 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph Distillation for Action Detection with Privileged Modalities
Paper and Code
Jul 27, 2018
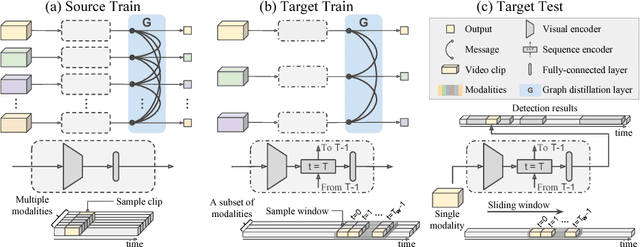
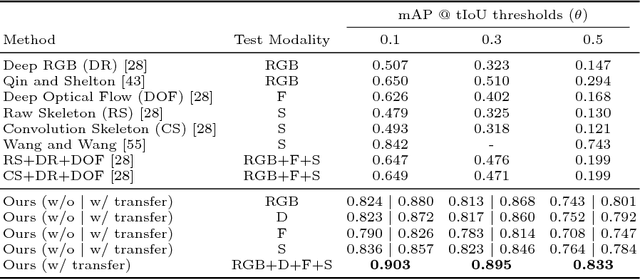
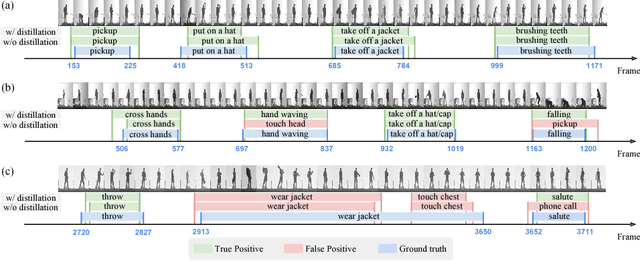
We propose a technique that tackles action detection in multimodal videos under a realistic and challenging condition in which only limited training data and partially observed modalities are available. Common methods in transfer learning do not take advantage of the extra modalities potentially available in the source domain. On the other hand, previous work on multimodal learning only focuses on a single domain or task and does not handle the modality discrepancy between training and testing. In this work, we propose a method termed graph distillation that incorporates rich privileged information from a large-scale multimodal dataset in the source domain, and improves the learning in the target domain where training data and modalities are scarce. We evaluate our approach on action classification and detection tasks in multimodal videos, and show that our model outperforms the state-of-the-art by a large margin on the NTU RGB+D and PKU-MMD benchmarks. The code is released at http://alan.vision/eccv18_graph/.