insights on over-parameterization as one possible inherent factor that makes model hijacking easier, and we accordingly propose a compression-based countermeasure against this attack.
SONATA: Self-adaptive Evolutionary Framework for Hardware-aware Neural Architecture Search
Feb 20, 2024



Recent advancements in Artificial Intelligence (AI), driven by Neural Networks (NN), demand innovative neural architecture designs, particularly within the constrained environments of Internet of Things (IoT) systems, to balance performance and efficiency. HW-aware Neural Architecture Search (HW-aware NAS) emerges as an attractive strategy to automate the design of NN using multi-objective optimization approaches, such as evolutionary algorithms. However, the intricate relationship between NN design parameters and HW-aware NAS optimization objectives remains an underexplored research area, overlooking opportunities to effectively leverage this knowledge to guide the search process accordingly. Furthermore, the large amount of evaluation data produced during the search holds untapped potential for refining the optimization strategy and improving the approximation of the Pareto front. Addressing these issues, we propose SONATA, a self-adaptive evolutionary algorithm for HW-aware NAS. Our method leverages adaptive evolutionary operators guided by the learned importance of NN design parameters. Specifically, through tree-based surrogate models and a Reinforcement Learning agent, we aspire to gather knowledge on 'How' and 'When' to evolve NN architectures. Comprehensive evaluations across various NAS search spaces and hardware devices on the ImageNet-1k dataset have shown the merit of SONATA with up to 0.25% improvement in accuracy and up to 2.42x gains in latency and energy. Our SONATA has seen up to sim$93.6% Pareto dominance over the native NSGA-II, further stipulating the importance of self-adaptive evolution operators in HW-aware NAS.
Harmonic-NAS: Hardware-Aware Multimodal Neural Architecture Search on Resource-constrained Devices
Sep 28, 2023
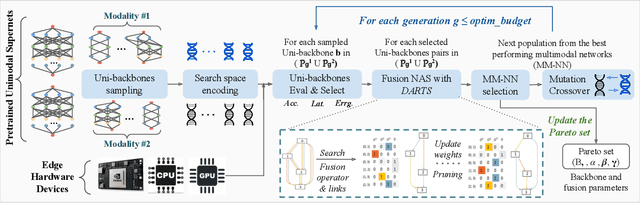
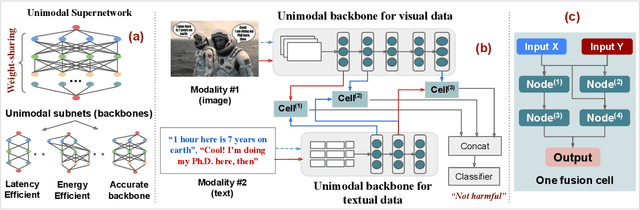

The recent surge of interest surrounding Multimodal Neural Networks (MM-NN) is attributed to their ability to effectively process and integrate multiscale information from diverse data sources. MM-NNs extract and fuse features from multiple modalities using adequate unimodal backbones and specific fusion networks. Although this helps strengthen the multimodal information representation, designing such networks is labor-intensive. It requires tuning the architectural parameters of the unimodal backbones, choosing the fusing point, and selecting the operations for fusion. Furthermore, multimodality AI is emerging as a cutting-edge option in Internet of Things (IoT) systems where inference latency and energy consumption are critical metrics in addition to accuracy. In this paper, we propose Harmonic-NAS, a framework for the joint optimization of unimodal backbones and multimodal fusion networks with hardware awareness on resource-constrained devices. Harmonic-NAS involves a two-tier optimization approach for the unimodal backbone architectures and fusion strategy and operators. By incorporating the hardware dimension into the optimization, evaluation results on various devices and multimodal datasets have demonstrated the superiority of Harmonic-NAS over state-of-the-art approaches achieving up to 10.9% accuracy improvement, 1.91x latency reduction, and 2.14x energy efficiency gain.
