 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeH2LooP Spark Preview: Continual Pretraining of Large Language Models for Low-Level Embedded Systems Code
Mar 11, 2026Large language models (LLMs) demonstrate strong code generation abilities in general-purpose programming languages but remain limited in specialized domains such as low-level embedded systems programming. This domain involves hardware register manipulation, vendor-specific SDKs, real-time operating system APIs, and hardware abstraction layers that are underrepresented in standard pretraining corpora. We introduce H2LooP Spark Preview, a continual pretraining (CPT) pipeline that adapts the OLMo-3-7B-a fully open language model to the embedded systems domain using BF16 LoRA with rank-stabilized scaling on 8 NVIDIA H100 GPUs. Our training corpus is constructed from repository-datasheet pairs covering 100B tokens of raw embedded systems data across 117 manufacturers, processed using the hierarchical datasheet-to-code mapping approach proposed in SpecMap (Nipane et al., 2026). The resulting curated dataset split contains 23.5B tokens across 13 embedded domains. Continual pretraining with high-rank LoRA (r=512) yields substantial gains, reducing in-domain perplexity by 70.4% and held-out repository perplexity by 66.1%. On generative code completion benchmarks spanning 13 embedded domains, our 7B model outperforms Claude Opus 4.6 and Qwen3-Coder-30B on 8 categories in token accuracy, showing that targeted continual pretraining enables smaller open-weight models to rival frontier systems on specialized technical tasks. We release the production training checkpoint on Huggingface as an open-source artifact.
SpecMap: Hierarchical LLM Agent for Datasheet-to-Code Traceability Link Recovery in Systems Engineering
Jan 16, 2026Establishing precise traceability between embedded systems datasheets and their corresponding code implementations remains a fundamental challenge in systems engineering, particularly for low-level software where manual mapping between specification documents and large code repositories is infeasible. Existing Traceability Link Recovery approaches primarily rely on lexical similarity and information retrieval techniques, which struggle to capture the semantic, structural, and symbol level relationships prevalent in embedded systems software. We present a hierarchical datasheet-to-code mapping methodology that employs large language models for semantic analysis while explicitly structuring the traceability process across multiple abstraction levels. Rather than performing direct specification-to-code matching, the proposed approach progressively narrows the search space through repository-level structure inference, file-level relevance estimation, and fine-grained symbollevel alignment. The method extends beyond function-centric mapping by explicitly covering macros, structs, constants, configuration parameters, and register definitions commonly found in systems-level C/C++ codebases. We evaluate the approach on multiple open-source embedded systems repositories using manually curated datasheet-to-code ground truth. Experimental results show substantial improvements over traditional information-retrieval-based baselines, achieving up to 73.3% file mapping accuracy. We significantly reduce computational overhead, lowering total LLM token consumption by 84% and end-to-end runtime by approximately 80%. This methodology supports automated analysis of large embedded software systems and enables downstream applications such as training data generation for systems-aware machine learning models, standards compliance verification, and large-scale specification coverage analysis.
Improving Retrieval in Sponsored Search by Leveraging Query Context Signals
Jul 19, 2024



Accurately retrieving relevant bid keywords for user queries is critical in Sponsored Search but remains challenging, particularly for short, ambiguous queries. Existing dense and generative retrieval models often fail to capture nuanced user intent in these cases. To address this, we propose an approach to enhance query understanding by augmenting queries with rich contextual signals derived from web search results and large language models, stored in an online cache. Specifically, we use web search titles and snippets to ground queries in real-world information and utilize GPT-4 to generate query rewrites and explanations that clarify user intent. These signals are efficiently integrated through a Fusion-in-Decoder based Unity architecture, enabling both dense and generative retrieval with serving costs on par with traditional context-free models. To address scenarios where context is unavailable in the cache, we introduce context glancing, a curriculum learning strategy that improves model robustness and performance even without contextual signals during inference. Extensive offline experiments demonstrate that our context-aware approach substantially outperforms context-free models. Furthermore, online A/B testing on a prominent search engine across 160+ countries shows significant improvements in user engagement and revenue.
