 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBookSQL: A Large Scale Text-to-SQL Dataset for Accounting Domain
Jun 12, 2024



Several large-scale datasets (e.g., WikiSQL, Spider) for developing natural language interfaces to databases have recently been proposed. These datasets cover a wide breadth of domains but fall short on some essential domains, such as finance and accounting. Given that accounting databases are used worldwide, particularly by non-technical people, there is an imminent need to develop models that could help extract information from accounting databases via natural language queries. In this resource paper, we aim to fill this gap by proposing a new large-scale Text-to-SQL dataset for the accounting and financial domain: BookSQL. The dataset consists of 100k natural language queries-SQL pairs, and accounting databases of 1 million records. We experiment with and analyze existing state-of-the-art models (including GPT-4) for the Text-to-SQL task on BookSQL. We find significant performance gaps, thus pointing towards developing more focused models for this domain.
An Ensemble Approach to Personalized Real Time Predictive Writing for Experts
Aug 25, 2023


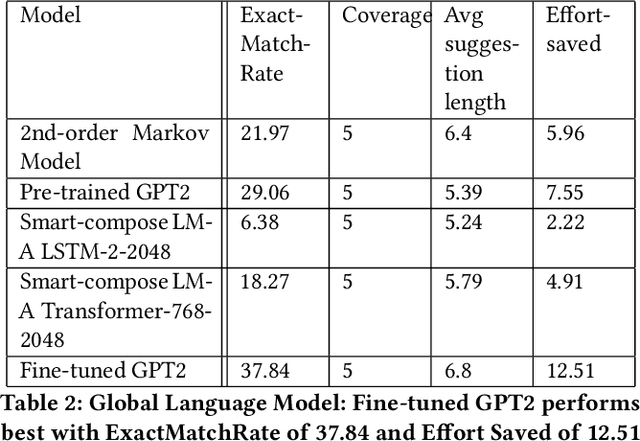
Completing a sentence, phrase or word after typing few words / characters is very helpful for Intuit financial experts, while taking notes or having a live chat with users, since they need to write complex financial concepts more efficiently and accurately many times in a day. In this paper, we tie together different approaches like large language models, traditional Markov Models and char level models to create an end-to-end system to provide personalised sentence/word auto-complete suggestions to experts, under strict latency constraints. Proposed system can auto-complete sentences, phrases or words while writing with personalisation and can be trained with very less data and resources with good efficiency. Our proposed system is not only efficient and personalized but also robust as it leverages multiple machine learning techniques along with transfer learning approach to fine tune large language model with Intuit specific data. This ensures that even in cases of rare or unusual phrases, the system can provide relevant auto-complete suggestions in near real time. Survey has showed that this system saves expert note-taking time and boosts expert confidence in their communication with teammates and clients. Since enabling this predictive writing feature for QBLive experts, more than a million keystrokes have been saved based on these suggestions. We have done comparative study for our ensemble choice. Moreover this feature can be integrated with any product which has writing facility within a very short period of time.
