 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHARNESS-LM: A Three-Phase Training Recipe for Harnessing SLMs in Sponsored Search Retrieval
May 22, 2026In the competitive landscape of sponsored search, balancing retrieval quality with production latency is a critical challenge. While large retrieval models based on Small Language Models (SLMs) such as Qwen3-Embedding-4B/8B set strong upper bounds on public benchmarks, their deployment in high-throughput, latency-sensitive environments remains impractical. In this paper, we present HARNESS-LM (HLM), a three-phase training framework for transferring the capabilities of large-scale retrievers into compact, cost-efficient models. The approach comprises: (1) training a high-performance reference ("teacher") retriever by fine-tuning a billion-parameter-scale SLM; (2) aligning query representations via an L2 objective to distill knowledge into a sub-600M parameter student encoder; and (3) applying a final contrastive refinement stage to optimize the student for retrieval performance. We also present a comprehensive empirical study of key design choices, including alignment objectives, embedding dimensionality, model scale, architecture, and optimization strategies, to identify configurations that are most effective in production settings. On a real-world Bing Ads evaluation benchmark, HLM recovers over 98% of the reference retriever's precision across multiple settings, while delivering up to 27x lower online query-encoder latency and 20x higher throughput on NVIDIA A100 GPUs. Online A/B testing on Bing Ads further shows a +1% Revenue, +0.6% Impression, and +0.4% Click uplift over the current ensemble of retrievers running in production with the deployed 190M parameter model, clearly highlighting the practical efficacy of the HLM recipe in a real-world sponsored search setting.
Diversity driven Query Rewriting in Search Advertising
Jun 07, 2021

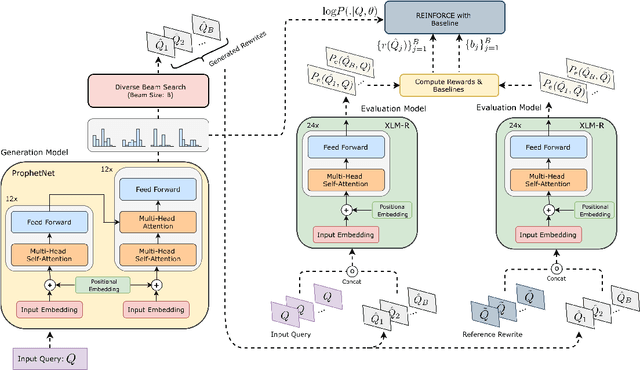
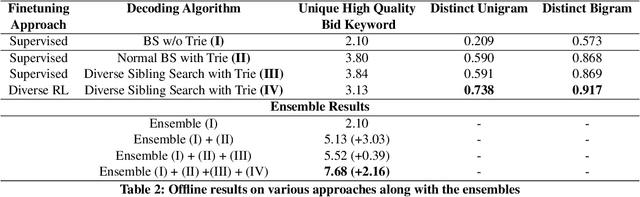
Retrieving keywords (bidwords) with the same intent as query, referred to as close variant keywords, is of prime importance for effective targeted search advertising. For head and torso search queries, sponsored search engines use a huge repository of same intent queries and keywords, mined ahead of time. Online, this repository is used to rewrite the query and then lookup the rewrite in a repository of bid keywords contributing to significant revenue. Recently generative retrieval models have been shown to be effective at the task of generating such query rewrites. We observe two main limitations of such generative models. First, rewrites generated by these models exhibit low lexical diversity, and hence the rewrites fail to retrieve relevant keywords that have diverse linguistic variations. Second, there is a misalignment between the training objective - the likelihood of training data, v/s what we desire - improved quality and coverage of rewrites. In this work, we introduce CLOVER, a framework to generate both high-quality and diverse rewrites by optimizing for human assessment of rewrite quality using our diversity-driven reinforcement learning algorithm. We use an evaluation model, trained to predict human judgments, as the reward function to finetune the generation policy. We empirically show the effectiveness of our proposed approach through offline experiments on search queries across geographies spanning three major languages. We also perform online A/B experiments on Bing, a large commercial search engine, which shows (i) better user engagement with an average increase in clicks by 12.83% accompanied with an average defect reduction by 13.97%, and (ii) improved revenue by 21.29%.