Scaling the Vocabulary of Non-autoregressive Models for Efficient Generative Retrieval
Jun 10, 2024Generative Retrieval introduces a new approach to Information Retrieval by reframing it as a constrained generation task, leveraging recent advancements in Autoregressive (AR) language models. However, AR-based Generative Retrieval methods suffer from high inference latency and cost compared to traditional dense retrieval techniques, limiting their practical applicability. This paper investigates fully Non-autoregressive (NAR) language models as a more efficient alternative for generative retrieval. While standard NAR models alleviate latency and cost concerns, they exhibit a significant drop in retrieval performance (compared to AR models) due to their inability to capture dependencies between target tokens. To address this, we question the conventional choice of limiting the target token space to solely words or sub-words. We propose PIXAR, a novel approach that expands the target vocabulary of NAR models to include multi-word entities and common phrases (up to 5 million tokens), thereby reducing token dependencies. PIXAR employs inference optimization strategies to maintain low inference latency despite the significantly larger vocabulary. Our results demonstrate that PIXAR achieves a relative improvement of 31.0% in MRR@10 on MS MARCO and 23.2% in Hits@5 on Natural Questions compared to standard NAR models with similar latency and cost. Furthermore, online A/B experiments on a large commercial search engine show that PIXAR increases ad clicks by 5.08% and revenue by 4.02%.
Forms of Understanding of XAI-Explanations
Nov 15, 2023

Explainability has become an important topic in computer science and artificial intelligence, leading to a subfield called Explainable Artificial Intelligence (XAI). The goal of providing or seeking explanations is to achieve (better) 'understanding' on the part of the explainee. However, what it means to 'understand' is still not clearly defined, and the concept itself is rarely the subject of scientific investigation. This conceptual article aims to present a model of forms of understanding in the context of XAI and beyond. From an interdisciplinary perspective bringing together computer science, linguistics, sociology, and psychology, a definition of understanding and its forms, assessment, and dynamics during the process of giving everyday explanations are explored. Two types of understanding are considered as possible outcomes of explanations, namely enabledness, 'knowing how' to do or decide something, and comprehension, 'knowing that' -- both in different degrees (from shallow to deep). Explanations regularly start with shallow understanding in a specific domain and can lead to deep comprehension and enabledness of the explanandum, which we see as a prerequisite for human users to gain agency. In this process, the increase of comprehension and enabledness are highly interdependent. Against the background of this systematization, special challenges of understanding in XAI are discussed.
Video and Synthetic MRI Pre-training of 3D Vision Architectures for Neuroimage Analysis
Sep 09, 2023Transfer learning represents a recent paradigm shift in the way we build artificial intelligence (AI) systems. In contrast to training task-specific models, transfer learning involves pre-training deep learning models on a large corpus of data and minimally fine-tuning them for adaptation to specific tasks. Even so, for 3D medical imaging tasks, we do not know if it is best to pre-train models on natural images, medical images, or even synthetically generated MRI scans or video data. To evaluate these alternatives, here we benchmarked vision transformers (ViTs) and convolutional neural networks (CNNs), initialized with varied upstream pre-training approaches. These methods were then adapted to three unique downstream neuroimaging tasks with a range of difficulty: Alzheimer's disease (AD) and Parkinson's disease (PD) classification, "brain age" prediction. Experimental tests led to the following key observations: 1. Pre-training improved performance across all tasks including a boost of 7.4% for AD classification and 4.6% for PD classification for the ViT and 19.1% for PD classification and reduction in brain age prediction error by 1.26 years for CNNs, 2. Pre-training on large-scale video or synthetic MRI data boosted performance of ViTs, 3. CNNs were robust in limited-data settings, and in-domain pretraining enhanced their performances, 4. Pre-training improved generalization to out-of-distribution datasets and sites. Overall, we benchmarked different vision architectures, revealing the value of pre-training them with emerging datasets for model initialization. The resulting pre-trained models can be adapted to a range of downstream neuroimaging tasks, even when training data for the target task is limited.
