 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Spoken Language Translation
Apr 23, 2019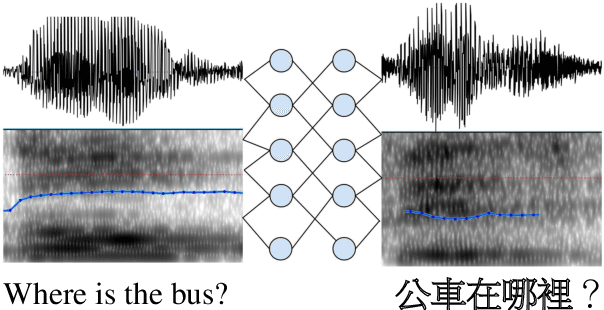
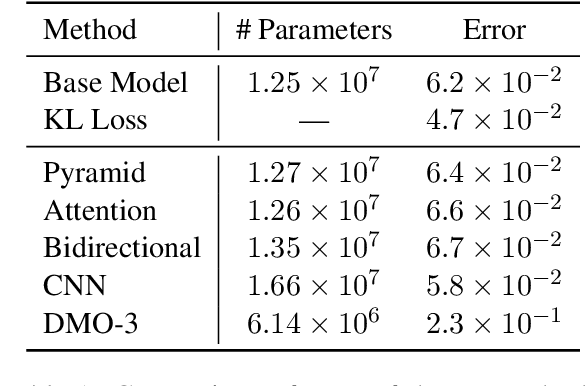
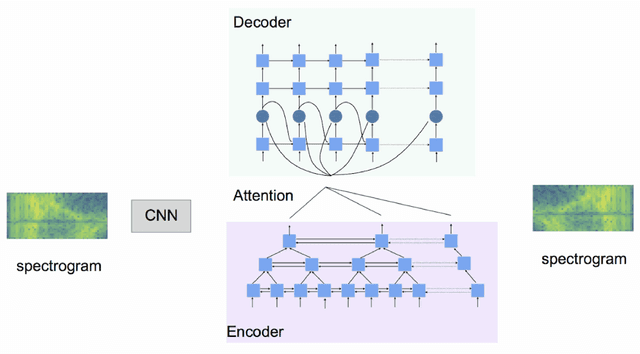
In this paper, we address the task of spoken language understanding. We present a method for translating spoken sentences from one language into spoken sentences in another language. Given spectrogram-spectrogram pairs, our model can be trained completely from scratch to translate unseen sentences. Our method consists of a pyramidal-bidirectional recurrent network combined with a convolutional network to output sentence-level spectrograms in the target language. Empirically, our model achieves competitive performance with state-of-the-art methods on multiple languages and can generalize to unseen speakers.
Audio-Linguistic Embeddings for Spoken Sentences
Feb 20, 2019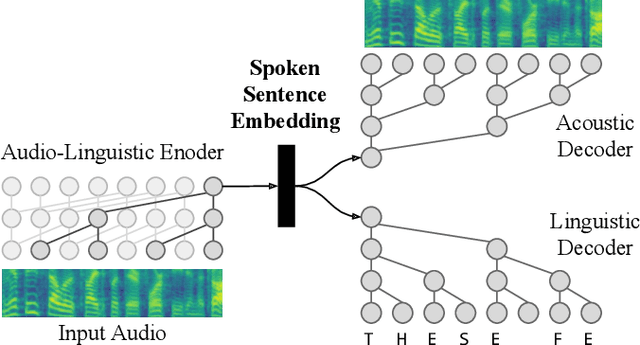
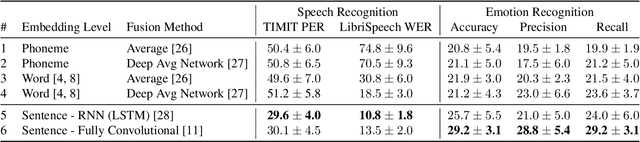
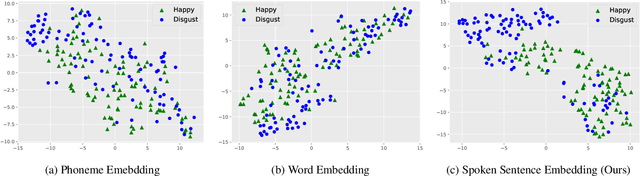
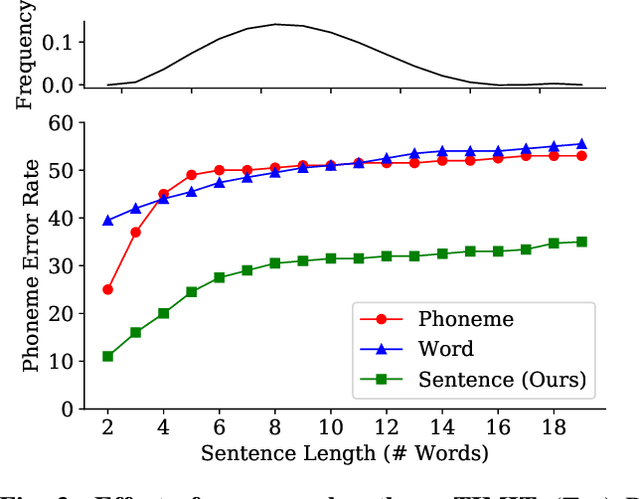
We propose spoken sentence embeddings which capture both acoustic and linguistic content. While existing works operate at the character, phoneme, or word level, our method learns long-term dependencies by modeling speech at the sentence level. Formulated as an audio-linguistic multitask learning problem, our encoder-decoder model simultaneously reconstructs acoustic and natural language features from audio. Our results show that spoken sentence embeddings outperform phoneme and word-level baselines on speech recognition and emotion recognition tasks. Ablation studies show that our embeddings can better model high-level acoustic concepts while retaining linguistic content. Overall, our work illustrates the viability of generic, multi-modal sentence embeddings for spoken language understanding.
