 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImaginative Perception Tokens Enhance Spatial Reasoning in Multimodal Language Models
Jun 03, 2026Vision language models (VLMs) excel at many tasks but still struggle with spatial reasoning when critical information is not directly observable. Many such problems require imaginative perception: inferring what would be seen from an unseen viewpoint, tracing paths through occluded spaces, or integrating partial observations into a coherent spatial representation. We introduce Imaginative Perception Tokens (IPT), intermediate perceptual representations that externalize what a VLM would perceive under alternative spatial configurations while remaining consistent with the observed input. To study this capability, we formulate three tasks, Perspective Taking (PET), Path Tracing (PT), and Multiview Counting (MVC), and construct datasets of approximately 20K examples with ground truth imaginations, answers, and evaluation benchmarks. Using the unified VLM BAGEL as the backbone, IPT supervision consistently improves spatial reasoning and often outperforms textual chain of thought training, even without generating images at inference time. On MVC, IPT improves accuracy by 3.4% and achieves competitive performance with strong closed-source models on PT. We further find that combining IPT and label-only supervision yields additional gains, whereas textual chain of thought can substantially degrade performance, suggesting a modality mismatch when spatial computation is forced through language. Overall, IPT provides a principled supervision signal for reasoning about unobserved spatial structure, improving generalization while producing interpretable intermediate representations.
Perception Tokens Enhance Visual Reasoning in Multimodal Language Models
Dec 04, 2024Multimodal language models (MLMs) still face challenges in fundamental visual perception tasks where specialized models excel. Tasks requiring reasoning about 3D structures benefit from depth estimation, and reasoning about 2D object instances benefits from object detection. Yet, MLMs can not produce intermediate depth or boxes to reason over. Finetuning MLMs on relevant data doesn't generalize well and outsourcing computation to specialized vision tools is too compute-intensive and memory-inefficient. To address this, we introduce Perception Tokens, intrinsic image representations designed to assist reasoning tasks where language is insufficient. Perception tokens act as auxiliary reasoning tokens, akin to chain-of-thought prompts in language models. For example, in a depth-related task, an MLM augmented with perception tokens can reason by generating a depth map as tokens, enabling it to solve the problem effectively. We propose AURORA, a training method that augments MLMs with perception tokens for improved reasoning over visual inputs. AURORA leverages a VQVAE to transform intermediate image representations, such as depth maps into a tokenized format and bounding box tokens, which is then used in a multi-task training framework. AURORA achieves notable improvements across counting benchmarks: +10.8% on BLINK, +11.3% on CVBench, and +8.3% on SEED-Bench, outperforming finetuning approaches in generalization across datasets. It also improves on relative depth: over +6% on BLINK. With perception tokens, AURORA expands the scope of MLMs beyond language-based reasoning, paving the way for more effective visual reasoning capabilities.
Few-Shot Classification of Interactive Activities of Daily Living (InteractADL)
Jun 03, 2024

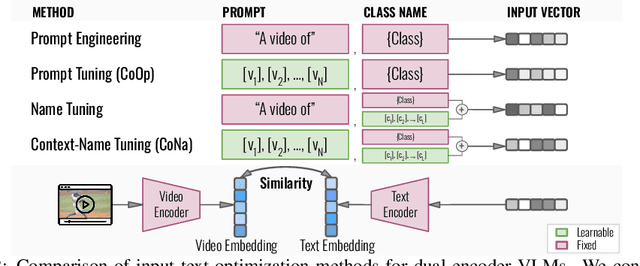

Understanding Activities of Daily Living (ADLs) is a crucial step for different applications including assistive robots, smart homes, and healthcare. However, to date, few benchmarks and methods have focused on complex ADLs, especially those involving multi-person interactions in home environments. In this paper, we propose a new dataset and benchmark, InteractADL, for understanding complex ADLs that involve interaction between humans (and objects). Furthermore, complex ADLs occurring in home environments comprise a challenging long-tailed distribution due to the rarity of multi-person interactions, and pose fine-grained visual recognition tasks due to the presence of semantically and visually similar classes. To address these issues, we propose a novel method for fine-grained few-shot video classification called Name Tuning that enables greater semantic separability by learning optimal class name vectors. We show that Name Tuning can be combined with existing prompt tuning strategies to learn the entire input text (rather than only learning the prompt or class names) and demonstrate improved performance for few-shot classification on InteractADL and 4 other fine-grained visual classification benchmarks. For transparency and reproducibility, we release our code at https://github.com/zanedurante/vlm_benchmark.
