 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiLiftAeroML: High-Fidelity Computational Fluid Dynamics Dataset for High-Lift Aircraft Aerodynamics
May 19, 2026This paper describes the first-ever open-source high-fidelity CFD dataset of a high-lift aircraft for the purpose of AI surrogate model development. The dataset is composed of 1800 samples, arising from 180 geometry variants and 10 angles of attack for the high-lift NASA Common Research Model (CRM) geometry, used within the AIAA High-Lift Prediction Workshop series. One of the novelties of this dataset is the use of a GPU-accelerated high-fidelity explicit, wall-modeled LES approach for each simulation, using solution-adapted grids between 300M and 500M cells. This ensures the greatest possible accuracy given known challenges in steady-state RANS approaches for these portions of the flight envelope. The entire dataset (geometries, time-averaged volume and surface variables and integral forces) are available, free of charge with a permissive open-source license (CC-BY-4.0). By making this data publicly available, we aim to accelerate the research and development of AI surrogate modeling within the aerospace industry.
SPOT: Point Cloud Based Stereo Visual Place Recognition for Similar and Opposing Viewpoints
Apr 18, 2024Recognizing places from an opposing viewpoint during a return trip is a common experience for human drivers. However, the analogous robotics capability, visual place recognition (VPR) with limited field of view cameras under 180 degree rotations, has proven to be challenging to achieve. To address this problem, this paper presents Same Place Opposing Trajectory (SPOT), a technique for opposing viewpoint VPR that relies exclusively on structure estimated through stereo visual odometry (VO). The method extends recent advances in lidar descriptors and utilizes a novel double (similar and opposing) distance matrix sequence matching method. We evaluate SPOT on a publicly available dataset with 6.7-7.6 km routes driven in similar and opposing directions under various lighting conditions. The proposed algorithm demonstrates remarkable improvement over the state-of-the-art, achieving up to 91.7% recall at 100% precision in opposing viewpoint cases, while requiring less storage than all baselines tested and running faster than all but one. Moreover, the proposed method assumes no a priori knowledge of whether the viewpoint is similar or opposing, and also demonstrates competitive performance in similar viewpoint cases.
XGLUE: A New Benchmark Dataset for Cross-lingual Pre-training, Understanding and Generation
Apr 19, 2020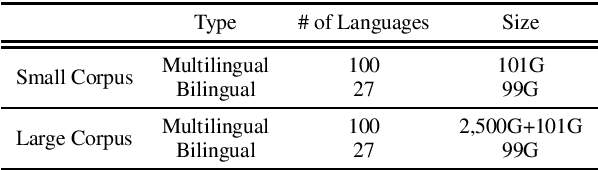
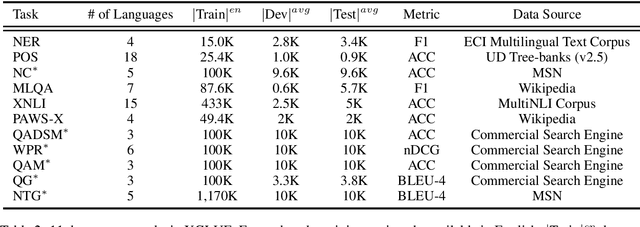
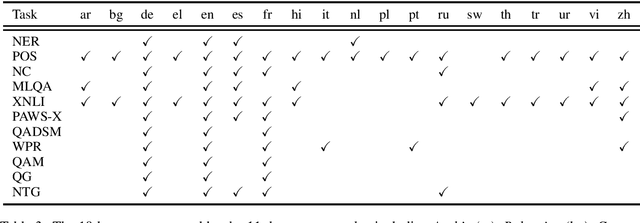
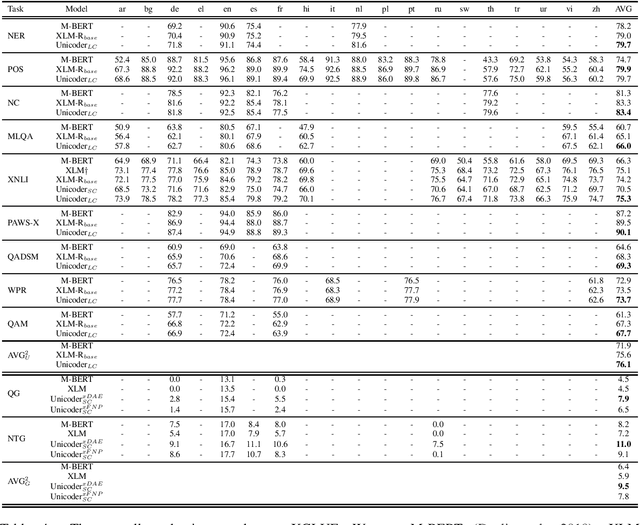
In this paper, we introduce XGLUE, a new benchmark dataset to train large-scale cross-lingual pre-trained models using multilingual and bilingual corpora, and evaluate their performance across a diverse set of cross-lingual tasks. Comparing to GLUE (Wang et al.,2019), which is labeled in English and includes natural language understanding tasks only, XGLUE has three main advantages: (1) it provides two corpora with different sizes for cross-lingual pre-training; (2) it provides 11 diversified tasks that cover both natural language understanding and generation scenarios; (3) for each task, it provides labeled data in multiple languages. We extend a recent cross-lingual pre-trained model Unicoder (Huang et al., 2019) to cover both understanding and generation tasks, which is evaluated on XGLUE as a strong baseline. We also evaluate the base versions (12-layer) of Multilingual BERT, XLM and XLM-R for comparison.