Twitch Plays Pokemon, Machine Learns Twitch: Unsupervised Context-Aware Anomaly Detection for Identifying Trolls in Streaming Data
Feb 17, 2019
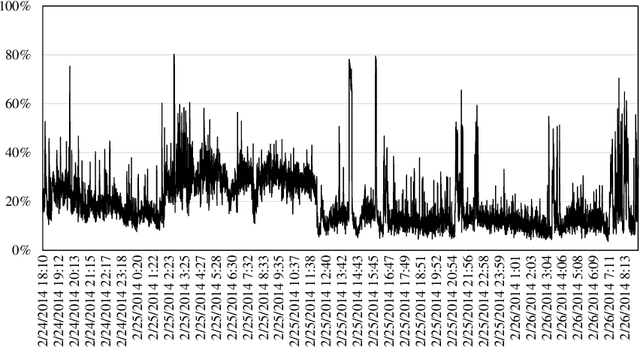
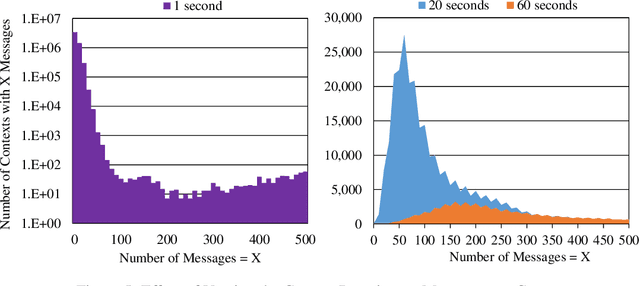
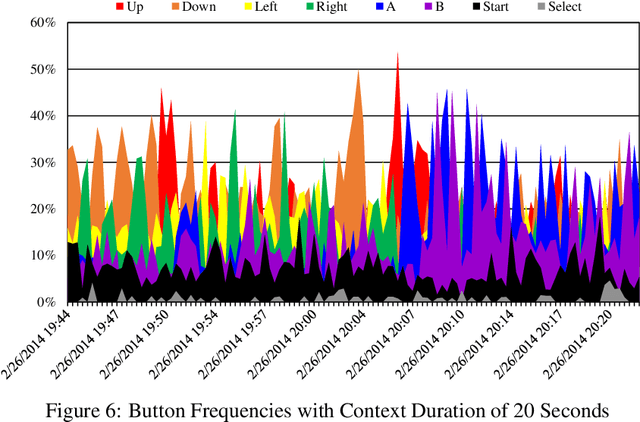
With the increasing importance of online communities, discussion forums, and customer reviews, Internet "trolls" have proliferated thereby making it difficult for information seekers to find relevant and correct information. In this paper, we consider the problem of detecting and identifying Internet trolls, almost all of which are human agents. Identifying a human agent among a human population presents significant challenges compared to detecting automated spam or computerized robots. To learn a troll's behavior, we use contextual anomaly detection to profile each chat user. Using clustering and distance-based methods, we use contextual data such as the group's current goal, the current time, and the username to classify each point as an anomaly. A user whose features significantly differ from the norm will be classified as a troll. We collected 38 million data points from the viral Internet fad, Twitch Plays Pokemon. Using clustering and distance-based methods, we develop heuristics for identifying trolls. Using MapReduce techniques for preprocessing and user profiling, we are able to classify trolls based on 10 features extracted from a user's lifetime history.
