 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDF-Net: Unsupervised Joint Learning of Depth and Flow using Cross-Task Consistency
Paper and Code
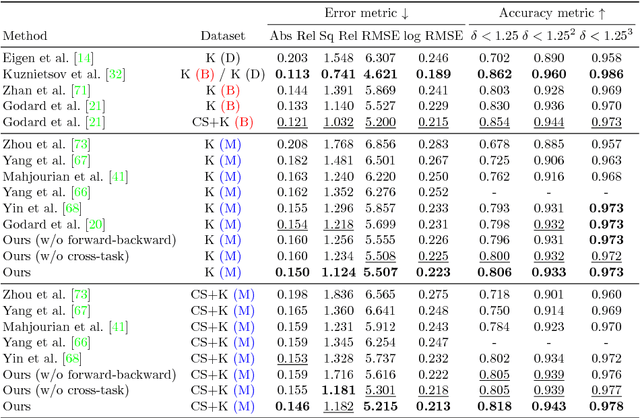


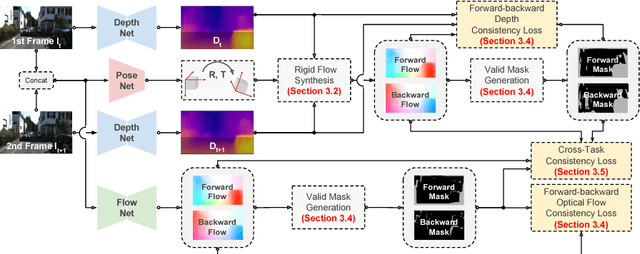
We present an unsupervised learning framework for simultaneously training single-view depth prediction and optical flow estimation models using unlabeled video sequences. Existing unsupervised methods often exploit brightness constancy and spatial smoothness priors to train depth or flow models. In this paper, we propose to leverage geometric consistency as additional supervisory signals. Our core idea is that for rigid regions we can use the predicted scene depth and camera motion to synthesize 2D optical flow by backprojecting the induced 3D scene flow. The discrepancy between the rigid flow (from depth prediction and camera motion) and the estimated flow (from optical flow model) allows us to impose a cross-task consistency loss. While all the networks are jointly optimized during training, they can be applied independently at test time. Extensive experiments demonstrate that our depth and flow models compare favorably with state-of-the-art unsupervised methods.