Differentially Private Video Activity Recognition
Jun 27, 2023



In recent years, differential privacy has seen significant advancements in image classification; however, its application to video activity recognition remains under-explored. This paper addresses the challenges of applying differential privacy to video activity recognition, which primarily stem from: (1) a discrepancy between the desired privacy level for entire videos and the nature of input data processed by contemporary video architectures, which are typically short, segmented clips; and (2) the complexity and sheer size of video datasets relative to those in image classification, which render traditional differential privacy methods inadequate. To tackle these issues, we propose Multi-Clip DP-SGD, a novel framework for enforcing video-level differential privacy through clip-based classification models. This method samples multiple clips from each video, averages their gradients, and applies gradient clipping in DP-SGD without incurring additional privacy loss. Moreover, we incorporate a parameter-efficient transfer learning strategy to make the model scalable for large-scale video datasets. Through extensive evaluations on the UCF-101 and HMDB-51 datasets, our approach exhibits impressive performance, achieving 81% accuracy with a privacy budget of epsilon=5 on UCF-101, marking a 76% improvement compared to a direct application of DP-SGD. Furthermore, we demonstrate that our transfer learning strategy is versatile and can enhance differentially private image classification across an array of datasets including CheXpert, ImageNet, CIFAR-10, and CIFAR-100.
Vision-Based Gait Analysis for Senior Care
Dec 01, 2018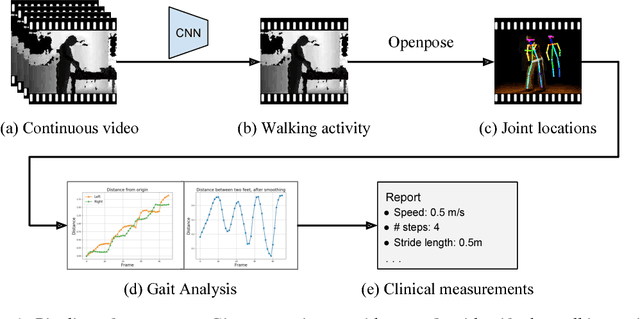

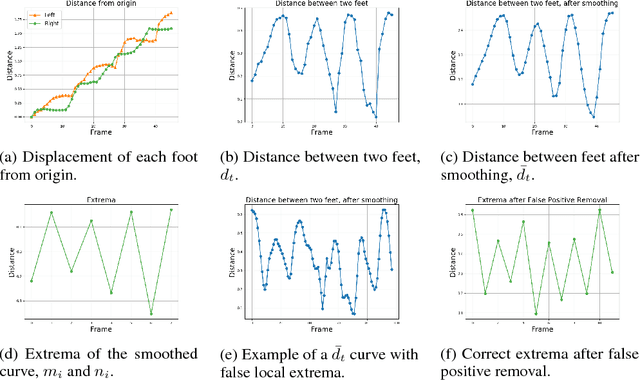
As the senior population rapidly increases, it is challenging yet crucial to provide effective long-term care for seniors who live at home or in senior care facilities. Smart senior homes, which have gained widespread interest in the healthcare community, have been proposed to improve the well-being of seniors living independently. In particular, non-intrusive, cost-effective sensors placed in these senior homes enable gait characterization, which can provide clinically relevant information including mobility level and early neurodegenerative disease risk. In this paper, we present a method to perform gait analysis from a single camera placed within the home. We show that we can accurately calculate various gait parameters, demonstrating the potential for our system to monitor the long-term gait of seniors and thus aid clinicians in understanding a patient's medical profile.
