 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhisper-GPT: A Hybrid Representation Audio Large Language Model
Paper and Code
Dec 16, 2024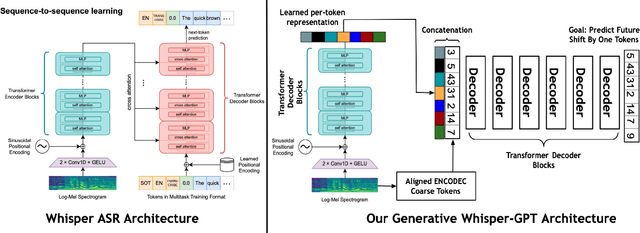
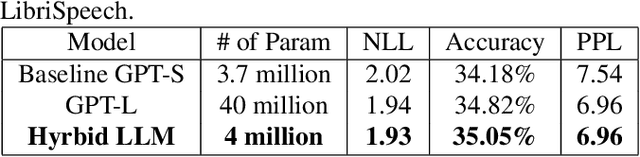
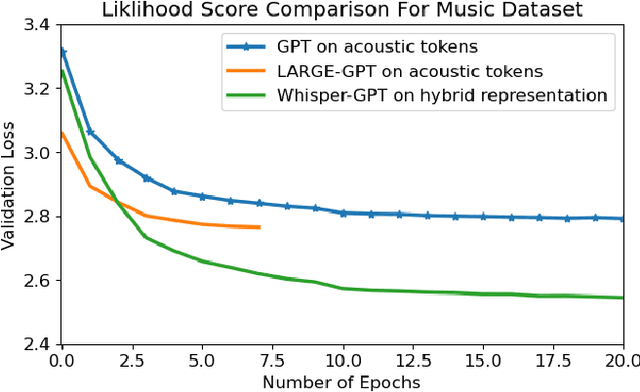
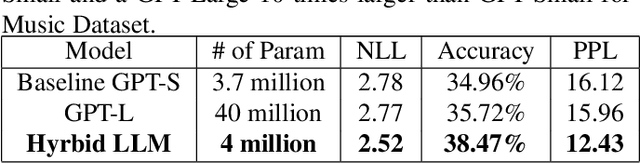
We propose WHISPER-GPT: A generative large language model (LLM) for speech and music that allows us to work with continuous audio representations and discrete tokens simultaneously as part of a single architecture. There has been a huge surge in generative audio, speech, and music models that utilize discrete audio tokens derived from neural compression algorithms, e.g. ENCODEC. However, one of the major drawbacks of this approach is handling the context length. It blows up for high-fidelity generative architecture if one has to account for all the audio contents at various frequencies for the next token prediction. By combining continuous audio representation like the spectrogram and discrete acoustic tokens, we retain the best of both worlds: Have all the information needed from the audio at a specific time instance in a single token, yet allow LLM to predict the future token to allow for sampling and other benefits discrete space provides. We show how our architecture improves the perplexity and negative log-likelihood scores for the next token prediction compared to a token-based LLM for speech and music.