 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthetic Prefixes to Mitigate Bias in Real-Time Neural Query Autocomplete
Oct 02, 2025We introduce a data-centric approach for mitigating presentation bias in real-time neural query autocomplete systems through the use of synthetic prefixes. These prefixes are generated from complete user queries collected during regular search sessions where autocomplete was not active. This allows us to enrich the training data for learning to rank models with more diverse and less biased examples. This method addresses the inherent bias in engagement signals collected from live query autocomplete interactions, where model suggestions influence user behavior. Our neural ranker is optimized for real-time deployment under strict latency constraints and incorporates a rich set of features, including query popularity, seasonality, fuzzy match scores, and contextual signals such as department affinity, device type, and vertical alignment with previous user queries. To support efficient training, we introduce a task-specific simplification of the listwise loss, reducing computational complexity from $O(n^2)$ to $O(n)$ by leveraging the query autocomplete structure of having only one ground-truth selection per prefix. Deployed in a large-scale e-commerce setting, our system demonstrates statistically significant improvements in user engagement, as measured by mean reciprocal rank and related metrics. Our findings show that synthetic prefixes not only improve generalization but also provide a scalable path toward bias mitigation in other low-latency ranking tasks, including related searches and query recommendations.
A Survey of AI for Materials Science: Foundation Models, LLM Agents, Datasets, and Tools
Jun 25, 2025



Foundation models (FMs) are catalyzing a transformative shift in materials science (MatSci) by enabling scalable, general-purpose, and multimodal AI systems for scientific discovery. Unlike traditional machine learning models, which are typically narrow in scope and require task-specific engineering, FMs offer cross-domain generalization and exhibit emergent capabilities. Their versatility is especially well-suited to materials science, where research challenges span diverse data types and scales. This survey provides a comprehensive overview of foundation models, agentic systems, datasets, and computational tools supporting this growing field. We introduce a task-driven taxonomy encompassing six broad application areas: data extraction, interpretation and Q\&A; atomistic simulation; property prediction; materials structure, design and discovery; process planning, discovery, and optimization; and multiscale modeling. We discuss recent advances in both unimodal and multimodal FMs, as well as emerging large language model (LLM) agents. Furthermore, we review standardized datasets, open-source tools, and autonomous experimental platforms that collectively fuel the development and integration of FMs into research workflows. We assess the early successes of foundation models and identify persistent limitations, including challenges in generalizability, interpretability, data imbalance, safety concerns, and limited multimodal fusion. Finally, we articulate future research directions centered on scalable pretraining, continual learning, data governance, and trustworthiness.
Large Language Models Implicitly Learn to See and Hear Just By Reading
May 20, 2025This paper presents a fascinating find: By training an auto-regressive LLM model on text tokens, the text model inherently develops internally an ability to understand images and audio, thereby developing the ability to see and hear just by reading. Popular audio and visual LLM models fine-tune text LLM models to give text output conditioned on images and audio embeddings. On the other hand, our architecture takes in patches of images, audio waveforms or tokens as input. It gives us the embeddings or category labels typical of a classification pipeline. We show the generality of text weights in aiding audio classification for datasets FSD-50K and GTZAN. Further, we show this working for image classification on CIFAR-10 and Fashion-MNIST, as well on image patches. This pushes the notion of text-LLMs learning powerful internal circuits that can be utilized by activating necessary connections for various applications rather than training models from scratch every single time.
