 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformers with Selective Access to Early Representations
May 05, 2026Several recent Transformer architectures expose later layers to representations computed in the earliest layers, motivated by the observation that low-level features can become harder to recover as the residual stream is repeatedly transformed through depth. The cheapest among these methods add static value residuals: learned mixing coefficients that expose the first-layer value projection V_1 uniformly across tokens and heads. More expressive dense or dynamic alternatives recover finer-grained access, but at higher memory cost and lower throughput. The usefulness of V_1 is unlikely to be constant across tokens, heads, and contexts; different positions plausibly require different amounts of access to early lexical or semantic information. We therefore treat early-representation reuse as a retrieval problem rather than a connectivity problem, and introduce Selective Access Transformer (SATFormer), which preserves the first-layer value pathway while controlling access with a context-dependent gate. Across models from 130M to 1.3B parameters, SATFormer consistently improves validation loss and zero-shot accuracy over the static value-residual and Transformer baselines. Its strongest gains appear on retrieval-intensive benchmarks, where it improves over static value residuals by approximately 1.5 average points, while maintaining throughput and memory usage close to the baseline Transformer. Gate analyses suggest sparse, depth-dependent, head-specific, and category-sensitive access patterns, supporting the interpretation that SATFormer learns selective reuse of early representations rather than uniform residual copying. Our code is available at https://github.com/SkyeGunasekaran/SATFormer.
Direct Semantic Communication Between Large Language Models via Vector Translation
Nov 06, 2025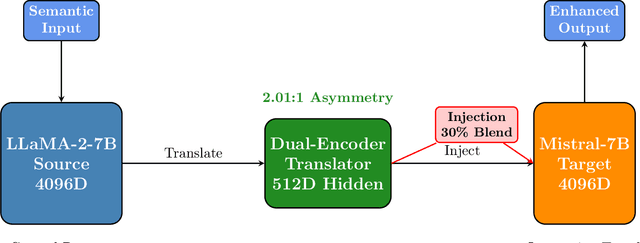
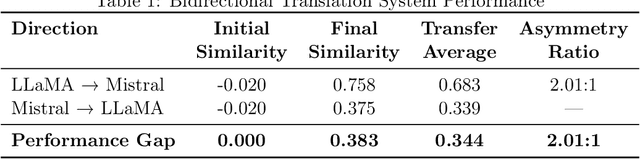
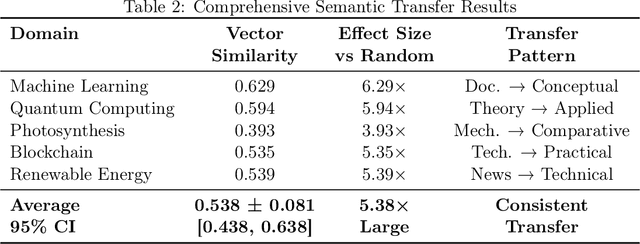
In multi-agent settings, such as debate, reflection, or tool-calling, large language models (LLMs) pass messages as plain tokens, discarding most latent semantics. This constrains information transfer and adds unnecessary computational overhead. We form a latent bridge via vector translations, which use learned mappings that enable direct semantic exchange between representation spaces. A dual-encoder translator trained between Llama-2-7B and Mistral-7B-Instruct attains an average cosine alignment of 0.538. Injecting the translated vectors at 30 percent blending strength steers the target model's generation without destabilizing logits. Bidirectional evaluation shows a 2.01:1 transfer asymmetry, indicating that general-purpose models yield more transferable representations than instruction-tuned variants. This conservative injection preserves computational stability while demonstrating that cross-model latent communication is feasible, enabling collaborative AI systems that share meaning rather than tokens.
Scaling Latent Reasoning via Looped Language Models
Oct 29, 2025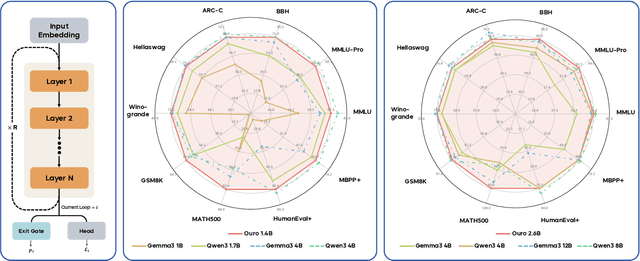
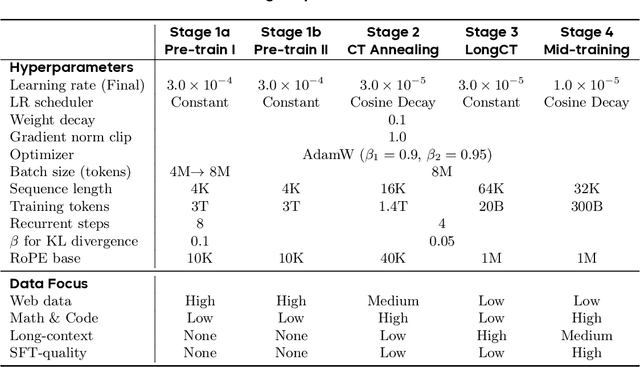
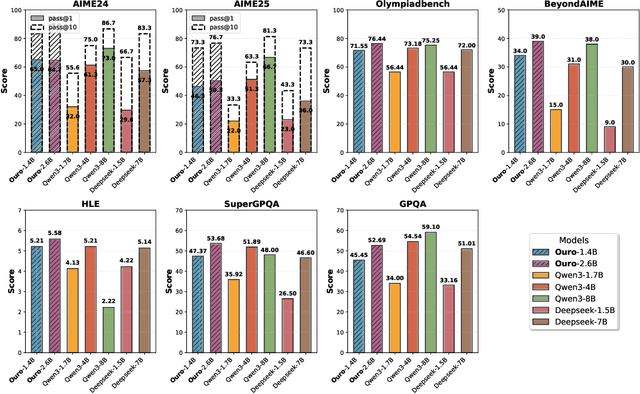

