 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpen-H-Embodiment: A Large-Scale Dataset for Enabling Foundation Models in Medical Robotics
Apr 22, 2026Autonomous medical robots hold promise to improve patient outcomes, reduce provider workload, democratize access to care, and enable superhuman precision. However, autonomous medical robotics has been limited by a fundamental data problem: existing medical robotic datasets are small, single-embodiment, and rarely shared openly, restricting the development of foundation models that the field needs to advance. We introduce Open-H-Embodiment, the largest open dataset of medical robotic video with synchronized kinematics to date, spanning more than 49 institutions and multiple robotic platforms including the CMR Versius, Intuitive Surgical's da Vinci, da Vinci Research Kit (dVRK), Rob Surgical BiTrack, Virtual Incision's MIRA, Moon Surgical Maestro, and a variety of custom systems, spanning surgical manipulation, robotic ultrasound, and endoscopy procedures. We demonstrate the research enabled by this dataset through two foundation models. GR00T-H is the first open foundation vision-language-action model for medical robotics, which is the only evaluated model to achieve full end-to-end task completion on a structured suturing benchmark (25% of trials vs. 0% for all others) and achieves 64% average success across a 29-step ex vivo suturing sequence. We also train Cosmos-H-Surgical-Simulator, the first action-conditioned world model to enable multi-embodiment surgical simulation from a single checkpoint, spanning nine robotic platforms and supporting in silico policy evaluation and synthetic data generation for the medical domain. These results suggest that open, large-scale medical robot data collection can serve as critical infrastructure for the research community, enabling advances in robot learning, world modeling, and beyond.
SRT-H: A Hierarchical Framework for Autonomous Surgery via Language Conditioned Imitation Learning
May 15, 2025Research on autonomous robotic surgery has largely focused on simple task automation in controlled environments. However, real-world surgical applications require dexterous manipulation over extended time scales while demanding generalization across diverse variations in human tissue. These challenges remain difficult to address using existing logic-based or conventional end-to-end learning strategies. To bridge this gap, we propose a hierarchical framework for dexterous, long-horizon surgical tasks. Our method employs a high-level policy for task planning and a low-level policy for generating task-space controls for the surgical robot. The high-level planner plans tasks using language, producing task-specific or corrective instructions that guide the robot at a coarse level. Leveraging language as a planning modality offers an intuitive and generalizable interface, mirroring how experienced surgeons instruct traineers during procedures. We validate our framework in ex-vivo experiments on a complex minimally invasive procedure, cholecystectomy, and conduct ablative studies to assess key design choices. Our approach achieves a 100% success rate across n=8 different ex-vivo gallbladders, operating fully autonomously without human intervention. The hierarchical approach greatly improves the policy's ability to recover from suboptimal states that are inevitable in the highly dynamic environment of realistic surgical applications. This work represents the first demonstration of step-level autonomy, marking a critical milestone toward autonomous surgical systems for clinical studies. By advancing generalizable autonomy in surgical robotics, our approach brings the field closer to real-world deployment.
Systematic Evaluation of Large Vision-Language Models for Surgical Artificial Intelligence
Apr 03, 2025Large Vision-Language Models offer a new paradigm for AI-driven image understanding, enabling models to perform tasks without task-specific training. This flexibility holds particular promise across medicine, where expert-annotated data is scarce. Yet, VLMs' practical utility in intervention-focused domains--especially surgery, where decision-making is subjective and clinical scenarios are variable--remains uncertain. Here, we present a comprehensive analysis of 11 state-of-the-art VLMs across 17 key visual understanding tasks in surgical AI--from anatomy recognition to skill assessment--using 13 datasets spanning laparoscopic, robotic, and open procedures. In our experiments, VLMs demonstrate promising generalizability, at times outperforming supervised models when deployed outside their training setting. In-context learning, incorporating examples during testing, boosted performance up to three-fold, suggesting adaptability as a key strength. Still, tasks requiring spatial or temporal reasoning remained difficult. Beyond surgery, our findings offer insights into VLMs' potential for tackling complex and dynamic scenarios in clinical and broader real-world applications.