MaGNAS: A Mapping-Aware Graph Neural Architecture Search Framework for Heterogeneous MPSoC Deployment
Jul 16, 2023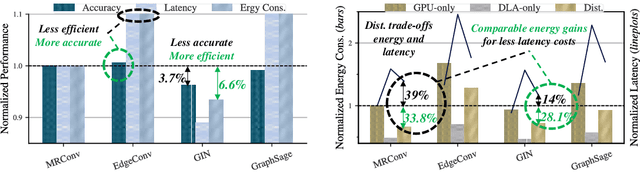
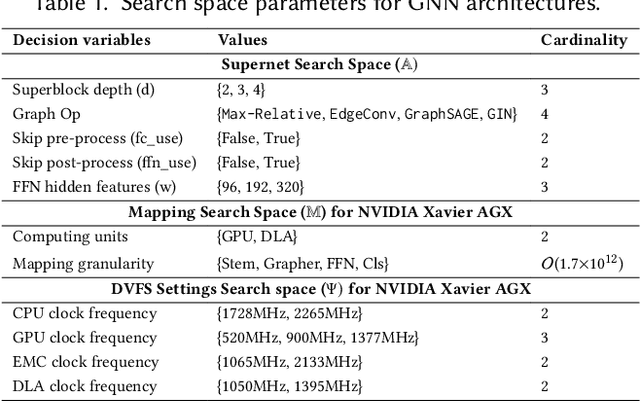
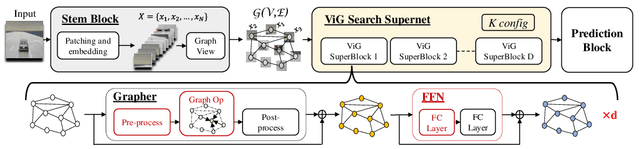
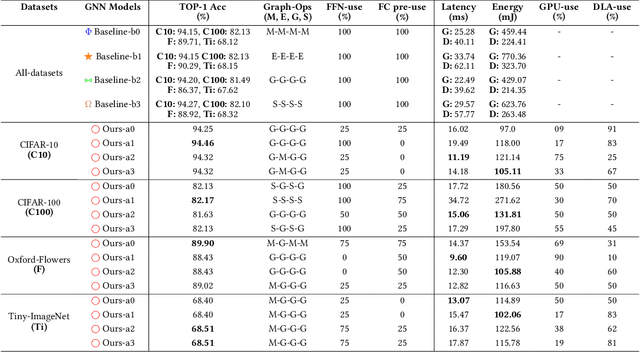
Graph Neural Networks (GNNs) are becoming increasingly popular for vision-based applications due to their intrinsic capacity in modeling structural and contextual relations between various parts of an image frame. On another front, the rising popularity of deep vision-based applications at the edge has been facilitated by the recent advancements in heterogeneous multi-processor Systems on Chips (MPSoCs) that enable inference under real-time, stringent execution requirements. By extension, GNNs employed for vision-based applications must adhere to the same execution requirements. Yet contrary to typical deep neural networks, the irregular flow of graph learning operations poses a challenge to running GNNs on such heterogeneous MPSoC platforms. In this paper, we propose a novel unified design-mapping approach for efficient processing of vision GNN workloads on heterogeneous MPSoC platforms. Particularly, we develop MaGNAS, a mapping-aware Graph Neural Architecture Search framework. MaGNAS proposes a GNN architectural design space coupled with prospective mapping options on a heterogeneous SoC to identify model architectures that maximize on-device resource efficiency. To achieve this, MaGNAS employs a two-tier evolutionary search to identify optimal GNNs and mapping pairings that yield the best performance trade-offs. Through designing a supernet derived from the recent Vision GNN (ViG) architecture, we conducted experiments on four (04) state-of-the-art vision datasets using both (i) a real hardware SoC platform (NVIDIA Xavier AGX) and (ii) a performance/cost model simulator for DNN accelerators. Our experimental results demonstrate that MaGNAS is able to provide 1.57x latency speedup and is 3.38x more energy-efficient for several vision datasets executed on the Xavier MPSoC vs. the GPU-only deployment while sustaining an average 0.11% accuracy reduction from the baseline.
