 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo and Synthetic MRI Pre-training of 3D Vision Architectures for Neuroimage Analysis
Sep 09, 2023Transfer learning represents a recent paradigm shift in the way we build artificial intelligence (AI) systems. In contrast to training task-specific models, transfer learning involves pre-training deep learning models on a large corpus of data and minimally fine-tuning them for adaptation to specific tasks. Even so, for 3D medical imaging tasks, we do not know if it is best to pre-train models on natural images, medical images, or even synthetically generated MRI scans or video data. To evaluate these alternatives, here we benchmarked vision transformers (ViTs) and convolutional neural networks (CNNs), initialized with varied upstream pre-training approaches. These methods were then adapted to three unique downstream neuroimaging tasks with a range of difficulty: Alzheimer's disease (AD) and Parkinson's disease (PD) classification, "brain age" prediction. Experimental tests led to the following key observations: 1. Pre-training improved performance across all tasks including a boost of 7.4% for AD classification and 4.6% for PD classification for the ViT and 19.1% for PD classification and reduction in brain age prediction error by 1.26 years for CNNs, 2. Pre-training on large-scale video or synthetic MRI data boosted performance of ViTs, 3. CNNs were robust in limited-data settings, and in-domain pretraining enhanced their performances, 4. Pre-training improved generalization to out-of-distribution datasets and sites. Overall, we benchmarked different vision architectures, revealing the value of pre-training them with emerging datasets for model initialization. The resulting pre-trained models can be adapted to a range of downstream neuroimaging tasks, even when training data for the target task is limited.
Few-Shot Classification of Autism Spectrum Disorder using Site-Agnostic Meta-Learning and Brain MRI
Mar 14, 2023For machine learning applications in medical imaging, the availability of training data is often limited, which hampers the design of radiological classifiers for subtle conditions such as autism spectrum disorder (ASD). Transfer learning is one method to counter this problem of low training data regimes. Here we explore the use of meta-learning for very low data regimes in the context of having prior data from multiple sites - an approach we term site-agnostic meta-learning. Inspired by the effectiveness of meta-learning for optimizing a model across multiple tasks, here we propose a framework to adapt it to learn across multiple sites. We tested our meta-learning model for classifying ASD versus typically developing controls in 2,201 T1-weighted (T1-w) MRI scans collected from 38 imaging sites as part of Autism Brain Imaging Data Exchange (ABIDE) [age: 5.2-64.0 years]. The method was trained to find a good initialization state for our model that can quickly adapt to data from new unseen sites by fine-tuning on the limited data that is available. The proposed method achieved an ROC-AUC=0.857 on 370 scans from 7 unseen sites in ABIDE using a few-shot setting of 2-way 20-shot i.e., 20 training samples per site. Our results outperformed a transfer learning baseline by generalizing across a wider range of sites as well as other related prior work. We also tested our model in a zero-shot setting on an independent test site without any additional fine-tuning. Our experiments show the promise of the proposed site-agnostic meta-learning framework for challenging neuroimaging tasks involving multi-site heterogeneity with limited availability of training data.
Efficiently Training Vision Transformers on Structural MRI Scans for Alzheimer's Disease Detection
Mar 14, 2023



Neuroimaging of large populations is valuable to identify factors that promote or resist brain disease, and to assist diagnosis, subtyping, and prognosis. Data-driven models such as convolutional neural networks (CNNs) have increasingly been applied to brain images to perform diagnostic and prognostic tasks by learning robust features. Vision transformers (ViT) - a new class of deep learning architectures - have emerged in recent years as an alternative to CNNs for several computer vision applications. Here we tested variants of the ViT architecture for a range of desired neuroimaging downstream tasks based on difficulty, in this case for sex and Alzheimer's disease (AD) classification based on 3D brain MRI. In our experiments, two vision transformer architecture variants achieved an AUC of 0.987 for sex and 0.892 for AD classification, respectively. We independently evaluated our models on data from two benchmark AD datasets. We achieved a performance boost of 5% and 9-10% upon fine-tuning vision transformer models pre-trained on synthetic (generated by a latent diffusion model) and real MRI scans, respectively. Our main contributions include testing the effects of different ViT training strategies including pre-training, data augmentation and learning rate warm-ups followed by annealing, as pertaining to the neuroimaging domain. These techniques are essential for training ViT-like models for neuroimaging applications where training data is usually limited. We also analyzed the effect of the amount of training data utilized on the test-time performance of the ViT via data-model scaling curves.