HEARTS: Multi-task Fusion of Dense Retrieval and Non-autoregressive Generation for Sponsored Search
Sep 13, 2022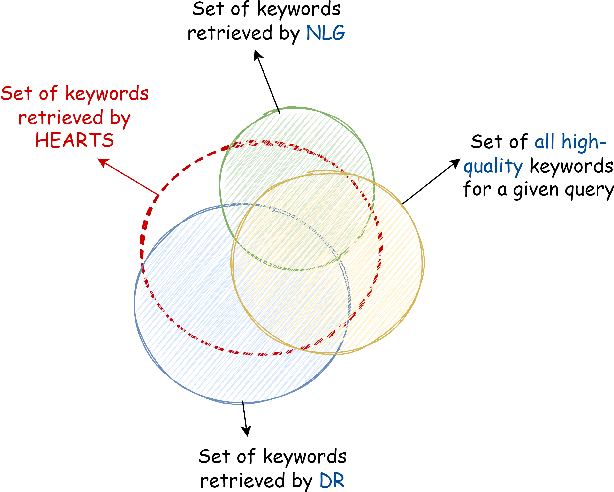

Matching user search queries with relevant keywords bid by advertisers in real-time is a crucial problem in sponsored search. In the literature, two broad set of approaches have been explored to solve this problem: (i) Dense Retrieval (DR) - learning dense vector representations for queries and bid keywords in a shared space, and (ii) Natural Language Generation (NLG) - learning to directly generate bid keywords given queries. In this work, we first conduct an empirical study of these two approaches and show that they offer complementary benefits that are additive. In particular, a large fraction of the keywords retrieved from NLG haven't been retrieved by DR and vice-versa. We then show that it is possible to effectively combine the advantages of these two approaches in one model. Specifically, we propose HEARTS: a novel multi-task fusion framework where we jointly optimize a shared encoder to perform both DR and non-autoregressive NLG. Through extensive experiments on search queries from over 30+ countries spanning 20+ languages, we show that HEARTS retrieves 40.3% more high-quality bid keywords than the baseline approaches with the same GPU compute. We also demonstrate that inferring on a single HEARTS model is as good as inferring on two different DR and NLG baseline models, with 2x the compute. Further, we show that DR models trained with the HEARTS objective are significantly better than those trained with the standard contrastive loss functions. Finally, we show that our HEARTS objective can be adopted to short-text retrieval tasks other than sponsored search and achieve significant performance gains.
NGAME: Negative Mining-aware Mini-batching for Extreme Classification
Jul 10, 2022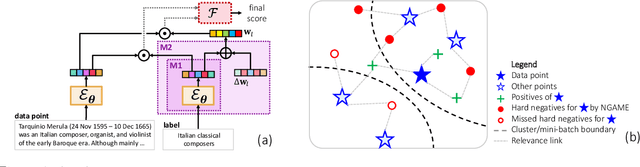
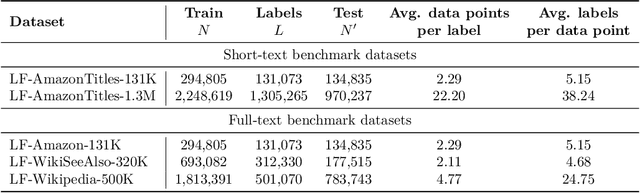
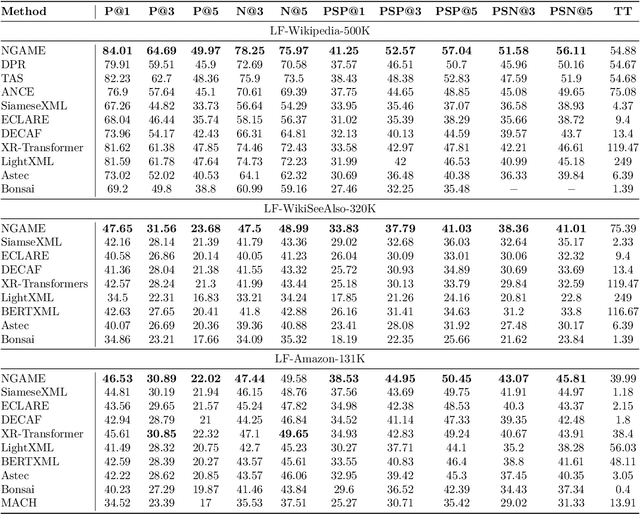
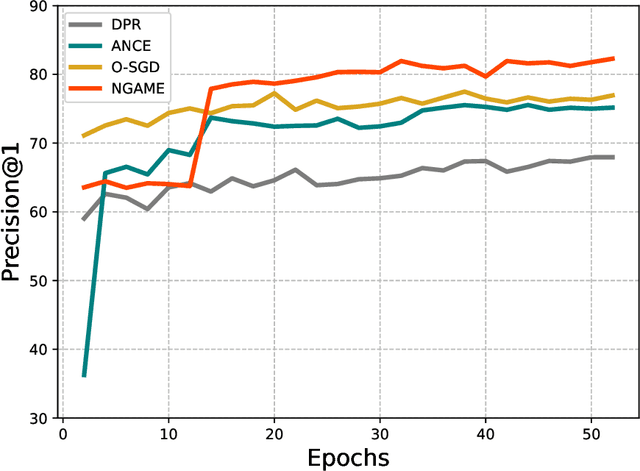
