 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Imputation for Alzheimer's Disease Classification
Jan 28, 2026Deep learning has been successful in predicting neurodegenerative disorders, such as Alzheimer's disease, from magnetic resonance imaging (MRI). Combining multiple imaging modalities, such as T1-weighted (T1) and diffusion-weighted imaging (DWI) scans, can increase diagnostic performance. However, complete multimodal datasets are not always available. We use a conditional denoising diffusion probabilistic model to impute missing DWI scans from T1 scans. We perform extensive experiments to evaluate whether such imputation improves the accuracy of uni-modal and bi-modal deep learning models for 3-way Alzheimer's disease classification-cognitively normal, mild cognitive impairment, and Alzheimer's disease. We observe improvements in several metrics, particularly those sensitive to minority classes, for several imputation configurations.
Diffusion Bridge Models for 3D Medical Image Translation
Apr 21, 2025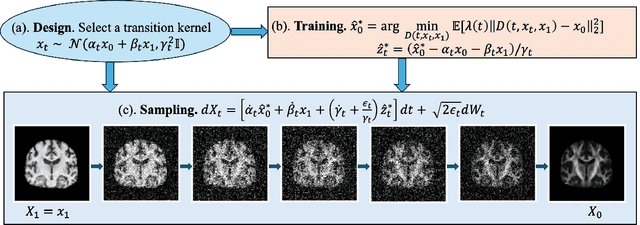
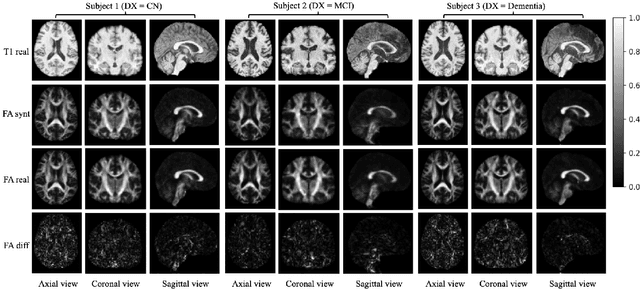


Diffusion tensor imaging (DTI) provides crucial insights into the microstructure of the human brain, but it can be time-consuming to acquire compared to more readily available T1-weighted (T1w) magnetic resonance imaging (MRI). To address this challenge, we propose a diffusion bridge model for 3D brain image translation between T1w MRI and DTI modalities. Our model learns to generate high-quality DTI fractional anisotropy (FA) images from T1w images and vice versa, enabling cross-modality data augmentation and reducing the need for extensive DTI acquisition. We evaluate our approach using perceptual similarity, pixel-level agreement, and distributional consistency metrics, demonstrating strong performance in capturing anatomical structures and preserving information on white matter integrity. The practical utility of the synthetic data is validated through sex classification and Alzheimer's disease classification tasks, where the generated images achieve comparable performance to real data. Our diffusion bridge model offers a promising solution for improving neuroimaging datasets and supporting clinical decision-making, with the potential to significantly impact neuroimaging research and clinical practice.
DenseNet and Support Vector Machine classifications of major depressive disorder using vertex-wise cortical features
Nov 18, 2023



Major depressive disorder (MDD) is a complex psychiatric disorder that affects the lives of hundreds of millions of individuals around the globe. Even today, researchers debate if morphological alterations in the brain are linked to MDD, likely due to the heterogeneity of this disorder. The application of deep learning tools to neuroimaging data, capable of capturing complex non-linear patterns, has the potential to provide diagnostic and predictive biomarkers for MDD. However, previous attempts to demarcate MDD patients and healthy controls (HC) based on segmented cortical features via linear machine learning approaches have reported low accuracies. In this study, we used globally representative data from the ENIGMA-MDD working group containing an extensive sample of people with MDD (N=2,772) and HC (N=4,240), which allows a comprehensive analysis with generalizable results. Based on the hypothesis that integration of vertex-wise cortical features can improve classification performance, we evaluated the classification of a DenseNet and a Support Vector Machine (SVM), with the expectation that the former would outperform the latter. As we analyzed a multi-site sample, we additionally applied the ComBat harmonization tool to remove potential nuisance effects of site. We found that both classifiers exhibited close to chance performance (balanced accuracy DenseNet: 51%; SVM: 53%), when estimated on unseen sites. Slightly higher classification performance (balanced accuracy DenseNet: 58%; SVM: 55%) was found when the cross-validation folds contained subjects from all sites, indicating site effect. In conclusion, the integration of vertex-wise morphometric features and the use of the non-linear classifier did not lead to the differentiability between MDD and HC. Our results support the notion that MDD classification on this combination of features and classifiers is unfeasible.
Video and Synthetic MRI Pre-training of 3D Vision Architectures for Neuroimage Analysis
Sep 09, 2023Transfer learning represents a recent paradigm shift in the way we build artificial intelligence (AI) systems. In contrast to training task-specific models, transfer learning involves pre-training deep learning models on a large corpus of data and minimally fine-tuning them for adaptation to specific tasks. Even so, for 3D medical imaging tasks, we do not know if it is best to pre-train models on natural images, medical images, or even synthetically generated MRI scans or video data. To evaluate these alternatives, here we benchmarked vision transformers (ViTs) and convolutional neural networks (CNNs), initialized with varied upstream pre-training approaches. These methods were then adapted to three unique downstream neuroimaging tasks with a range of difficulty: Alzheimer's disease (AD) and Parkinson's disease (PD) classification, "brain age" prediction. Experimental tests led to the following key observations: 1. Pre-training improved performance across all tasks including a boost of 7.4% for AD classification and 4.6% for PD classification for the ViT and 19.1% for PD classification and reduction in brain age prediction error by 1.26 years for CNNs, 2. Pre-training on large-scale video or synthetic MRI data boosted performance of ViTs, 3. CNNs were robust in limited-data settings, and in-domain pretraining enhanced their performances, 4. Pre-training improved generalization to out-of-distribution datasets and sites. Overall, we benchmarked different vision architectures, revealing the value of pre-training them with emerging datasets for model initialization. The resulting pre-trained models can be adapted to a range of downstream neuroimaging tasks, even when training data for the target task is limited.
Efficiently Training Vision Transformers on Structural MRI Scans for Alzheimer's Disease Detection
Mar 14, 2023



Neuroimaging of large populations is valuable to identify factors that promote or resist brain disease, and to assist diagnosis, subtyping, and prognosis. Data-driven models such as convolutional neural networks (CNNs) have increasingly been applied to brain images to perform diagnostic and prognostic tasks by learning robust features. Vision transformers (ViT) - a new class of deep learning architectures - have emerged in recent years as an alternative to CNNs for several computer vision applications. Here we tested variants of the ViT architecture for a range of desired neuroimaging downstream tasks based on difficulty, in this case for sex and Alzheimer's disease (AD) classification based on 3D brain MRI. In our experiments, two vision transformer architecture variants achieved an AUC of 0.987 for sex and 0.892 for AD classification, respectively. We independently evaluated our models on data from two benchmark AD datasets. We achieved a performance boost of 5% and 9-10% upon fine-tuning vision transformer models pre-trained on synthetic (generated by a latent diffusion model) and real MRI scans, respectively. Our main contributions include testing the effects of different ViT training strategies including pre-training, data augmentation and learning rate warm-ups followed by annealing, as pertaining to the neuroimaging domain. These techniques are essential for training ViT-like models for neuroimaging applications where training data is usually limited. We also analyzed the effect of the amount of training data utilized on the test-time performance of the ViT via data-model scaling curves.