Treasure What You Have: Exploiting Similarity in Deep Neural Networks for Efficient Video Processing
May 10, 2023



Deep learning has enabled various Internet of Things (IoT) applications. Still, designing models with high accuracy and computational efficiency remains a significant challenge, especially in real-time video processing applications. Such applications exhibit high inter- and intra-frame redundancy, allowing further improvement. This paper proposes a similarity-aware training methodology that exploits data redundancy in video frames for efficient processing. Our approach introduces a per-layer regularization that enhances computation reuse by increasing the similarity of weights during training. We validate our methodology on two critical real-time applications, lane detection and scene parsing. We observe an average compression ratio of approximately 50% and a speedup of \sim 1.5x for different models while maintaining the same accuracy.
Map-and-Conquer: Energy-Efficient Mapping of Dynamic Neural Nets onto Heterogeneous MPSoCs
Feb 24, 2023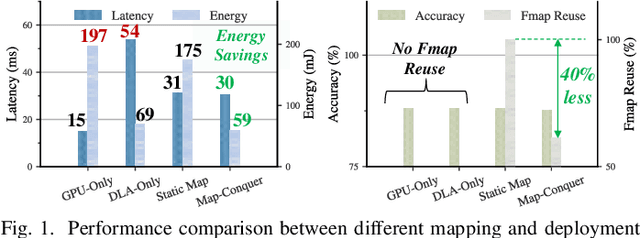
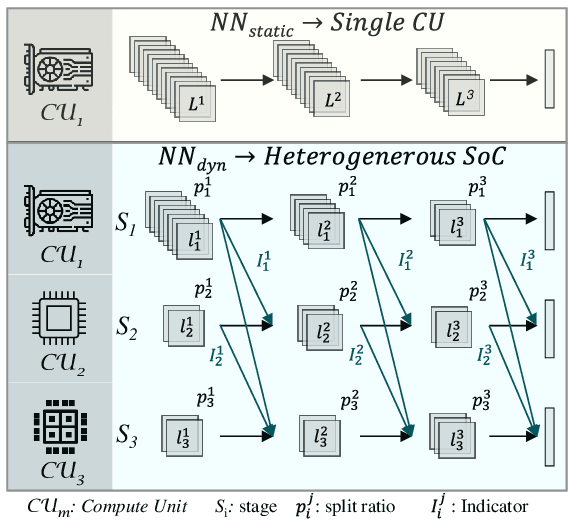

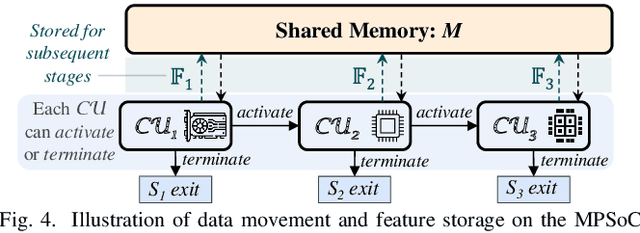
Heterogeneous MPSoCs comprise diverse processing units of varying compute capabilities. To date, the mapping strategies of neural networks (NNs) onto such systems are yet to exploit the full potential of processing parallelism, made possible through both the intrinsic NNs' structure and underlying hardware composition. In this paper, we propose a novel framework to effectively map NNs onto heterogeneous MPSoCs in a manner that enables them to leverage the underlying processing concurrency. Specifically, our approach identifies an optimal partitioning scheme of the NN along its `width' dimension, which facilitates deployment of concurrent NN blocks onto different hardware computing units. Additionally, our approach contributes a novel scheme to deploy partitioned NNs onto the MPSoC as dynamic multi-exit networks for additional performance gains. Our experiments on a standard MPSoC platform have yielded dynamic mapping configurations that are 2.1x more energy-efficient than the GPU-only mapping while incurring 1.7x less latency than DLA-only mapping.