RICON: A ML framework for real-time and proactive intervention to prevent customer churn
Mar 30, 2022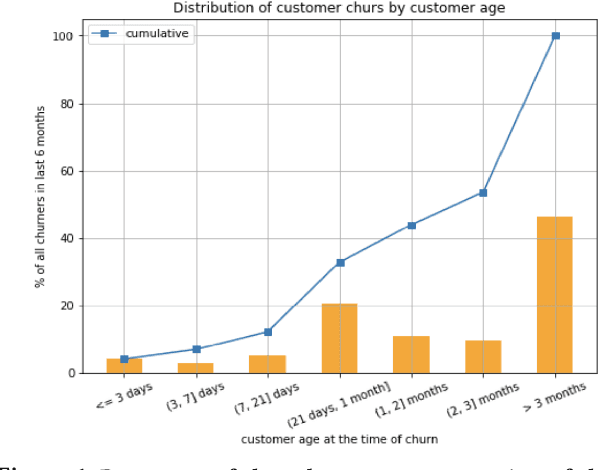
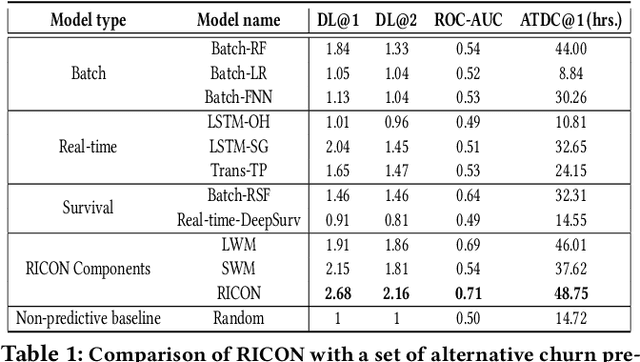
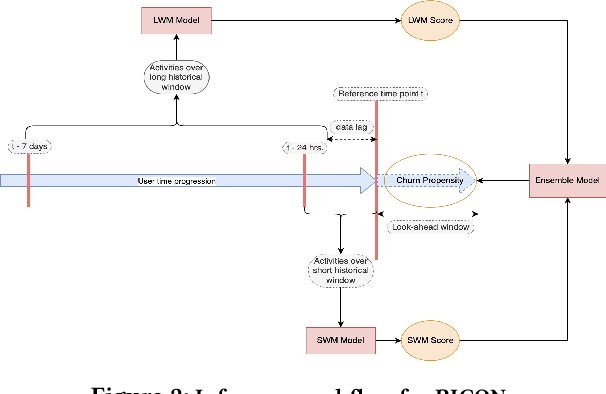
We consider the problem of churn prediction in real-time. Because of the batch mode of inference generation, the traditional methods can only support retention campaigns with offline interventions, e.g., test messages, emails or static in-product nudges. Other recent works in real-time churn predictions do not assess the cost to accuracy trade-off to deploy such models in production. In this paper we present RICON, a flexible, cost-effective and robust machine learning system to predict customer churn propensities in real-time using clickstream data. In addition to churn propensity prediction, RICON provides insights based on product usage intelligence. Through application on a real big data of QBO Advanced customers we showcase how RICON has achieved a top decile lift of 2.68 in the presence of strong class imbalance. Moreover, we execute an extensive comparative study to justify our modeling choices for RICON. Finally, we mention how RICON can be integrated with intervention platforms within Intuit to run large-scale retention campaigns with real-time in-product contextual helps.
Learning From Weights: A Cost-Sensitive Approach For Ad Retrieval
Dec 03, 2018
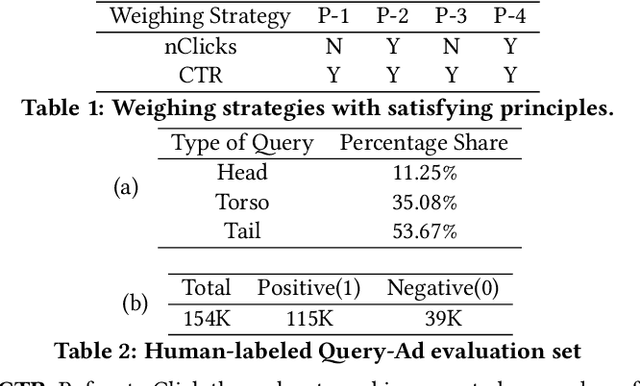
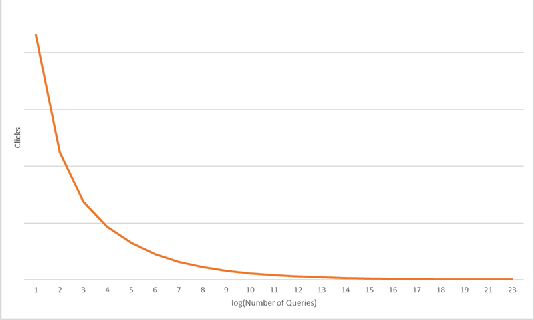
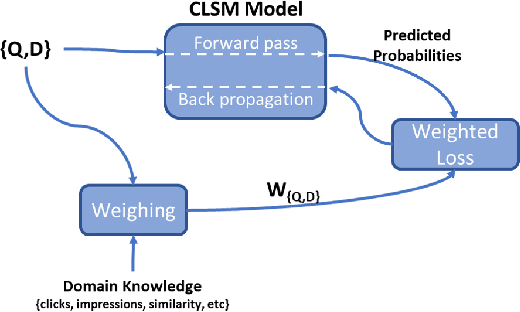
Retrieval models such as CLSM is trained on click-through data which treats each clicked query-document pair as equivalent. While training on click-through data is reasonable, this paper argues that it is sub-optimal because of its noisy and long-tail nature (especially for sponsored search). In this paper, we discuss the impact of incorporating or disregarding the long tail pairs in the training set. Also, we propose a weighing based strategy using which we can learn semantic representations for tail pairs without compromising the quality of retrieval. We conducted our experiments on Bing sponsored search and also on Amazon product recommendation to demonstrate that the methodology is domain agnostic. Online A/B testing on live search engine traffic showed improvements in clicks (11.8\% higher CTR) and as well as improvement in quality (8.2\% lower bounce rate) when compared to the unweighted model. We also conduct the experiment on Amazon Product Recommendation data where we see slight improvements in NDCG Scores calculated by retrieving among co-purchased product.