Modern LLMs are trained to "think" primarily via explicit text generation, such as chain-of-thought (CoT), which defers reasoning to post-training and under-leverages pre-training data. We present and open-source Ouro, named after the recursive Ouroboros, a family of pre-trained Looped Language Models (LoopLM) that instead build reasoning into the pre-training phase through (i) iterative computation in latent space, (ii) an entropy-regularized objective for learned depth allocation, and (iii) scaling to 7.7T tokens. Ouro 1.4B and 2.6B models enjoy superior performance that match the results of up to 12B SOTA LLMs across a wide range of benchmarks. Through controlled experiments, we show this advantage stems not from increased knowledge capacity, but from superior knowledge manipulation capabilities. We also show that LoopLM yields reasoning traces more aligned with final outputs than explicit CoT. We hope our results show the potential of LoopLM as a novel scaling direction in the reasoning era. Our model could be found in: http://ouro-llm.github.io.
A Systematic Analysis of Hybrid Linear Attention
Jul 08, 2025Transformers face quadratic complexity and memory issues with long sequences, prompting the adoption of linear attention mechanisms using fixed-size hidden states. However, linear models often suffer from limited recall performance, leading to hybrid architectures that combine linear and full attention layers. Despite extensive hybrid architecture research, the choice of linear attention component has not been deeply explored. We systematically evaluate various linear attention models across generations - vector recurrences to advanced gating mechanisms - both standalone and hybridized. To enable this comprehensive analysis, we trained and open-sourced 72 models: 36 at 340M parameters (20B tokens) and 36 at 1.3B parameters (100B tokens), covering six linear attention variants across five hybridization ratios. Benchmarking on standard language modeling and recall tasks reveals that superior standalone linear models do not necessarily excel in hybrids. While language modeling remains stable across linear-to-full attention ratios, recall significantly improves with increased full attention layers, particularly below a 3:1 ratio. Our study highlights selective gating, hierarchical recurrence, and controlled forgetting as critical for effective hybrid models. We recommend architectures such as HGRN-2 or GatedDeltaNet with a linear-to-full ratio between 3:1 and 6:1 to achieve Transformer-level recall efficiently. Our models are open-sourced at https://huggingface.co/collections/m-a-p/hybrid-linear-attention-research-686c488a63d609d2f20e2b1e.
A Survey on Latent Reasoning
Jul 08, 2025