Curriculum Based Multi-Task Learning for Parkinson's Disease Detection
Feb 27, 2023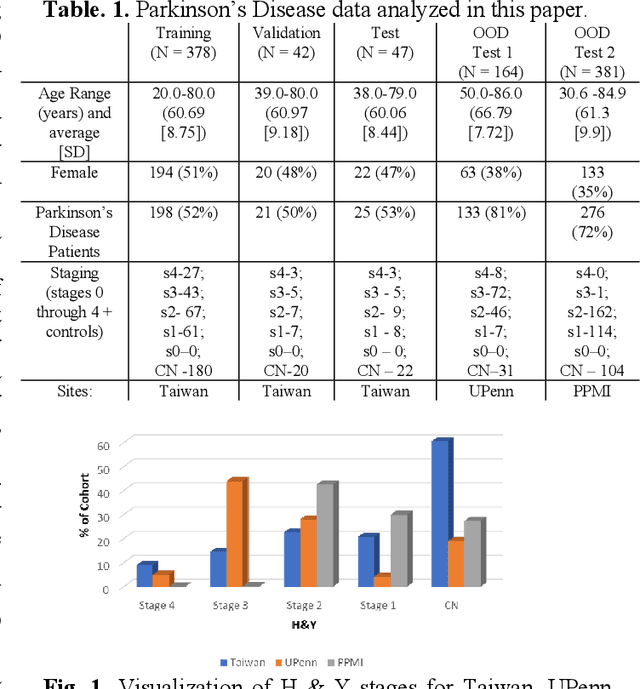
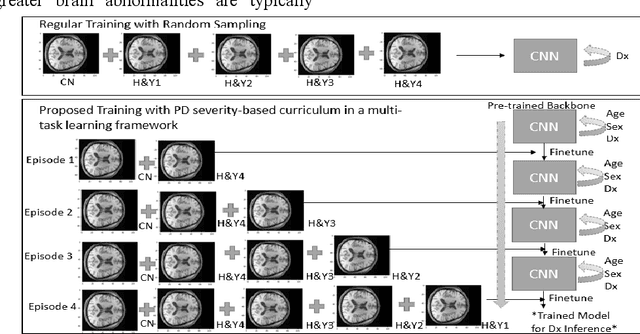
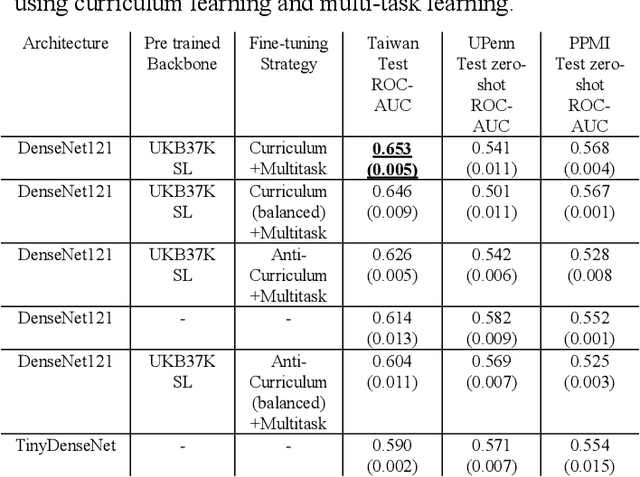
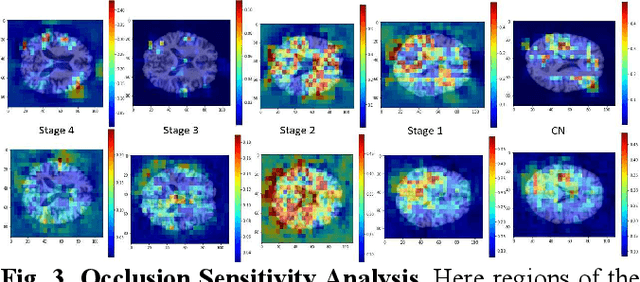
There is great interest in developing radiological classifiers for diagnosis, staging, and predictive modeling in progressive diseases such as Parkinson's disease (PD), a neurodegenerative disease that is difficult to detect in its early stages. Here we leverage severity-based meta-data on the stages of disease to define a curriculum for training a deep convolutional neural network (CNN). Typically, deep learning networks are trained by randomly selecting samples in each mini-batch. By contrast, curriculum learning is a training strategy that aims to boost classifier performance by starting with examples that are easier to classify. Here we define a curriculum to progressively increase the difficulty of the training data corresponding to the Hoehn and Yahr (H&Y) staging system for PD (total N=1,012; 653 PD patients, 359 controls; age range: 20.0-84.9 years). Even with our multi-task setting using pre-trained CNNs and transfer learning, PD classification based on T1-weighted (T1-w) MRI was challenging (ROC AUC: 0.59-0.65), but curriculum training boosted performance (by 3.9%) compared to our baseline model. Future work with multimodal imaging may further boost performance.