DF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency
Sep 05, 2018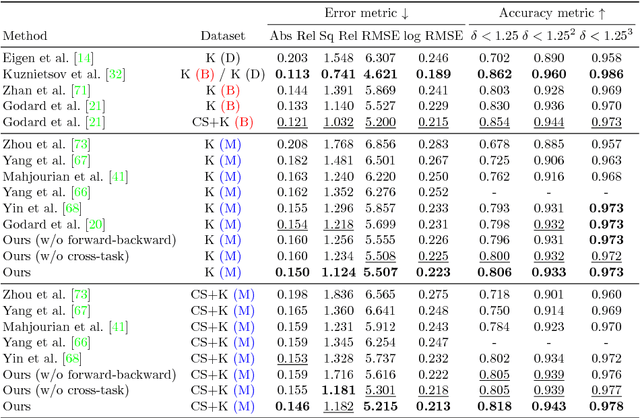


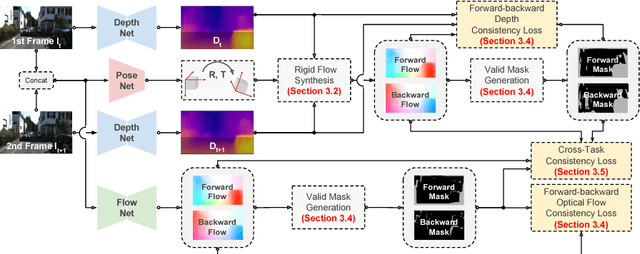
We present an unsupervised learning framework for simultaneously training single-view depth prediction and optical flow estimation models using unlabeled video sequences. Existing unsupervised methods often exploit brightness constancy and spatial smoothness priors to train depth or flow models. In this paper, we propose to leverage geometric consistency as additional supervisory signals. Our core idea is that for rigid regions we can use the predicted scene depth and camera motion to synthesize 2D optical flow by backprojecting the induced 3D scene flow. The discrepancy between the rigid flow (from depth prediction and camera motion) and the estimated flow (from optical flow model) allows us to impose a cross-task consistency loss. While all the networks are jointly optimized during training, they can be applied independently at test time. Extensive experiments demonstrate that our depth and flow models compare favorably with state-of-the-art unsupervised methods.
Graph Distillation for Action Detection with Privileged Modalities
Jul 27, 2018
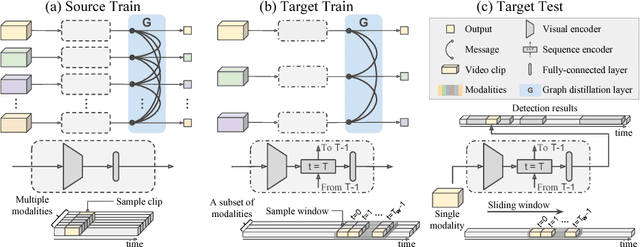
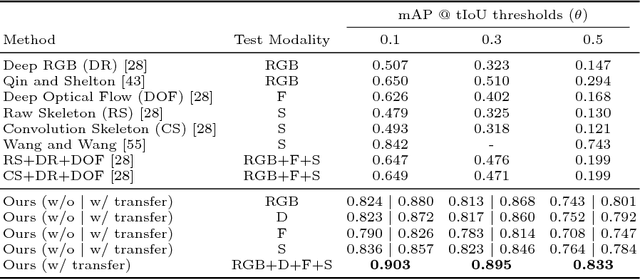
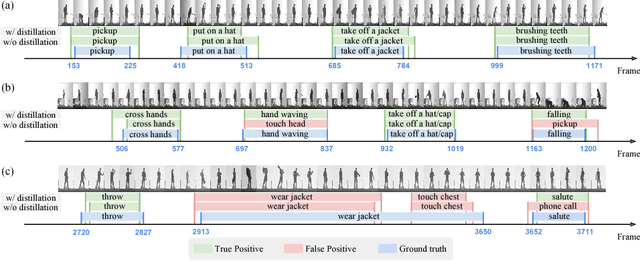
We propose a technique that tackles action detection in multimodal videos under a realistic and challenging condition in which only limited training data and partially observed modalities are available. Common methods in transfer learning do not take advantage of the extra modalities potentially available in the source domain. On the other hand, previous work on multimodal learning only focuses on a single domain or task and does not handle the modality discrepancy between training and testing. In this work, we propose a method termed graph distillation that incorporates rich privileged information from a large-scale multimodal dataset in the source domain, and improves the learning in the target domain where training data and modalities are scarce. We evaluate our approach on action classification and detection tasks in multimodal videos, and show that our model outperforms the state-of-the-art by a large margin on the NTU RGB+D and PKU-MMD benchmarks. The code is released at http://alan.vision/eccv18_graph/.