Whisper-GPT: A Hybrid Representation Audio Large Language Model
Dec 16, 2024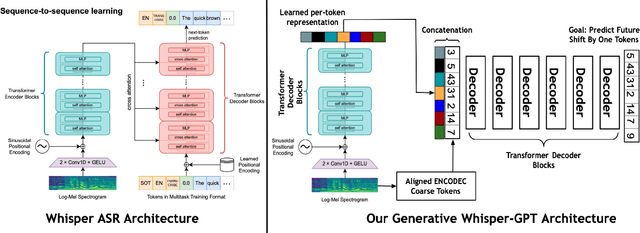
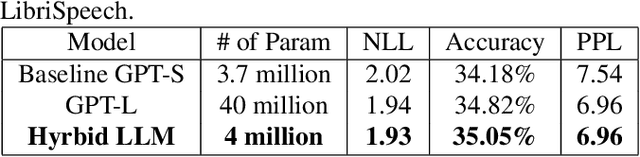
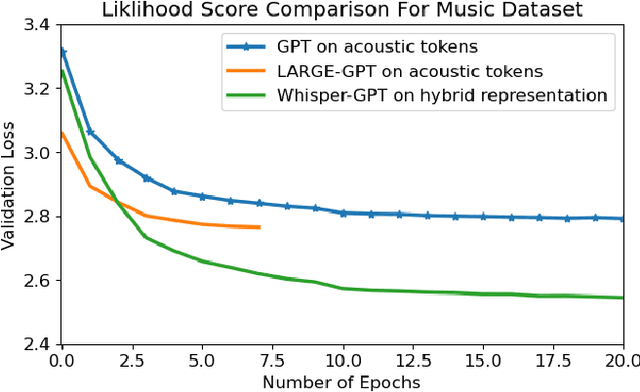
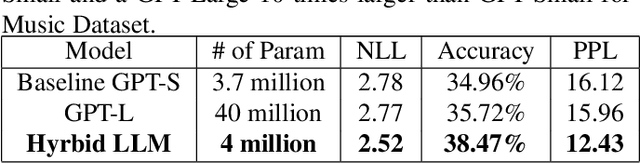
We propose WHISPER-GPT: A generative large language model (LLM) for speech and music that allows us to work with continuous audio representations and discrete tokens simultaneously as part of a single architecture. There has been a huge surge in generative audio, speech, and music models that utilize discrete audio tokens derived from neural compression algorithms, e.g. ENCODEC. However, one of the major drawbacks of this approach is handling the context length. It blows up for high-fidelity generative architecture if one has to account for all the audio contents at various frequencies for the next token prediction. By combining continuous audio representation like the spectrogram and discrete acoustic tokens, we retain the best of both worlds: Have all the information needed from the audio at a specific time instance in a single token, yet allow LLM to predict the future token to allow for sampling and other benefits discrete space provides. We show how our architecture improves the perplexity and negative log-likelihood scores for the next token prediction compared to a token-based LLM for speech and music.
Adaptive Large Language Models By Layerwise Attention Shortcuts
Sep 17, 2024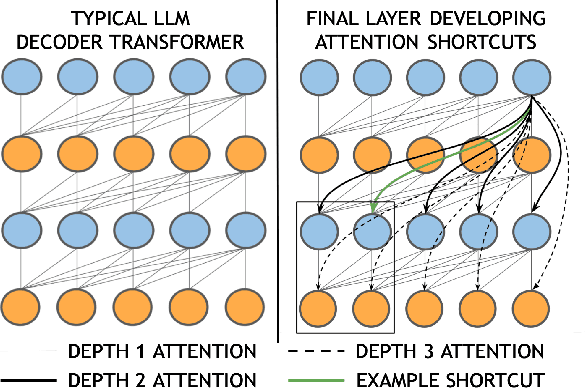
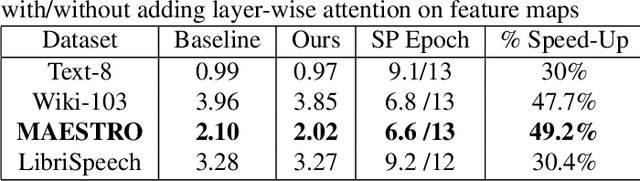
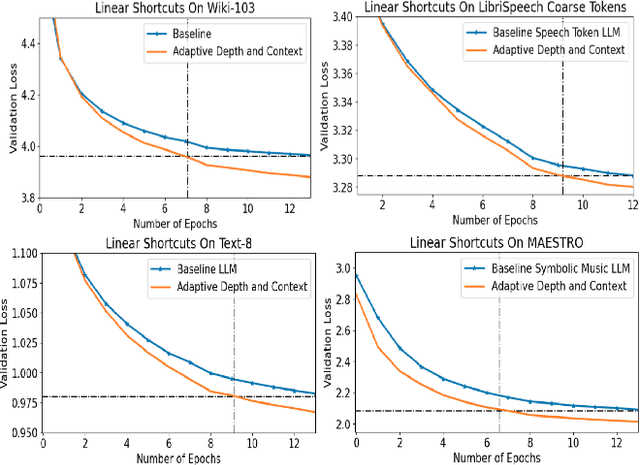

Transformer architectures are the backbone of the modern AI revolution. However, they are based on simply stacking the same blocks in dozens of layers and processing information sequentially from one block to another. In this paper, we propose to challenge this and introduce adaptive computations for LLM-like setups, which allow the final layer to attend to all of the intermediate layers as it deems fit through the attention mechanism, thereby introducing computational \textbf{attention shortcuts}. These shortcuts can thus make the architecture depth and context adaptive. We showcase four different datasets, namely acoustic tokens, natural language, and symbolic music, and we achieve superior performance for GPT-like architecture. We give evidence via attention maps that the models learn complex dependencies across layers that are adaptive in context and depth depending on the input tokens.
