 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiking-Fer: Spiking Neural Network for Facial Expression Recognition With Event Cameras
Apr 20, 2023Facial Expression Recognition (FER) is an active research domain that has shown great progress recently, notably thanks to the use of large deep learning models. However, such approaches are particularly energy intensive, which makes their deployment difficult for edge devices. To address this issue, Spiking Neural Networks (SNNs) coupled with event cameras are a promising alternative, capable of processing sparse and asynchronous events with lower energy consumption. In this paper, we establish the first use of event cameras for FER, named "Event-based FER", and propose the first related benchmarks by converting popular video FER datasets to event streams. To deal with this new task, we propose "Spiking-FER", a deep convolutional SNN model, and compare it against a similar Artificial Neural Network (ANN). Experiments show that the proposed approach achieves comparable performance to the ANN architecture, while consuming less energy by orders of magnitude (up to 65.39x). In addition, an experimental study of various event-based data augmentation techniques is performed to provide insights into the efficient transformations specific to event-based FER.
Spiking Neural Networks for Frame-based and Event-based Single Object Localization
Jun 13, 2022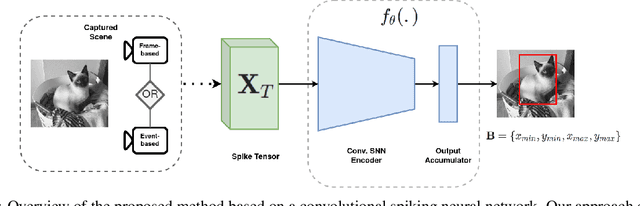

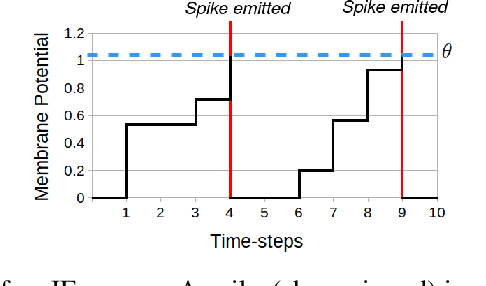

Spiking neural networks have shown much promise as an energy-efficient alternative to artificial neural networks. However, understanding the impacts of sensor noises and input encodings on the network activity and performance remains difficult with common neuromorphic vision baselines like classification. Therefore, we propose a spiking neural network approach for single object localization trained using surrogate gradient descent, for frame- and event-based sensors. We compare our method with similar artificial neural networks and show that our model has competitive/better performance in accuracy, robustness against various corruptions, and has lower energy consumption. Moreover, we study the impact of neural coding schemes for static images in accuracy, robustness, and energy efficiency. Our observations differ importantly from previous studies on bio-plausible learning rules, which helps in the design of surrogate gradient trained architectures, and offers insight to design priorities in future neuromorphic technologies in terms of noise characteristics and data encoding methods.
Bina-Rep Event Frames: a Simple and Effective Representation for Event-based cameras
Feb 28, 2022