Learning From Weights: A Cost-Sensitive Approach For Ad Retrieval
Dec 03, 2018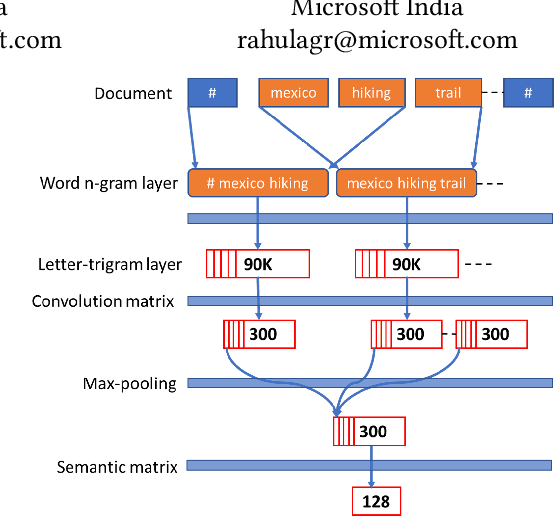
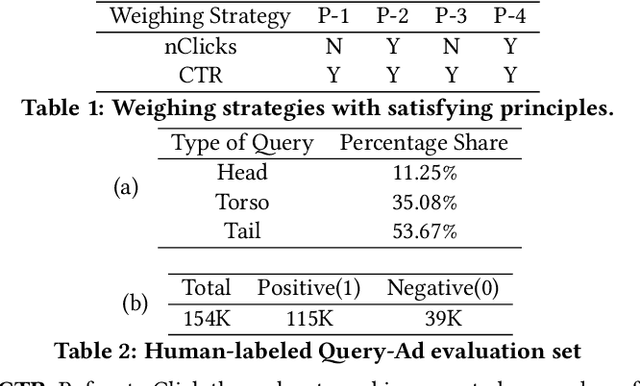
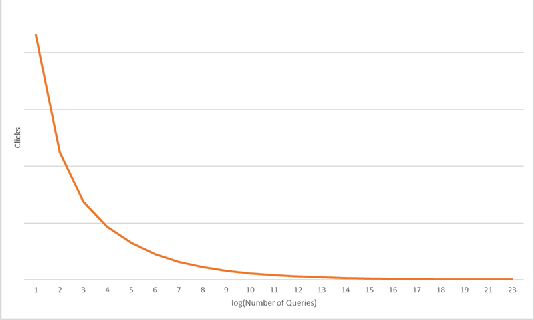
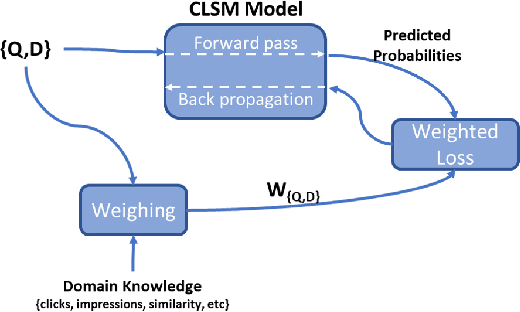
Retrieval models such as CLSM is trained on click-through data which treats each clicked query-document pair as equivalent. While training on click-through data is reasonable, this paper argues that it is sub-optimal because of its noisy and long-tail nature (especially for sponsored search). In this paper, we discuss the impact of incorporating or disregarding the long tail pairs in the training set. Also, we propose a weighing based strategy using which we can learn semantic representations for tail pairs without compromising the quality of retrieval. We conducted our experiments on Bing sponsored search and also on Amazon product recommendation to demonstrate that the methodology is domain agnostic. Online A/B testing on live search engine traffic showed improvements in clicks (11.8\% higher CTR) and as well as improvement in quality (8.2\% lower bounce rate) when compared to the unweighted model. We also conduct the experiment on Amazon Product Recommendation data where we see slight improvements in NDCG Scores calculated by retrieving among co-purchased product.