Towards Signal Processing In Large Language Models
Jun 10, 2024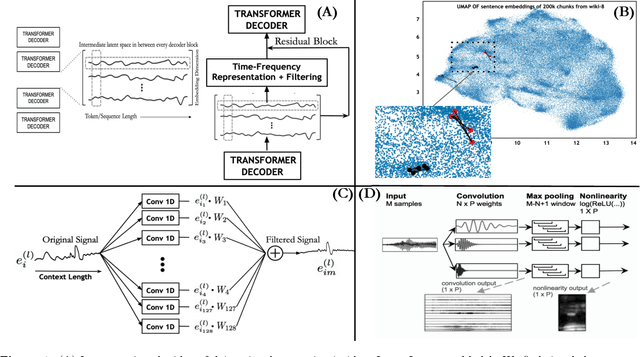
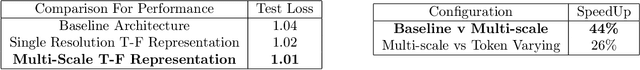
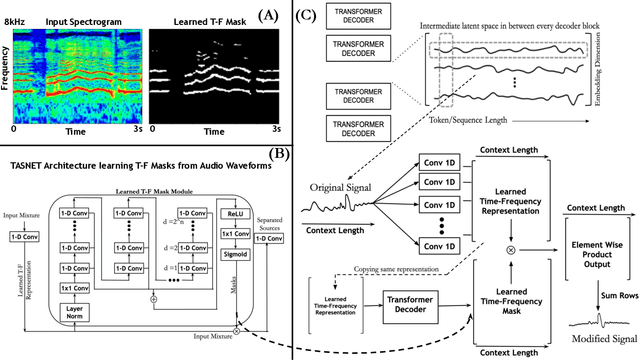
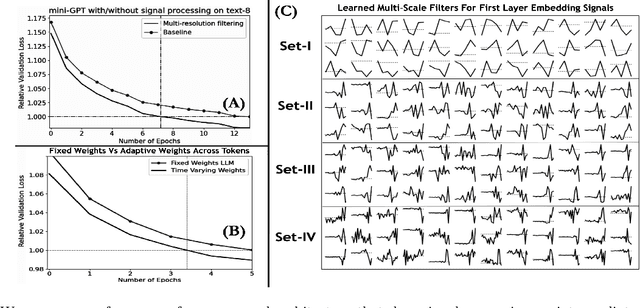
This paper introduces the idea of applying signal processing inside a Large Language Model (LLM). With the recent explosion of generative AI, our work can help bridge two fields together, namely the field of signal processing and large language models. We draw parallels between classical Fourier-Transforms and Fourier Transform-like learnable time-frequency representations for every intermediate activation signal of an LLM. Once we decompose every activation signal across tokens into a time-frequency representation, we learn how to filter and reconstruct them, with all components learned from scratch, to predict the next token given the previous context. We show that for GPT-like architectures, our work achieves faster convergence and significantly increases performance by adding a minuscule number of extra parameters when trained for the same epochs. We hope this work paves the way for algorithms exploring signal processing inside the signals found in neural architectures like LLMs and beyond.