Large Language Models (LLMs) have demonstrated impressive reasoning capabilities, especially when guided by explicit chain-of-thought (CoT) reasoning that verbalizes intermediate steps. While CoT improves both interpretability and accuracy, its dependence on natural language reasoning limits the model's expressive bandwidth. Latent reasoning tackles this bottleneck by performing multi-step inference entirely in the model's continuous hidden state, eliminating token-level supervision. To advance latent reasoning research, this survey provides a comprehensive overview of the emerging field of latent reasoning. We begin by examining the foundational role of neural network layers as the computational substrate for reasoning, highlighting how hierarchical representations support complex transformations. Next, we explore diverse latent reasoning methodologies, including activation-based recurrence, hidden state propagation, and fine-tuning strategies that compress or internalize explicit reasoning traces. Finally, we discuss advanced paradigms such as infinite-depth latent reasoning via masked diffusion models, which enable globally consistent and reversible reasoning processes. By unifying these perspectives, we aim to clarify the conceptual landscape of latent reasoning and chart future directions for research at the frontier of LLM cognition. An associated GitHub repository collecting the latest papers and repos is available at: https://github.com/multimodal-art-projection/LatentCoT-Horizon/.
ARFlow: Autogressive Flow with Hybrid Linear Attention
Jan 27, 2025



Flow models are effective at progressively generating realistic images, but they generally struggle to capture long-range dependencies during the generation process as they compress all the information from previous time steps into a single corrupted image. To address this limitation, we propose integrating autoregressive modeling -- known for its excellence in modeling complex, high-dimensional joint probability distributions -- into flow models. During training, at each step, we construct causally-ordered sequences by sampling multiple images from the same semantic category and applying different levels of noise, where images with higher noise levels serve as causal predecessors to those with lower noise levels. This design enables the model to learn broader category-level variations while maintaining proper causal relationships in the flow process. During generation, the model autoregressively conditions the previously generated images from earlier denoising steps, forming a contextual and coherent generation trajectory. Additionally, we design a customized hybrid linear attention mechanism tailored to our modeling approach to enhance computational efficiency. Our approach, termed ARFlow, under 400k training steps, achieves 14.08 FID scores on ImageNet at 128 * 128 without classifier-free guidance, reaching 4.34 FID with classifier-free guidance 1.5, significantly outperforming the previous flow-based model SiT's 9.17 FID. Extensive ablation studies demonstrate the effectiveness of our modeling strategy and chunk-wise attention design.
Future-Guided Learning: A Predictive Approach To Enhance Time-Series Forecasting
Oct 19, 2024



Accurate time-series forecasting is essential across a multitude of scientific and industrial domains, yet deep learning models often struggle with challenges such as capturing long-term dependencies and adapting to drift in data distributions over time. We introduce Future-Guided Learning, an approach that enhances time-series event forecasting through a dynamic feedback mechanism inspired by predictive coding. Our approach involves two models: a detection model that analyzes future data to identify critical events and a forecasting model that predicts these events based on present data. When discrepancies arise between the forecasting and detection models, the forecasting model undergoes more substantial updates, effectively minimizing surprise and adapting to shifts in the data distribution by aligning its predictions with actual future outcomes. This feedback loop, drawing upon principles of predictive coding, enables the forecasting model to dynamically adjust its parameters, improving accuracy by focusing on features that remain relevant despite changes in the underlying data. We validate our method on a variety of tasks such as seizure prediction in biomedical signal analysis and forecasting in dynamical systems, achieving a 40\% increase in the area under the receiver operating characteristic curve (AUC-ROC) and a 10\% reduction in mean absolute error (MAE), respectively. By incorporating a predictive feedback mechanism that adapts to data distribution drift, Future-Guided Learning offers a promising avenue for advancing time-series forecasting with deep learning.
ON-OFF Neuromorphic ISING Machines using Fowler-Nordheim Annealers
Jun 07, 2024We introduce NeuroSA, a neuromorphic architecture specifically designed to ensure asymptotic convergence to the ground state of an Ising problem using an annealing process that is governed by the physics of quantum mechanical tunneling using Fowler-Nordheim (FN). The core component of NeuroSA consists of a pair of asynchronous ON-OFF neurons, which effectively map classical simulated annealing (SA) dynamics onto a network of integrate-and-fire (IF) neurons. The threshold of each ON-OFF neuron pair is adaptively adjusted by an FN annealer which replicates the optimal escape mechanism and convergence of SA, particularly at low temperatures. To validate the effectiveness of our neuromorphic Ising machine, we systematically solved various benchmark MAX-CUT combinatorial optimization problems. Across multiple runs, NeuroSA consistently generates solutions that approach the state-of-the-art level with high accuracy (greater than 99%), and without any graph-specific hyperparameter tuning. For practical illustration, we present results from an implementation of NeuroSA on the SpiNNaker2 platform, highlighting the feasibility of mapping our proposed architecture onto a standard neuromorphic accelerator platform.
Addressing cognitive bias in medical language models
Feb 20, 2024



