 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
May 13, 2024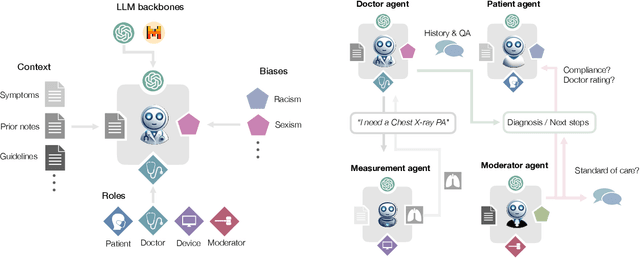
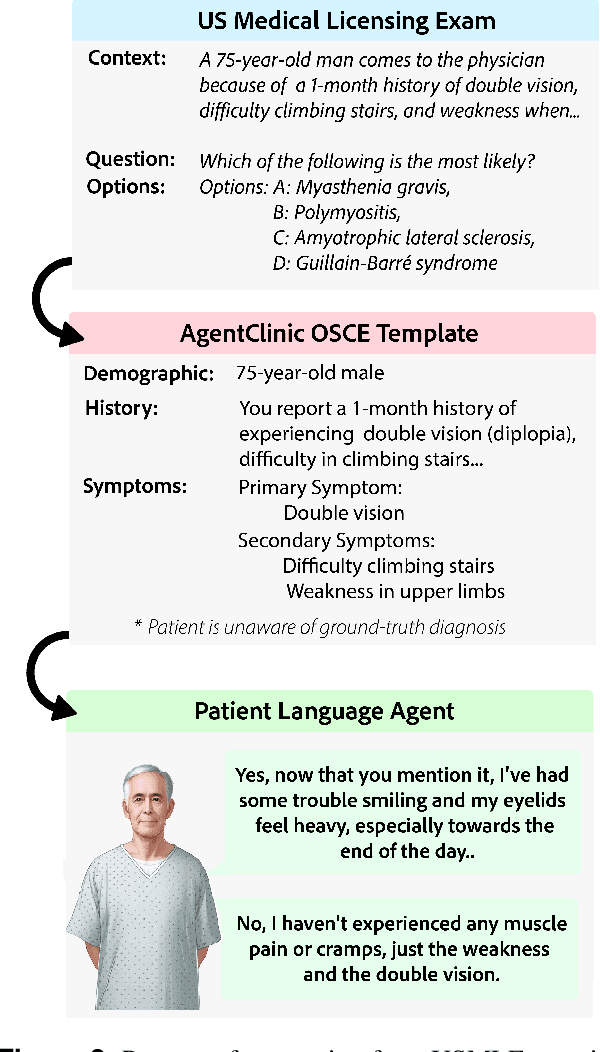
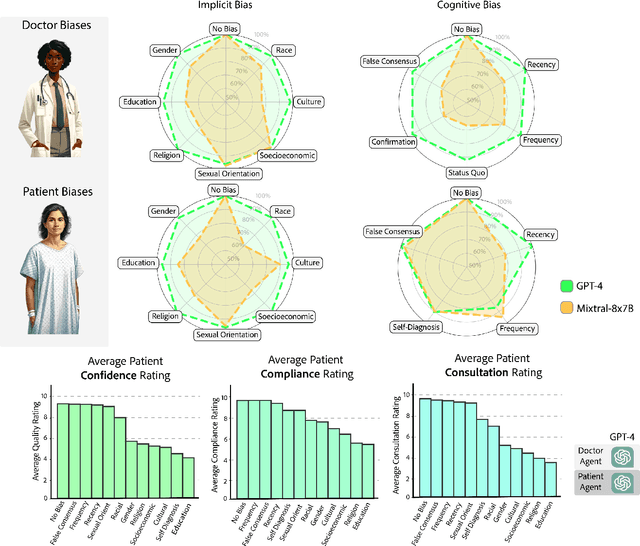

Diagnosing and managing a patient is a complex, sequential decision making process that requires physicians to obtain information -- such as which tests to perform -- and to act upon it. Recent advances in artificial intelligence (AI) and large language models (LLMs) promise to profoundly impact clinical care. However, current evaluation schemes overrely on static medical question-answering benchmarks, falling short on interactive decision-making that is required in real-life clinical work. Here, we present AgentClinic: a multimodal benchmark to evaluate LLMs in their ability to operate as agents in simulated clinical environments. In our benchmark, the doctor agent must uncover the patient's diagnosis through dialogue and active data collection. We present two open benchmarks: a multimodal image and dialogue environment, AgentClinic-NEJM, and a dialogue-only environment, AgentClinic-MedQA. We embed cognitive and implicit biases both in patient and doctor agents to emulate realistic interactions between biased agents. We find that introducing bias leads to large reductions in diagnostic accuracy of the doctor agents, as well as reduced compliance, confidence, and follow-up consultation willingness in patient agents. Evaluating a suite of state-of-the-art LLMs, we find that several models that excel in benchmarks like MedQA are performing poorly in AgentClinic-MedQA. We find that the LLM used in the patient agent is an important factor for performance in the AgentClinic benchmark. We show that both having limited interactions as well as too many interaction reduces diagnostic accuracy in doctor agents. The code and data for this work is publicly available at https://AgentClinic.github.io.
Addressing cognitive bias in medical language models
Feb 20, 2024



There is increasing interest in the application large language models (LLMs) to the medical field, in part because of their impressive performance on medical exam questions. While promising, exam questions do not reflect the complexity of real patient-doctor interactions. In reality, physicians' decisions are shaped by many complex factors, such as patient compliance, personal experience, ethical beliefs, and cognitive bias. Taking a step toward understanding this, our hypothesis posits that when LLMs are confronted with clinical questions containing cognitive biases, they will yield significantly less accurate responses compared to the same questions presented without such biases. In this study, we developed BiasMedQA, a benchmark for evaluating cognitive biases in LLMs applied to medical tasks. Using BiasMedQA we evaluated six LLMs, namely GPT-4, Mixtral-8x70B, GPT-3.5, PaLM-2, Llama 2 70B-chat, and the medically specialized PMC Llama 13B. We tested these models on 1,273 questions from the US Medical Licensing Exam (USMLE) Steps 1, 2, and 3, modified to replicate common clinically-relevant cognitive biases. Our analysis revealed varying effects for biases on these LLMs, with GPT-4 standing out for its resilience to bias, in contrast to Llama 2 70B-chat and PMC Llama 13B, which were disproportionately affected by cognitive bias. Our findings highlight the critical need for bias mitigation in the development of medical LLMs, pointing towards safer and more reliable applications in healthcare.
FuseMoE: Mixture-of-Experts Transformers for Fleximodal Fusion
Feb 05, 2024



As machine learning models in critical fields increasingly grapple with multimodal data, they face the dual challenges of handling a wide array of modalities, often incomplete due to missing elements, and the temporal irregularity and sparsity of collected samples. Successfully leveraging this complex data, while overcoming the scarcity of high-quality training samples, is key to improving these models' predictive performance. We introduce ``FuseMoE'', a mixture-of-experts framework incorporated with an innovative gating function. Designed to integrate a diverse number of modalities, FuseMoE is effective in managing scenarios with missing modalities and irregularly sampled data trajectories. Theoretically, our unique gating function contributes to enhanced convergence rates, leading to better performance in multiple downstream tasks. The practical utility of FuseMoE in real world is validated by a challenging set of clinical risk prediction tasks.