Extreme Classification (XC) seeks to tag data points with the most relevant subset of labels from an extremely large label set. Performing deep XC with dense, learnt representations for data points and labels has attracted much attention due to its superiority over earlier XC methods that used sparse, hand-crafted features. Negative mining techniques have emerged as a critical component of all deep XC methods that allow them to scale to millions of labels. However, despite recent advances, training deep XC models with large encoder architectures such as transformers remains challenging. This paper identifies that memory overheads of popular negative mining techniques often force mini-batch sizes to remain small and slow training down. In response, this paper introduces NGAME, a light-weight mini-batch creation technique that offers provably accurate in-batch negative samples. This allows training with larger mini-batches offering significantly faster convergence and higher accuracies than existing negative sampling techniques. NGAME was found to be up to 16% more accurate than state-of-the-art methods on a wide array of benchmark datasets for extreme classification, as well as 3% more accurate at retrieving search engine queries in response to a user webpage visit to show personalized ads. In live A/B tests on a popular search engine, NGAME yielded up to 23% gains in click-through-rates.
Generalize then Adapt: Source-Free Domain Adaptive Semantic Segmentation
Aug 25, 2021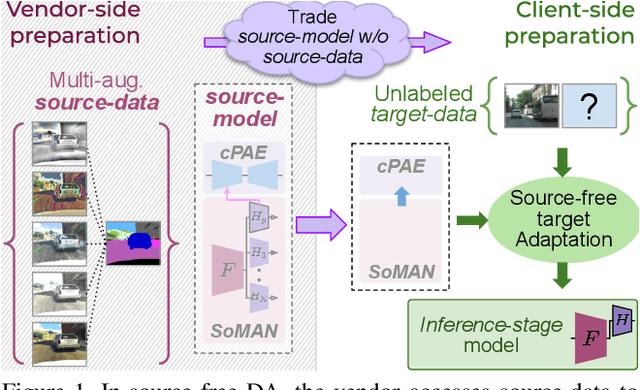
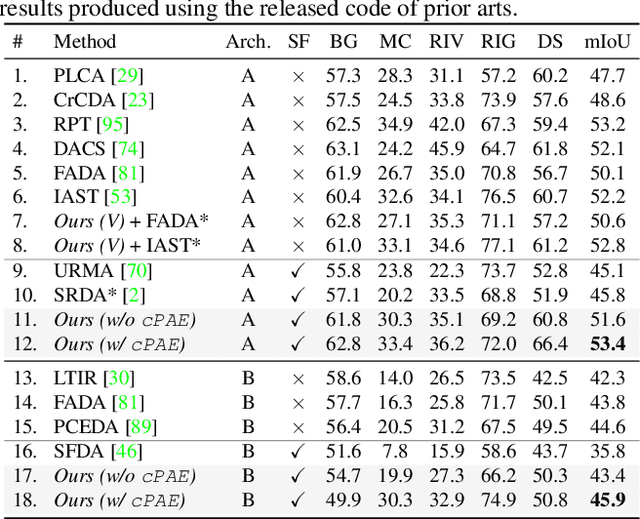

Unsupervised domain adaptation (DA) has gained substantial interest in semantic segmentation. However, almost all prior arts assume concurrent access to both labeled source and unlabeled target, making them unsuitable for scenarios demanding source-free adaptation. In this work, we enable source-free DA by partitioning the task into two: a) source-only domain generalization and b) source-free target adaptation. Towards the former, we provide theoretical insights to develop a multi-head framework trained with a virtually extended multi-source dataset, aiming to balance generalization and specificity. Towards the latter, we utilize the multi-head framework to extract reliable target pseudo-labels for self-training. Additionally, we introduce a novel conditional prior-enforcing auto-encoder that