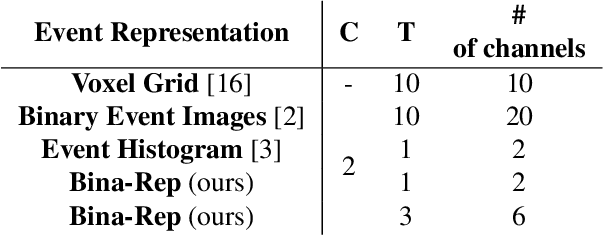
This paper presents "Bina-Rep", a simple representation method that converts asynchronous streams of events from event cameras to a sequence of sparse and expressive event frames. By representing multiple binary event images as a single frame of $N$-bit numbers, our method is able to obtain sparser and more expressive event frames thanks to the retained information about event orders in the original stream. Coupled with our proposed model based on a convolutional neural network, the reported results achieve state-of-the-art performance and repeatedly outperforms other common event representation methods. Our approach also shows competitive robustness against common image corruptions, compared to other representation techniques.
Review on Indoor RGB-D Semantic Segmentation with Deep Convolutional Neural Networks
May 25, 2021
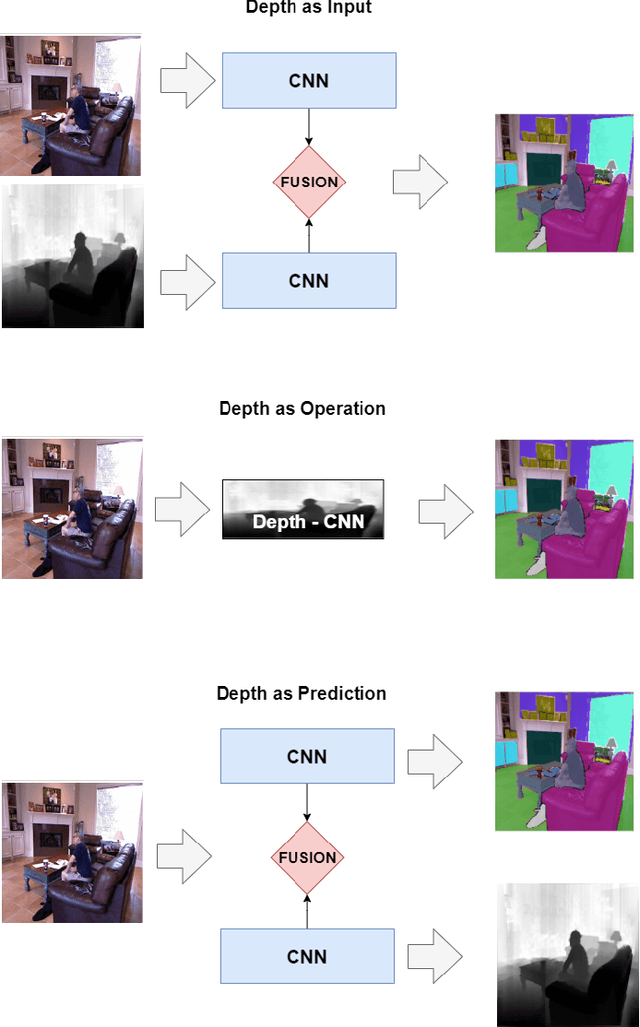
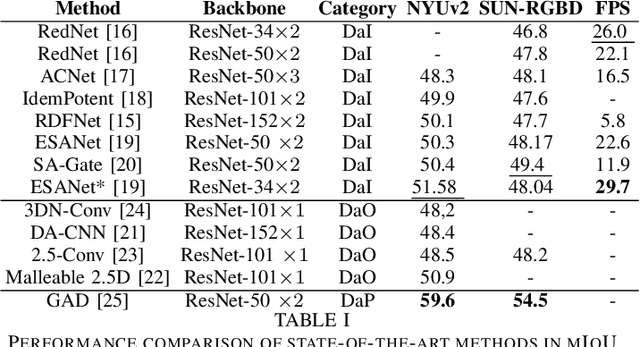
Many research works focus on leveraging the complementary geometric information of indoor depth sensors in vision tasks performed by deep convolutional neural networks, notably semantic segmentation. These works deal with a specific vision task known as "RGB-D Indoor Semantic Segmentation". The challenges and resulting solutions of this task differ from its standard RGB counterpart. This results in a new active research topic. The objective of this paper is to introduce the field of Deep Convolutional Neural Networks for RGB-D Indoor Semantic Segmentation. This review presents the most popular public datasets, proposes a categorization of the strategies employed by recent contributions, evaluates the performance of the current state-of-the-art, and discusses the remaining challenges and promising directions for future works.
Deep Spiking Convolutional Neural Network for Single Object Localization Based On Deep Continuous Local Learning
May 12, 2021
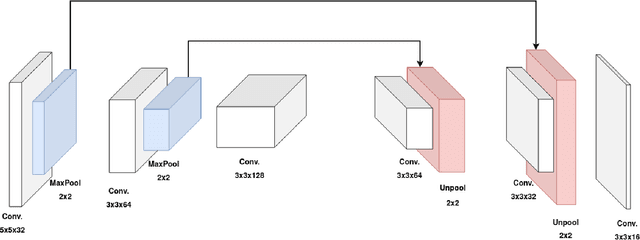

With the advent of neuromorphic hardware, spiking neural networks can be a good energy-efficient alternative to artificial neural networks. However, the use of spiking neural networks to perform computer vision tasks remains limited, mainly focusing on simple tasks such as digit recognition. It remains hard to deal with more complex tasks (e.g. segmentation, object detection) due to the small number of works on deep spiking neural networks for these tasks. The objective of this paper is to make the first step towards modern computer vision with supervised spiking neural networks. We propose a deep convolutional spiking neural network for the localization of a single object in a grayscale image. We propose a network based on DECOLLE, a spiking model that enables local surrogate gradient-based learning. The encouraging results reported on Oxford-IIIT-Pet validates the exploitation of spiking neural networks with a supervised learning approach for more elaborate vision tasks in the future.