 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning From Weights: A Cost-Sensitive Approach For Ad Retrieval
Paper and Code
Dec 03, 2018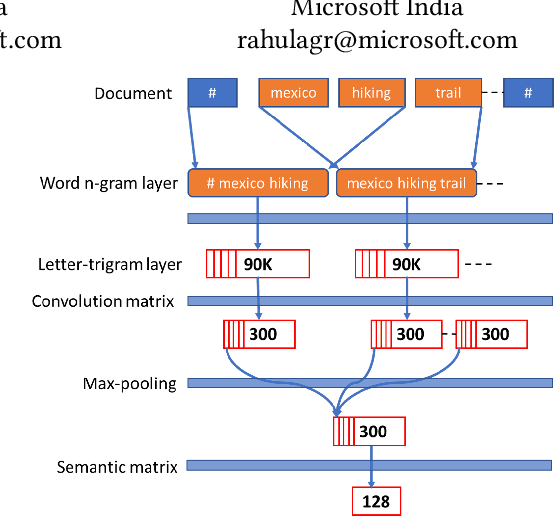
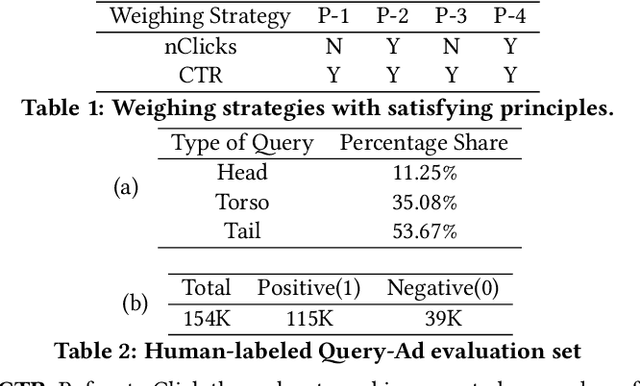
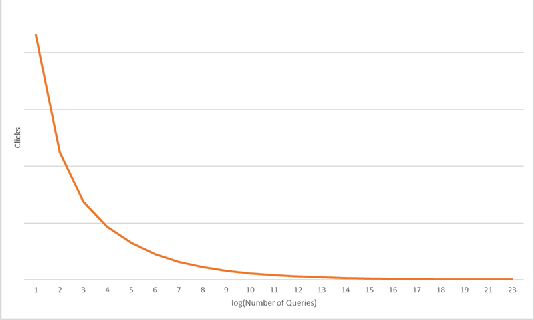
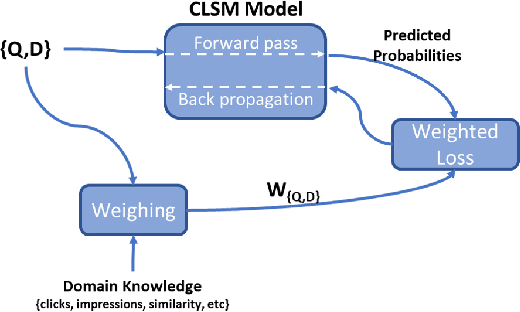
Retrieval models such as CLSM is trained on click-through data which treats each clicked query-document pair as equivalent. While training on click-through data is reasonable, this paper argues that it is sub-optimal because of its noisy and long-tail nature (especially for sponsored search). In this paper, we discuss the impact of incorporating or disregarding the long tail pairs in the training set. Also, we propose a weighing based strategy using which we can learn semantic representations for tail pairs without compromising the quality of retrieval. We conducted our experiments on Bing sponsored search and also on Amazon product recommendation to demonstrate that the methodology is domain agnostic. Online A/B testing on live search engine traffic showed improvements in clicks (11.8\% higher CTR) and as well as improvement in quality (8.2\% lower bounce rate) when compared to the unweighted model. We also conduct the experiment on Amazon Product Recommendation data where we see slight improvements in NDCG Scores calculated by retrieving among co-purchased product.