Towards Vision-Based Smart Hospitals: A System for Tracking and Monitoring Hand Hygiene Compliance
Apr 24, 2018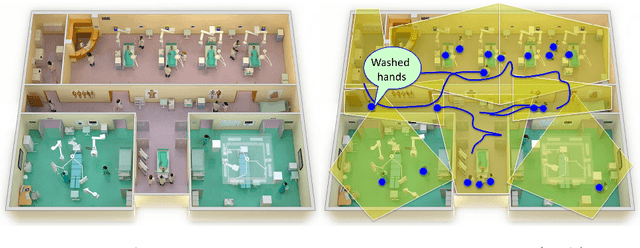
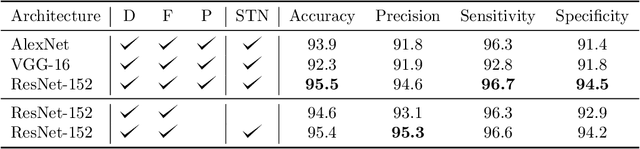


One in twenty-five patients admitted to a hospital will suffer from a hospital acquired infection. If we can intelligently track healthcare staff, patients, and visitors, we can better understand the sources of such infections. We envision a smart hospital capable of increasing operational efficiency and improving patient care with less spending. In this paper, we propose a non-intrusive vision-based system for tracking people's activity in hospitals. We evaluate our method for the problem of measuring hand hygiene compliance. Empirically, our method outperforms existing solutions such as proximity-based techniques and covert in-person observational studies. We present intuitive, qualitative results that analyze human movement patterns and conduct spatial analytics which convey our method's interpretability. This work is a step towards a computer-vision based smart hospital and demonstrates promising results for reducing hospital acquired infections.
* Machine Learning for Healthcare Conference (MLHC)
Label Efficient Learning of Transferable Representations across Domains and Tasks
Nov 30, 2017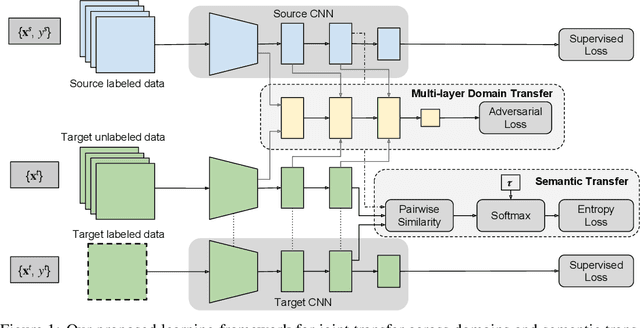
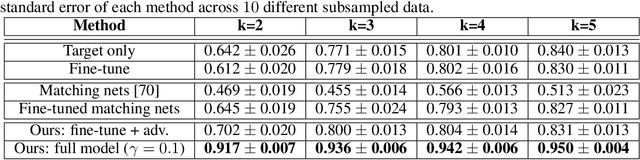

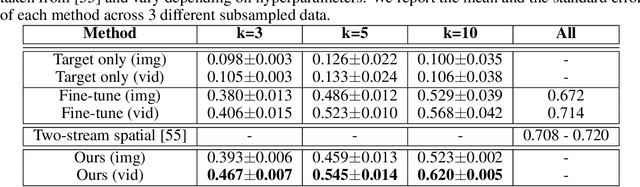
We propose a framework that learns a representation transferable across different domains and tasks in a label efficient manner. Our approach battles domain shift with a domain adversarial loss, and generalizes the embedding to novel task using a metric learning-based approach. Our model is simultaneously optimized on labeled source data and unlabeled or sparsely labeled data in the target domain. Our method shows compelling results on novel classes within a new domain even when only a few labeled examples per class are available, outperforming the prevalent fine-tuning approach. In addition, we demonstrate the effectiveness of our framework on the transfer learning task from image object recognition to video action recognition.