Measuring Depression Symptom Severity from Spoken Language and 3D Facial Expressions
Nov 27, 2018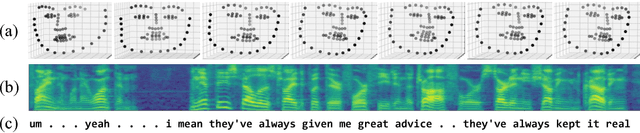
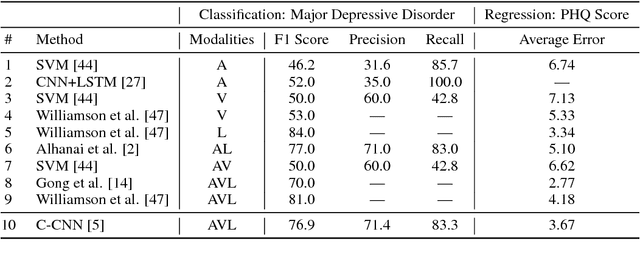
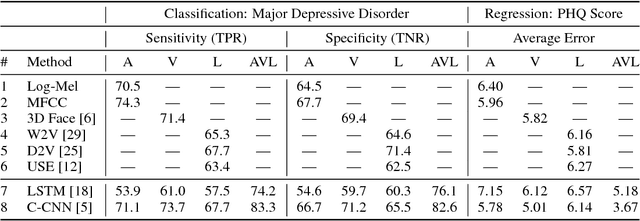
With more than 300 million people depressed worldwide, depression is a global problem. Due to access barriers such as social stigma, cost, and treatment availability, 60% of mentally-ill adults do not receive any mental health services. Effective and efficient diagnosis relies on detecting clinical symptoms of depression. Automatic detection of depressive symptoms would potentially improve diagnostic accuracy and availability, leading to faster intervention. In this work, we present a machine learning method for measuring the severity of depressive symptoms. Our multi-modal method uses 3D facial expressions and spoken language, commonly available from modern cell phones. It demonstrates an average error of 3.67 points (15.3% relative) on the clinically-validated Patient Health Questionnaire (PHQ) scale. For detecting major depressive disorder, our model demonstrates 83.3% sensitivity and 82.6% specificity. Overall, this paper shows how speech recognition, computer vision, and natural language processing can be combined to assist mental health patients and practitioners. This technology could be deployed to cell phones worldwide and facilitate low-cost universal access to mental health care.
Privacy-Preserving Action Recognition for Smart Hospitals using Low-Resolution Depth Images
Nov 25, 2018


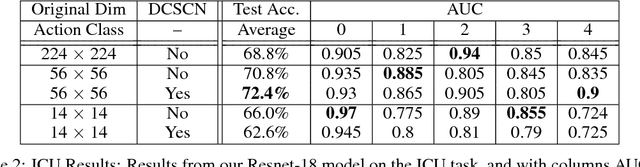
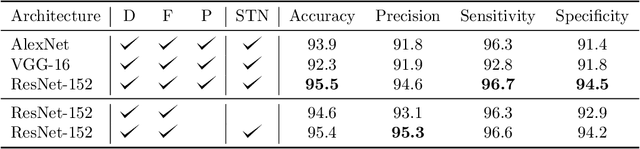
Computer-vision hospital systems can greatly assist healthcare workers and improve medical facility treatment, but often face patient resistance due to the perceived intrusiveness and violation of privacy associated with visual surveillance. We downsample video frames to extremely low resolutions to degrade private information from surveillance videos. We measure the amount of activity-recognition information retained in low resolution depth images, and also apply a privately-trained DCSCN super-resolution model to enhance the utility of our images. We implement our techniques with two actual healthcare-surveillance scenarios, hand-hygiene compliance and ICU activity-logging, and show that our privacy-preserving techniques preserve enough information for realistic healthcare tasks.