HADAS: Hardware-Aware Dynamic Neural Architecture Search for Edge Performance Scaling
Dec 06, 2022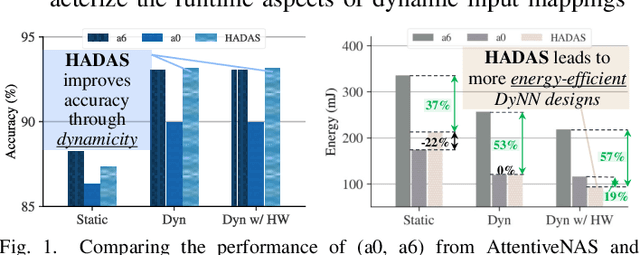
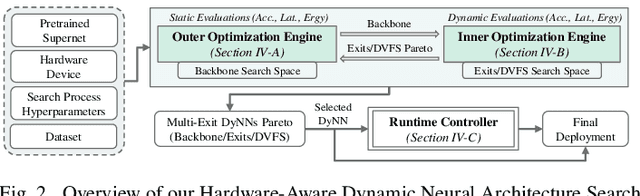
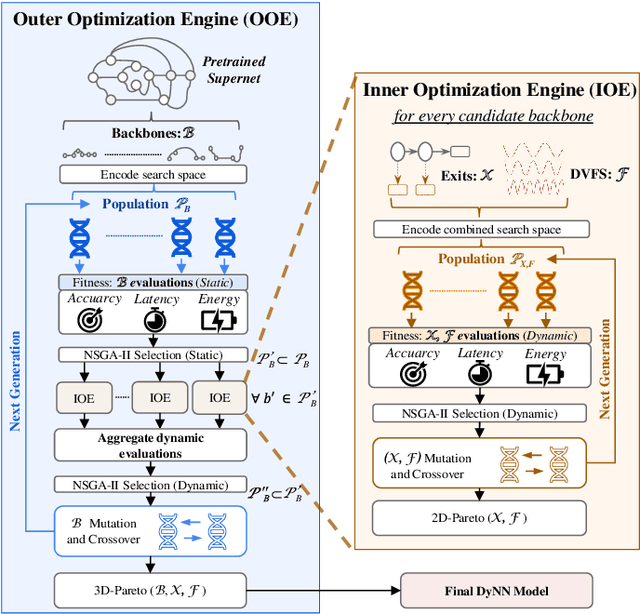
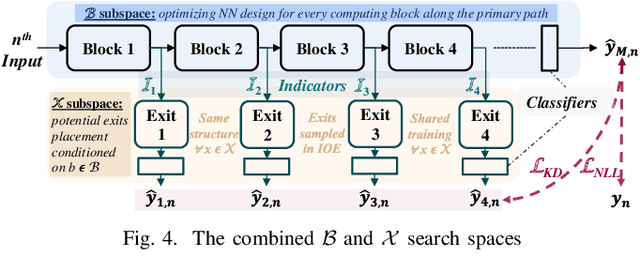
Dynamic neural networks (DyNNs) have become viable techniques to enable intelligence on resource-constrained edge devices while maintaining computational efficiency. In many cases, the implementation of DyNNs can be sub-optimal due to its underlying backbone architecture being developed at the design stage independent of both: (i) the dynamic computing features, e.g. early exiting, and (ii) the resource efficiency features of the underlying hardware, e.g., dynamic voltage and frequency scaling (DVFS). Addressing this, we present HADAS, a novel Hardware-Aware Dynamic Neural Architecture Search framework that realizes DyNN architectures whose backbone, early exiting features, and DVFS settings have been jointly optimized to maximize performance and resource efficiency. Our experiments using the CIFAR-100 dataset and a diverse set of edge computing platforms have seen HADAS dynamic models achieve up to 57% energy efficiency gains compared to the conventional dynamic ones while maintaining the desired level of accuracy scores. Our code is available at https://github.com/HalimaBouzidi/HADAS
Performance Prediction for Convolutional Neural Networks in Edge Devices
Oct 21, 2020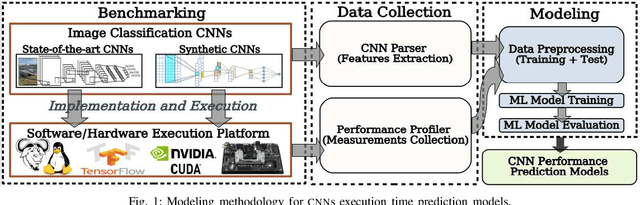