Unsupervised Learning of Long-Term Motion Dynamics for Videos
Apr 11, 2017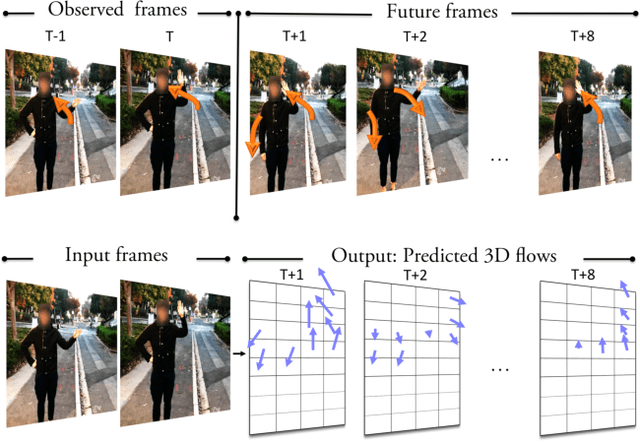
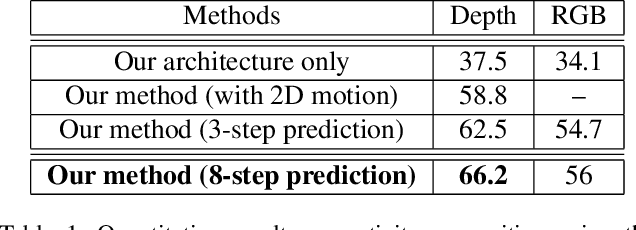
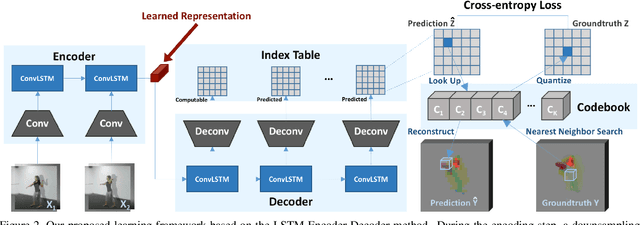
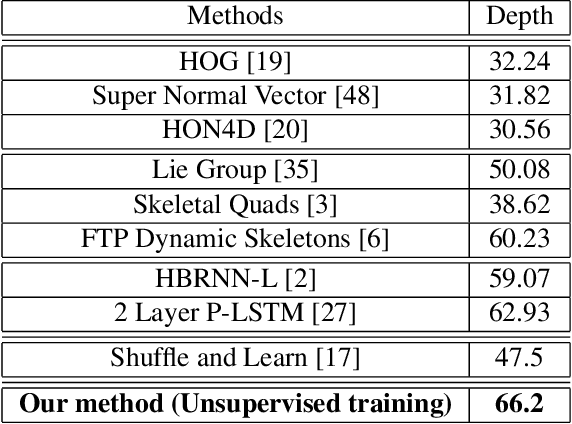
We present an unsupervised representation learning approach that compactly encodes the motion dependencies in videos. Given a pair of images from a video clip, our framework learns to predict the long-term 3D motions. To reduce the complexity of the learning framework, we propose to describe the motion as a sequence of atomic 3D flows computed with RGB-D modality. We use a Recurrent Neural Network based Encoder-Decoder framework to predict these sequences of flows. We argue that in order for the decoder to reconstruct these sequences, the encoder must learn a robust video representation that captures long-term motion dependencies and spatial-temporal relations. We demonstrate the effectiveness of our learned temporal representations on activity classification across multiple modalities and datasets such as NTU RGB+D and MSR Daily Activity 3D. Our framework is generic to any input modality, i.e., RGB, Depth, and RGB-D videos.