Beyond Human Vision: The Role of Large Vision Language Models in Microscope Image Analysis
May 01, 2024Vision language models (VLMs) have recently emerged and gained the spotlight for their ability to comprehend the dual modality of image and textual data. VLMs such as LLaVA, ChatGPT-4, and Gemini have recently shown impressive performance on tasks such as natural image captioning, visual question answering (VQA), and spatial reasoning. Additionally, a universal segmentation model by Meta AI, Segment Anything Model (SAM) shows unprecedented performance at isolating objects from unforeseen images. Since medical experts, biologists, and materials scientists routinely examine microscopy or medical images in conjunction with textual information in the form of captions, literature, or reports, and draw conclusions of great importance and merit, it is indubitably essential to test the performance of VLMs and foundation models such as SAM, on these images. In this study, we charge ChatGPT, LLaVA, Gemini, and SAM with classification, segmentation, counting, and VQA tasks on a variety of microscopy images. We observe that ChatGPT and Gemini are impressively able to comprehend the visual features in microscopy images, while SAM is quite capable at isolating artefacts in a general sense. However, the performance is not close to that of a domain expert - the models are readily encumbered by the introduction of impurities, defects, artefact overlaps and diversity present in the images.
On Large Visual Language Models for Medical Imaging Analysis: An Empirical Study
Feb 21, 2024Recently, large language models (LLMs) have taken the spotlight in natural language processing. Further, integrating LLMs with vision enables the users to explore emergent abilities with multimodal data. Visual language models (VLMs), such as LLaVA, Flamingo, or CLIP, have demonstrated impressive performance on various visio-linguistic tasks. Consequently, there are enormous applications of large models that could be potentially used in the biomedical imaging field. Along that direction, there is a lack of related work to show the ability of large models to diagnose the diseases. In this work, we study the zero-shot and few-shot robustness of VLMs on the medical imaging analysis tasks. Our comprehensive experiments demonstrate the effectiveness of VLMs in analyzing biomedical images such as brain MRIs, microscopic images of blood cells, and chest X-rays.
Diverse Neural Audio Embeddings -- Bringing Features back !
Sep 15, 2023With the advent of modern AI architectures, a shift has happened towards end-to-end architectures. This pivot has led to neural architectures being trained without domain-specific biases/knowledge, optimized according to the task. We in this paper, learn audio embeddings via diverse feature representations, in this case, domain-specific. For the case of audio classification over hundreds of categories of sound, we learn robust separate embeddings for diverse audio properties such as pitch, timbre, and neural representation, along with also learning it via an end-to-end architecture. We observe handcrafted embeddings, e.g., pitch and timbre-based, although on their own, are not able to beat a fully end-to-end representation, yet adding these together with end-to-end embedding helps us, significantly improve performance. This work would pave the way to bring some domain expertise with end-to-end models to learn robust, diverse representations, surpassing the performance of just training end-to-end models.
Neural Architectures Learning Fourier Transforms, Signal Processing and Much More....
Aug 20, 2023This report will explore and answer fundamental questions about taking Fourier Transforms and tying it with recent advances in AI and neural architecture. One interpretation of the Fourier Transform is decomposing a signal into its constituent components by projecting them onto complex exponentials. Variants exist, such as discrete cosine transform that does not operate on the complex domain and projects an input signal to only cosine functions oscillating at different frequencies. However, this is a fundamental limitation, and it needs to be more suboptimal. The first one is that all kernels are sinusoidal: What if we could have some kernels adapted or learned according to the problem? What if we can use neural architectures for this? We show how one can learn these kernels from scratch for audio signal processing applications. We find that the neural architecture not only learns sinusoidal kernel shapes but discovers all kinds of incredible signal-processing properties. E.g., windowing functions, onset detectors, high pass filters, low pass filters, modulations, etc. Further, upon analysis of the filters, we find that the neural architecture has a comb filter-like structure on top of the learned kernels. Comb filters that allow harmonic frequencies to pass through are one of the core building blocks/types of filters similar to high-pass, low-pass, and band-pass filters of various traditional signal processing algorithms. Further, we can also use the convolution operation with a signal to be learned from scratch, and we will explore papers in the literature that uses this with that robust Transformer architectures. Further, we would also explore making the learned kernel's content adaptive, i.e., learning different kernels for different inputs.