AgentClinic: a multimodal agent benchmark to evaluate AI in simulated clinical environments
May 13, 2024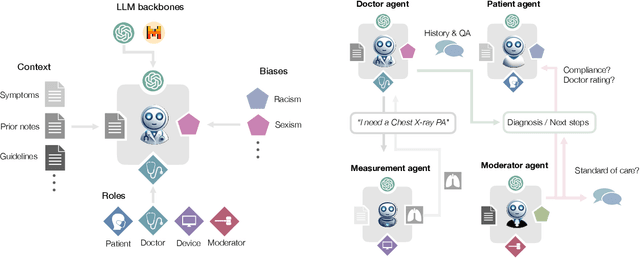
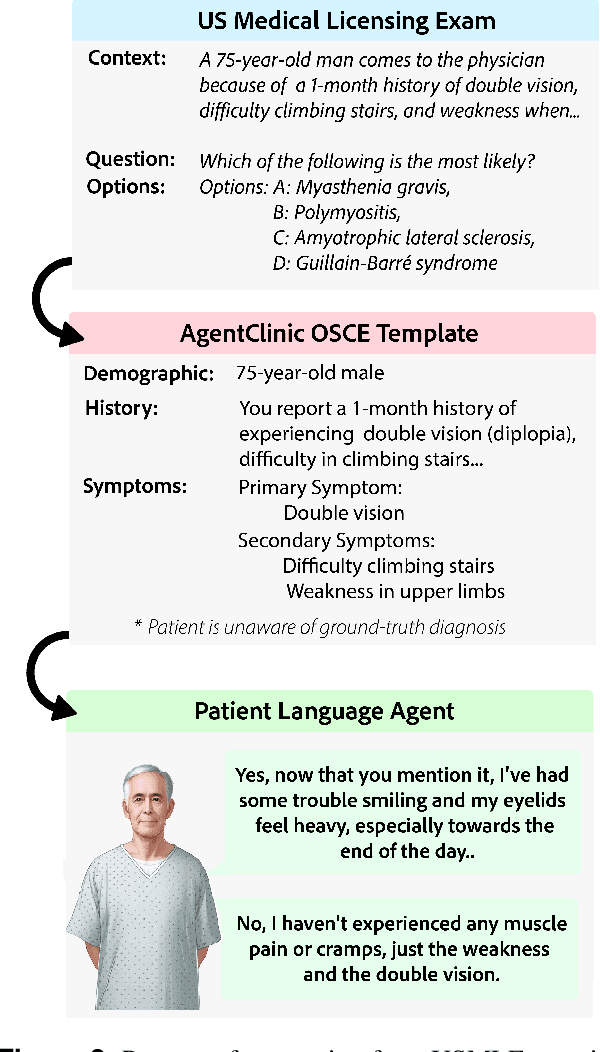
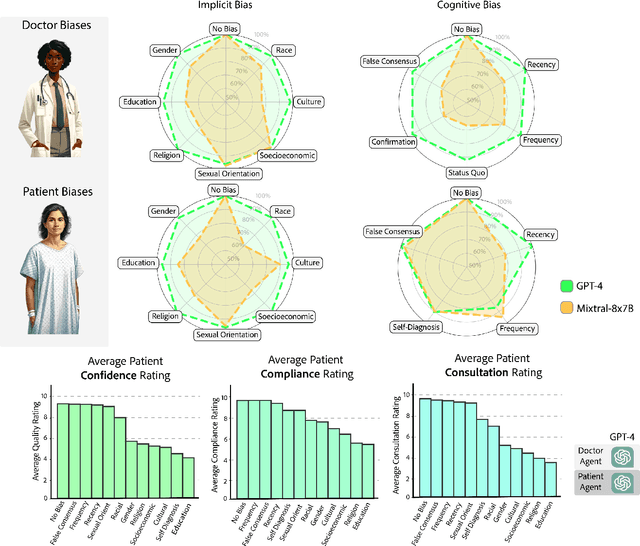

Diagnosing and managing a patient is a complex, sequential decision making process that requires physicians to obtain information -- such as which tests to perform -- and to act upon it. Recent advances in artificial intelligence (AI) and large language models (LLMs) promise to profoundly impact clinical care. However, current evaluation schemes overrely on static medical question-answering benchmarks, falling short on interactive decision-making that is required in real-life clinical work. Here, we present AgentClinic: a multimodal benchmark to evaluate LLMs in their ability to operate as agents in simulated clinical environments. In our benchmark, the doctor agent must uncover the patient's diagnosis through dialogue and active data collection. We present two open benchmarks: a multimodal image and dialogue environment, AgentClinic-NEJM, and a dialogue-only environment, AgentClinic-MedQA. We embed cognitive and implicit biases both in patient and doctor agents to emulate realistic interactions between biased agents. We find that introducing bias leads to large reductions in diagnostic accuracy of the doctor agents, as well as reduced compliance, confidence, and follow-up consultation willingness in patient agents. Evaluating a suite of state-of-the-art LLMs, we find that several models that excel in benchmarks like MedQA are performing poorly in AgentClinic-MedQA. We find that the LLM used in the patient agent is an important factor for performance in the AgentClinic benchmark. We show that both having limited interactions as well as too many interaction reduces diagnostic accuracy in doctor agents. The code and data for this work is publicly available at https://AgentClinic.github.io.