Automatic Documentation of ICD Codes with Far-Field Speech Recognition
Nov 04, 2018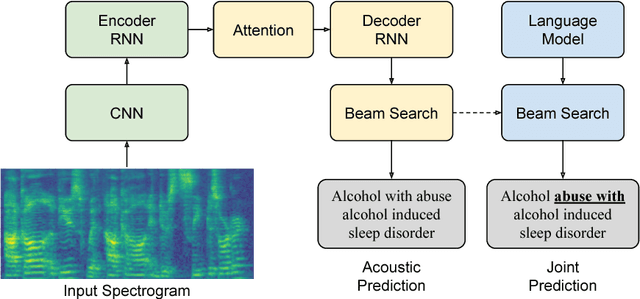
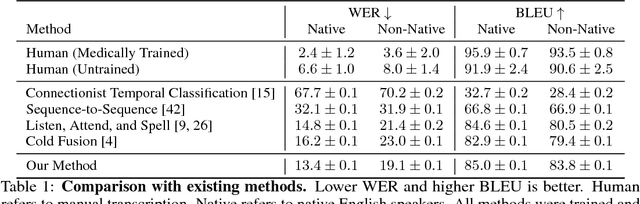
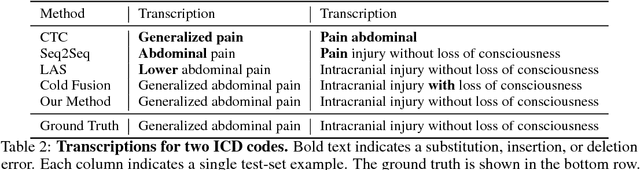
Documentation errors increase healthcare costs and cause unnecessary patient deaths. As the standard language for diagnoses and billing, ICD codes serve as the foundation for medical documentation worldwide. Despite the prevalence of electronic medical records, hospitals still witness high levels of ICD miscoding. In this paper, we propose to automatically document ICD codes with far-field speech recognition. Far-field speech occurs when the microphone is located several meters from the source, as is common with smart homes and security systems. Our method combines acoustic signal processing with recurrent neural networks to recognize and document ICD codes in real time. To evaluate our model, we collected a far-field speech dataset of ICD-10 codes and found our model to achieve 87% accuracy with a BLEU score of 85%. By sampling from an unsupervised medical language model, our method is able to outperform existing methods. Overall, this work shows the potential of automatic speech recognition to provide efficient, accurate, and cost-effective healthcare documentation.
Conditional End-to-End Audio Transforms
Jun 07, 2018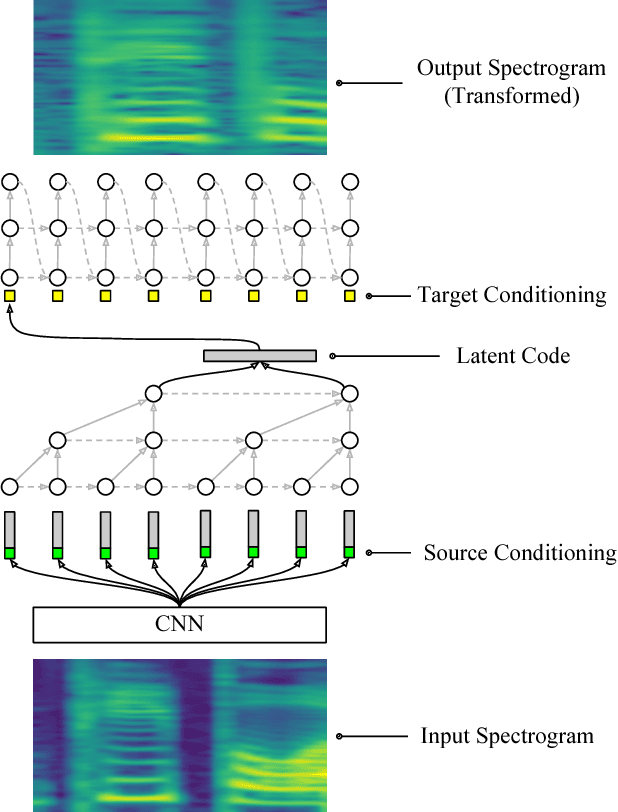
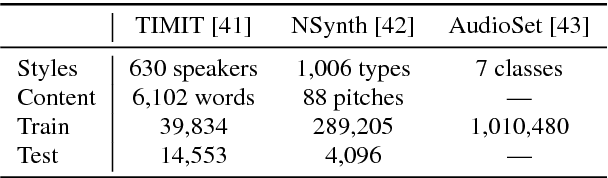
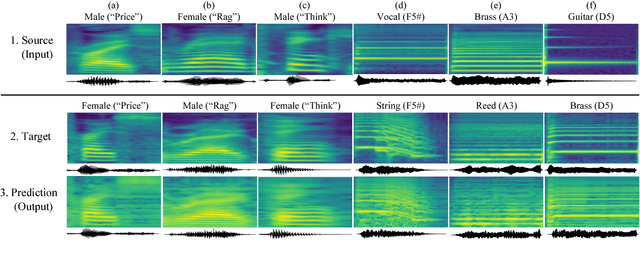
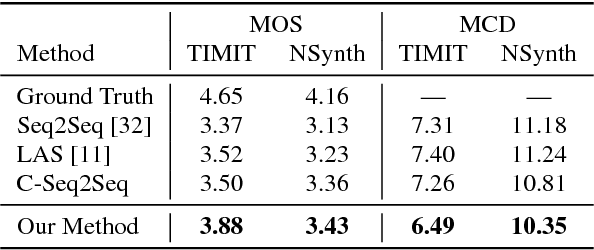
We present an end-to-end method for transforming audio from one style to another. For the case of speech, by conditioning on speaker identities, we can train a single model to transform words spoken by multiple people into multiple target voices. For the case of music, we can specify musical instruments and achieve the same result. Architecturally, our method is a