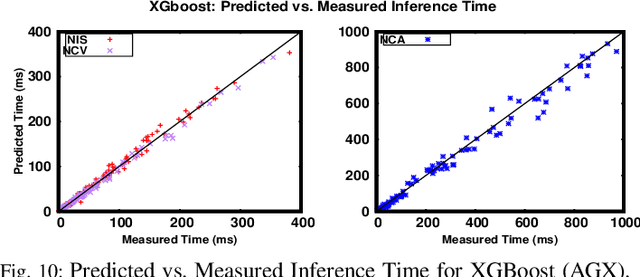
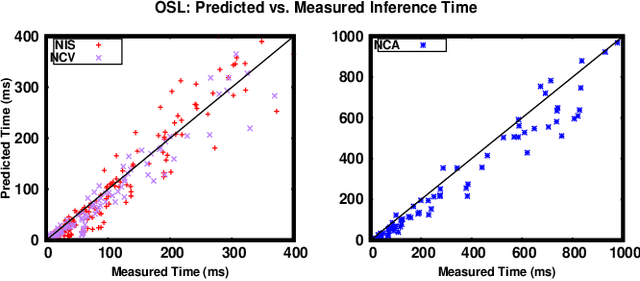
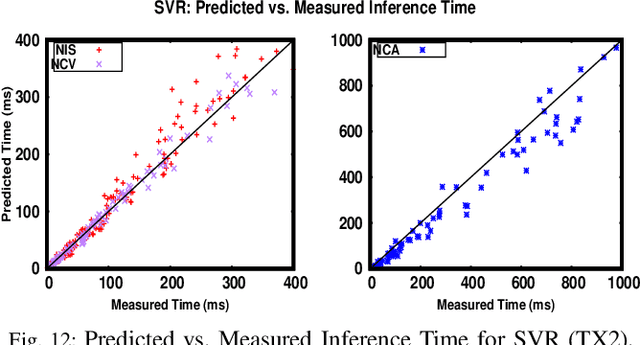
Running Convolutional Neural Network (CNN) based applications on edge devices near the source of data can meet the latency and privacy challenges. However due to their reduced computing resources and their energy constraints, these edge devices can hardly satisfy CNN needs in processing and data storage. For these platforms, choosing the CNN with the best trade-off between accuracy and execution time while respecting Hardware constraints is crucial. In this paper, we present and compare five (5) of the widely used Machine Learning based methods for execution time prediction of CNNs on two (2) edge GPU platforms. For these 5 methods, we also explore the time needed for their training and tuning their corresponding hyperparameters. Finally, we compare times to run the prediction models on different platforms. The utilization of these methods will highly facilitate design space exploration by providing quickly the best CNN on a target edge GPU. Experimental results show that eXtreme Gradient Boosting (XGBoost) provides a less than 14.73% average prediction error even for unexplored and unseen CNN models' architectures. Random Forest (RF) depicts comparable accuracy but needs more effort and time to be trained. The other 3 approaches (OLS, MLP and SVR) are less accurate for CNN performances estimation.