Tool Detection and Operative Skill Assessment in Surgical Videos Using Region-Based Convolutional Neural Networks
Jul 22, 2018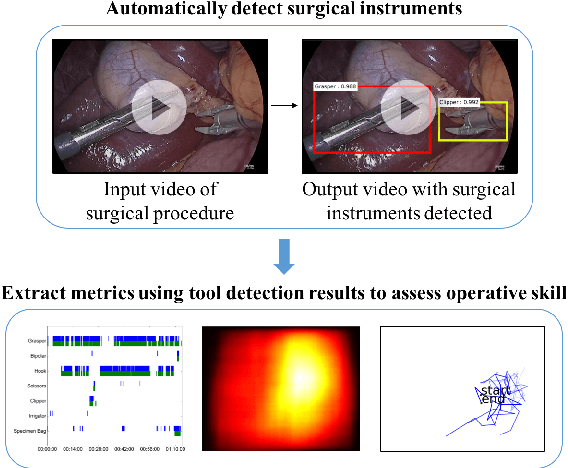

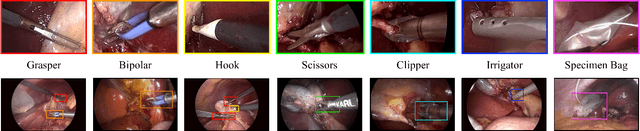

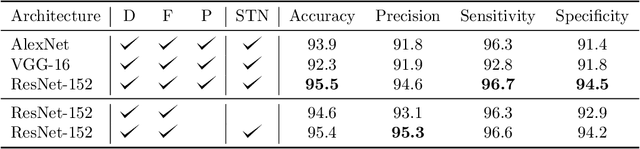
Five billion people in the world lack access to quality surgical care. Surgeon skill varies dramatically, and many surgical patients suffer complications and avoidable harm. Improving surgical training and feedback would help to reduce the rate of complications, half of which have been shown to be preventable. To do this, it is essential to assess operative skill, a process that currently requires experts and is manual, time consuming, and subjective. In this work, we introduce an approach to automatically assess surgeon performance by tracking and analyzing tool movements in surgical videos, leveraging region-based convolutional neural networks. In order to study this problem, we also introduce a new dataset, m2cai16-tool-locations, which extends the m2cai16-tool dataset with spatial bounds of tools. While previous methods have addressed tool presence detection, ours is the first to not only detect presence but also spatially localize surgical tools in real-world laparoscopic surgical videos. We show that our method both effectively detects the spatial bounds of tools as well as significantly outperforms existing methods on tool presence detection. We further demonstrate the ability of our method to assess surgical quality through analysis of tool usage patterns, movement range, and economy of motion.
Towards Vision-Based Smart Hospitals: A System for Tracking and Monitoring Hand Hygiene Compliance
Apr 24, 2018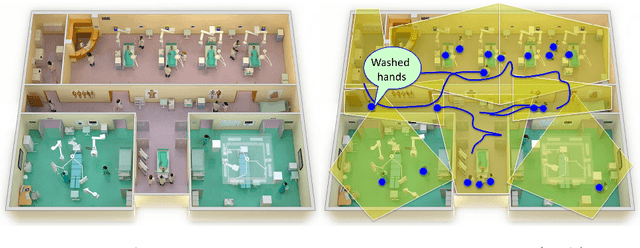


One in twenty-five patients admitted to a hospital will suffer from a hospital acquired infection. If we can intelligently track healthcare staff, patients, and visitors, we can better understand the sources of such infections. We envision a smart hospital capable of increasing operational efficiency and improving patient care with less spending. In this paper, we propose a non-intrusive vision-based system for tracking people's activity in hospitals. We evaluate our method for the problem of measuring hand hygiene compliance. Empirically, our method outperforms existing solutions such as proximity-based techniques and covert in-person observational studies. We present intuitive, qualitative results that analyze human movement patterns and conduct spatial analytics which convey our method's interpretability. This work is a step towards a computer-vision based smart hospital and demonstrates promising results for reducing hospital acquired infections.
* Machine Learning for Healthcare Conference (MLHC)