fully-differentiable sequence-to-sequence model based on convolutional and hierarchical recurrent neural networks. It is designed to capture long-term acoustic dependencies, requires minimal post-processing, and produces realistic audio transforms. Ablation studies confirm that our model can separate speaker and instrument properties from acoustic content at different receptive fields. Empirically, our method achieves competitive performance on community-standard datasets.
Towards Vision-Based Smart Hospitals: A System for Tracking and Monitoring Hand Hygiene Compliance
Apr 24, 2018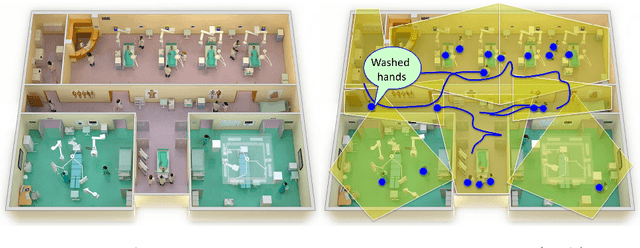


One in twenty-five patients admitted to a hospital will suffer from a hospital acquired infection. If we can intelligently track healthcare staff, patients, and visitors, we can better understand the sources of such infections. We envision a smart hospital capable of increasing operational efficiency and improving patient care with less spending. In this paper, we propose a non-intrusive vision-based system for tracking people's activity in hospitals. We evaluate our method for the problem of measuring hand hygiene compliance. Empirically, our method outperforms existing solutions such as proximity-based techniques and covert in-person observational studies. We present intuitive, qualitative results that analyze human movement patterns and conduct spatial analytics which convey our method's interpretability. This work is a step towards a computer-vision based smart hospital and demonstrates promising results for reducing hospital acquired infections.
* Machine Learning for Healthcare Conference (MLHC)
Recurrent Attention Models for Depth-Based Person Identification
Nov 22, 2016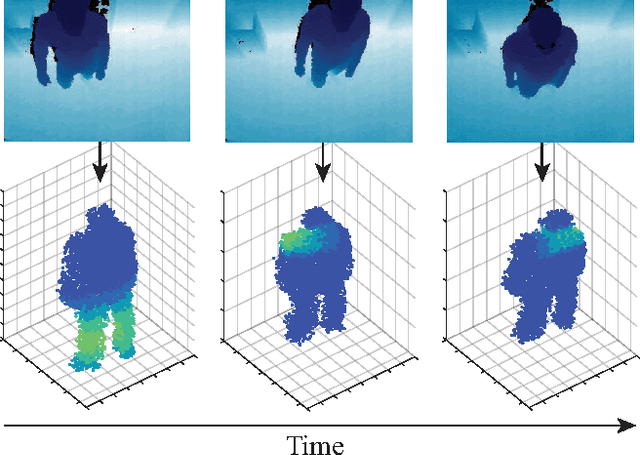

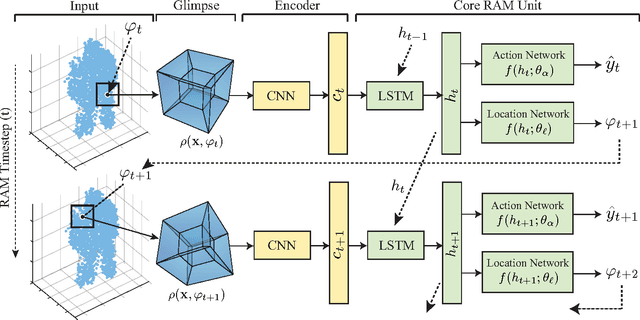
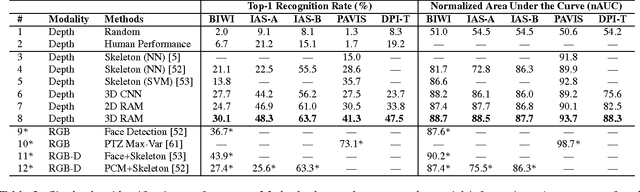