There is increasing interest in the application large language models (LLMs) to the medical field, in part because of their impressive performance on medical exam questions. While promising, exam questions do not reflect the complexity of real patient-doctor interactions. In reality, physicians' decisions are shaped by many complex factors, such as patient compliance, personal experience, ethical beliefs, and cognitive bias. Taking a step toward understanding this, our hypothesis posits that when LLMs are confronted with clinical questions containing cognitive biases, they will yield significantly less accurate responses compared to the same questions presented without such biases. In this study, we developed BiasMedQA, a benchmark for evaluating cognitive biases in LLMs applied to medical tasks. Using BiasMedQA we evaluated six LLMs, namely GPT-4, Mixtral-8x70B, GPT-3.5, PaLM-2, Llama 2 70B-chat, and the medically specialized PMC Llama 13B. We tested these models on 1,273 questions from the US Medical Licensing Exam (USMLE) Steps 1, 2, and 3, modified to replicate common clinically-relevant cognitive biases. Our analysis revealed varying effects for biases on these LLMs, with GPT-4 standing out for its resilience to bias, in contrast to Llama 2 70B-chat and PMC Llama 13B, which were disproportionately affected by cognitive bias. Our findings highlight the critical need for bias mitigation in the development of medical LLMs, pointing towards safer and more reliable applications in healthcare.
Surgical Gym: A high-performance GPU-based platform for reinforcement learning with surgical robots
Oct 07, 2023

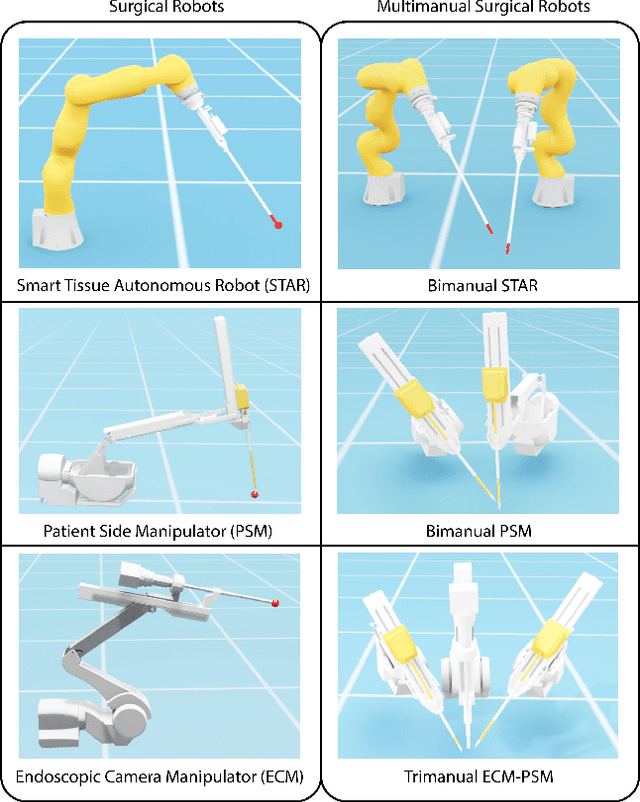

Recent advances in robot-assisted surgery have resulted in progressively more precise, efficient, and minimally invasive procedures, sparking a new era of robotic surgical intervention. This enables doctors, in collaborative interaction with robots, to perform traditional or minimally invasive surgeries with improved outcomes through smaller incisions. Recent efforts are working toward making robotic surgery more autonomous which has the potential to reduce variability of surgical outcomes and reduce complication rates. Deep reinforcement learning methodologies offer scalable solutions for surgical automation, but their effectiveness relies on extensive data acquisition due to the absence of prior knowledge in successfully accomplishing tasks. Due to the intensive nature of simulated data collection, previous works have focused on making existing algorithms more efficient. In this work, we focus on making the simulator more efficient, making training data much more accessible than previously possible. We introduce Surgical Gym, an open-source high performance platform for surgical robot learning where both the physics simulation and reinforcement learning occur directly on the GPU. We demonstrate between 100-5000x faster training times compared with previous surgical learning platforms. The code is available at: https://github.com/SamuelSchmidgall/SurgicalGym.