Learning From Weights: A Cost-Sensitive Approach For Ad Retrieval
Dec 03, 2018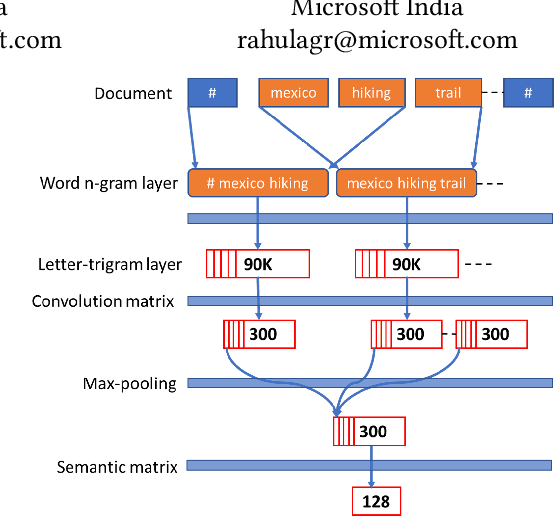
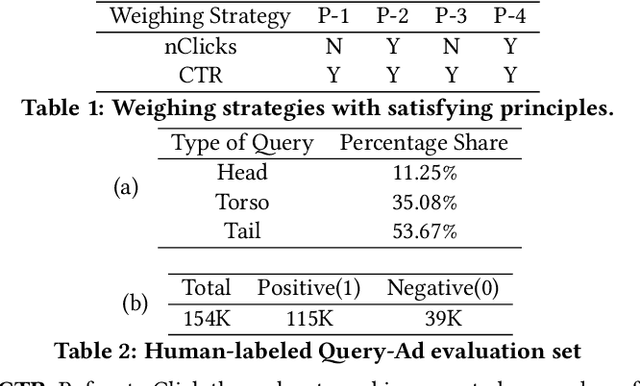
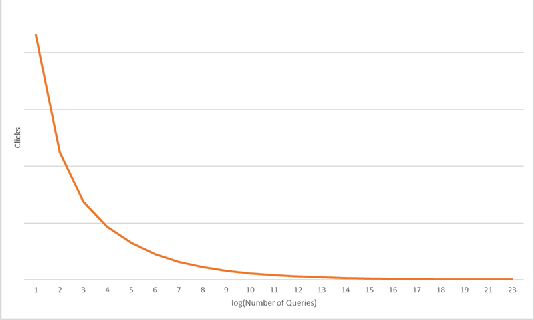
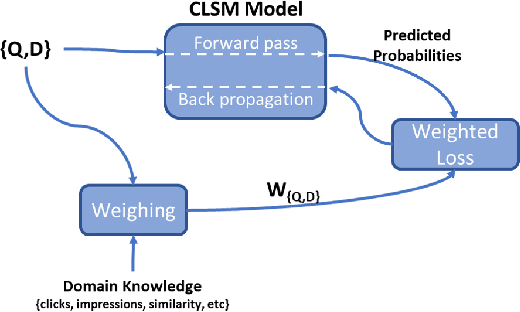
Retrieval models such as CLSM is trained on click-through data which treats each clicked query-document pair as equivalent. While training on click-through data is reasonable, this paper argues that it is sub-optimal because of its noisy and long-tail nature (especially for sponsored search). In this paper, we discuss the impact of incorporating or disregarding the long tail pairs in the training set. Also, we propose a weighing based strategy using which we can learn semantic representations for tail pairs without compromising the quality of retrieval. We conducted our experiments on Bing sponsored search and also on Amazon product recommendation to demonstrate that the methodology is domain agnostic. Online A/B testing on live search engine traffic showed improvements in clicks (11.8\% higher CTR) and as well as improvement in quality (8.2\% lower bounce rate) when compared to the unweighted model. We also conduct the experiment on Amazon Product Recommendation data where we see slight improvements in NDCG Scores calculated by retrieving among co-purchased product.