We present an attention-based model that reasons on human body shape and motion dynamics to identify individuals in the absence of RGB information, hence in the dark. Our approach leverages unique 4D spatio-temporal signatures to address the identification problem across days. Formulated as a reinforcement learning task, our model is based on a combination of convolutional and recurrent neural networks with the goal of identifying small, discriminative regions indicative of human identity. We demonstrate that our model produces state-of-the-art results on several published datasets given only depth images. We further study the robustness of our model towards viewpoint, appearance, and volumetric changes. Finally, we share insights gleaned from interpretable 2D, 3D, and 4D visualizations of our model's spatio-temporal attention.
Towards Viewpoint Invariant 3D Human Pose Estimation
Jul 26, 2016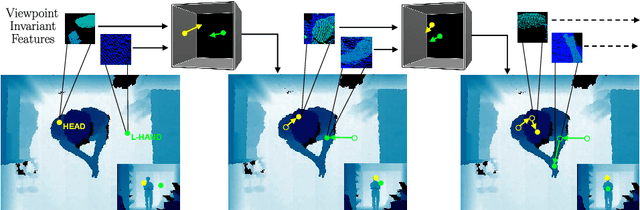
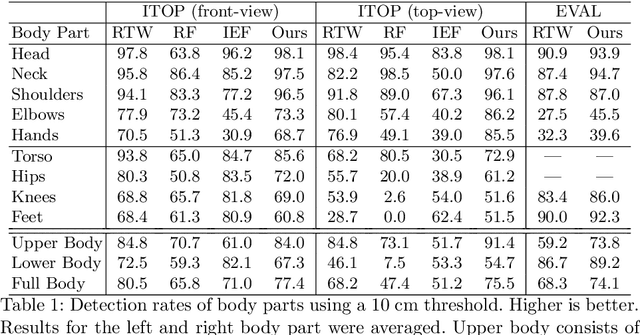
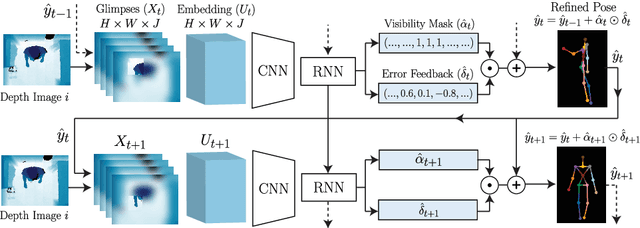
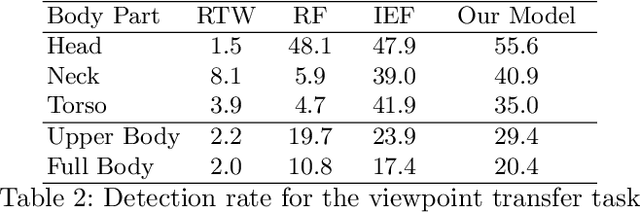
We propose a viewpoint invariant model for 3D human pose estimation from a single depth image. To achieve this, our discriminative model embeds local regions into a learned viewpoint invariant feature space. Formulated as a multi-task learning problem, our model is able to selectively predict partial poses in the presence of noise and occlusion. Our approach leverages a convolutional and recurrent network architecture with a top-down error feedback mechanism to self-correct previous pose estimates in an end-to-end manner. We evaluate our model on a previously published depth dataset and a newly collected human pose dataset containing 100K annotated depth images from extreme viewpoints. Experiments show that our model achieves competitive performance on frontal views while achieving state-of-the-art performance on alternate viewpoints.