discourages spatial irregularities, thereby enhancing the pseudo-label quality. Experiments on the standard GTA5-to-Cityscapes and SYNTHIA-to-Cityscapes benchmarks show our superiority even against the non-source-free prior-arts. Further, we show our compatibility with online adaptation enabling deployment in a sequentially changing environment.
Diversity driven Query Rewriting in Search Advertising
Jun 07, 2021

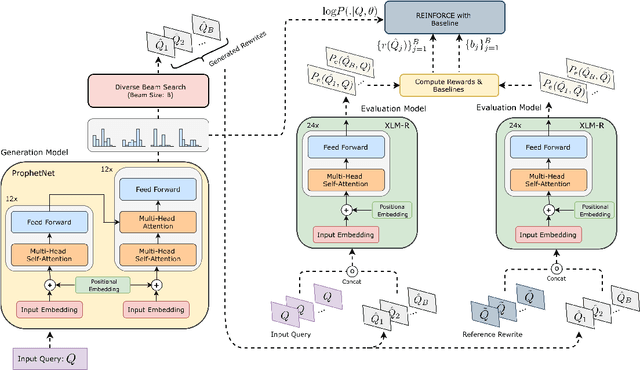
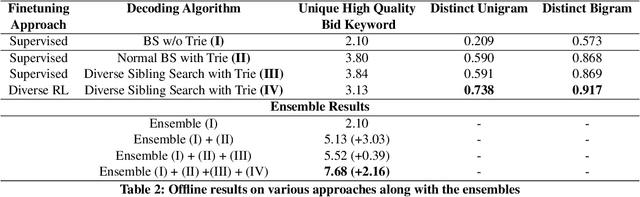
Retrieving keywords (bidwords) with the same intent as query, referred to as close variant keywords, is of prime importance for effective targeted search advertising. For head and torso search queries, sponsored search engines use a huge repository of same intent queries and keywords, mined ahead of time. Online, this repository is used to rewrite the query and then lookup the rewrite in a repository of bid keywords contributing to significant revenue. Recently generative retrieval models have been shown to be effective at the task of generating such query rewrites. We observe two main limitations of such generative models. First, rewrites generated by these models exhibit low lexical diversity, and hence the rewrites fail to retrieve relevant keywords that have diverse linguistic variations. Second, there is a misalignment between the training objective - the likelihood of training data, v/s what we desire - improved quality and coverage of rewrites. In this work, we introduce CLOVER, a framework to generate both high-quality and diverse rewrites by optimizing for human assessment of rewrite quality using our diversity-driven reinforcement learning algorithm. We use an evaluation model, trained to predict human judgments, as the reward function to finetune the generation policy. We empirically show the effectiveness of our proposed approach through offline experiments on search queries across geographies spanning three major languages. We also perform online A/B experiments on Bing, a large commercial search engine, which shows (i) better user engagement with an average increase in clicks by 12.83% accompanied with an average defect reduction by 13.97%, and (ii) improved revenue by 21.29%.